详细内容请看类与类之间六大关系揭秘以及软件设计七大原则 ,设计模式系列文章在同目录下
软件设计原则有哪些?
常⽤的⾯向对象设计原则包括7个,这些原则并不是孤⽴存在的,它们相互依赖,相互补充。
- 开闭原则(Open Closed Principle,OCP):对扩展开放,对修改关闭。在程序需要进行拓展的时候,不能去修改原有的代码,实现一个热插拔的效果
- 单⼀职责原则(Single Responsibility Principle, SRP):一个类、接口、方法只负责一项职责
- ⾥⽒替换原则(Liskov Substitution Principle,LSP):任何基类可以出现的地方,子类一定可以出现。通俗理解:子类可以扩展父类的功能,但不能改变父类原有的功能。换句话说,子类继承父类时,除添加新的方法完成新增功能外,尽量不要重写父类的方法。里氏代换原则是对“开-闭”原则的补充
- 依赖倒置原则(Dependency Inversion Principle,DIP):高层模块不应该依赖低层模块,两者都应该依赖其抽象;抽象不应该依赖细节,细节应该依赖抽象。简单的说就是要求对抽象进行编程,不要对实现进行编程,这样就降低了客户与实现模块间的耦合。依赖倒转原则其实是开闭原则的具体实现
- 接⼝隔离原则(Interface Segregation Principle,ISP):客户端不应该被迫依赖于它不使用的方法;一个类对另一个类的依赖应该建立在最小的接口上。符合我们常说的高内聚低耦合的思想
- 合成/聚合复⽤原则(Composite/Aggregate Reuse Principle,C/ARP):**尽量先使用组合或者聚合等关联关系来实现,其次才考虑使用继承关系来实现
- 最少知识原则(Least Knowledge Principle,LKP)或者迪⽶特法则(Law of Demeter,LOD):如果两个软件实体无须直接通信,那么就不应当发生直接的相互调用,可以通过第三方转发该调用。其目的是降低类之间的耦合度,提高模块的相对独立性。
什么是设计模式?
设计模式(Design pattern)代表了最佳的实践,通常被有经验的⾯向对象的软件开发⼈员所采⽤。设计模式是软件开发⼈员在软件开发过程中⾯临的⼀般问题的解决⽅案。这些解决⽅案是众多软件开发⼈员经过相当⻓的⼀段时间的试验和错误总结出来的。
设计模式是⼀套被反复使⽤的、多数⼈知晓的、经过分类编⽬的、代码设计经验的总结。使⽤设计模式是为了重⽤代码、让代码更容易被他⼈理解、保证代码可靠性。 毫⽆疑问,设计模式于⼰于他⼈于系统都是多赢的,设计模式使代码编制真正⼯程化,设计模式是软件⼯程的基⽯,如同⼤厦的⼀块块砖⽯⼀样。项⽬中合理地运⽤设计模式可以完美地解决很多问题,每种模式在现实中都有相应的原理来与之对应,每种模式都描述了⼀个在我们周围不断重复发⽣的问题,以及该问题的核⼼解决⽅案,这也是设计模式能被⼴泛应⽤的原因。
设计模式的分类了解吗?
创建型: 在创建对象的同时隐藏创建逻辑,不使⽤ new 直接实例化对象,程序在判断需要创建哪些对象时更灵活。包括⼯⼚/抽象⼯⼚/单例/建造者/原型模式。
结构型: 通过类和接⼝间的继承和引⽤实现创建复杂结构的对象。包括适配器/桥接模式/过滤器/组合/装饰器/外观/享元/代理模式。
⾏为型: 通过类之间不同通信⽅式实现不同⾏为。包括责任链/命名/解释器/迭代器/中介者/备忘录/观察者/状态/策略/模板/访问者模式。
⼯⼚模式
说⼀说简单⼯⼚模式
简单⼯⼚模式指由⼀个⼯⼚对象来创建实例,客户端不需要关注创建逻辑,只需提供传⼊⼯⼚的参数。
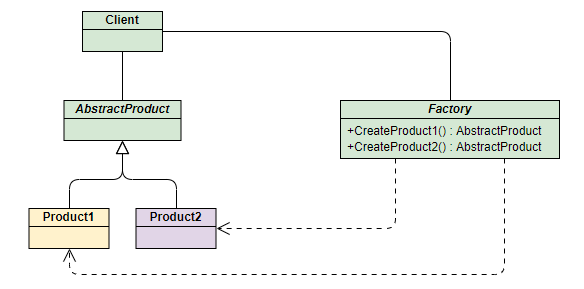
适⽤于⼯⼚类负责创建对象较少的情况,缺点是如果要增加新产品,就需要修改⼯⼚类的判断逻辑,违背开闭原则,且产品多的话会使⼯⼚类⽐较复杂。
- Calendar 抽象类的 getInstance ⽅法,调⽤ createCalendar ⽅法根据不同的地区参数创建不同的⽇历对象。
- Spring 中的 BeanFactory 使⽤简单⼯⼚模式,根据传⼊⼀个唯⼀的标识来获得 Bean 对象。
⼯⼚⽅法模式了解吗?
和简单⼯⼚模式中⼯⼚负责⽣产所有产品相⽐,⼯⼚⽅法模式将⽣成具体产品的任务分发给具体的产品⼯⼚。
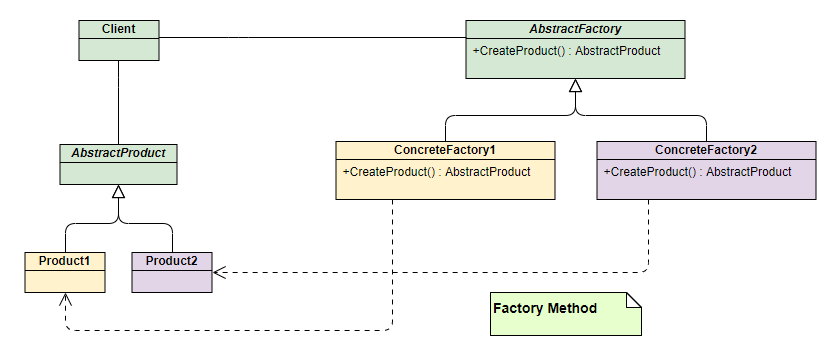
也就是定义⼀个抽象⼯⼚,其定义了产品的⽣产接⼝,但不负责具体的产品,将⽣产任务交给不同的派⽣类⼯⼚。这样不⽤通过指定类型来创建对象了。
抽象⼯⼚模式了解吗?
简单⼯⼚模式和⼯⼚⽅法模式不管⼯⼚怎么拆分抽象,都只是针对⼀类产品,如果要⽣成另⼀种产品,就⽐较难办了!
抽象⼯⼚模式通过在 AbstarctFactory 中增加创建产品的接⼝,并在具体⼦⼯⼚中实现新加产品的创建,当然前提是⼦⼯⼚⽀持⽣产该产品。否则继承的这个接⼝可以什么也不⼲。
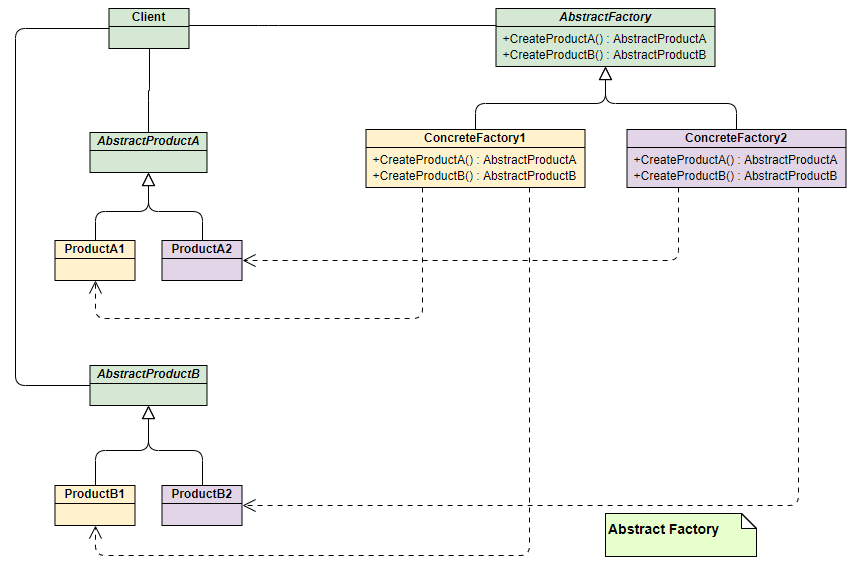
从上⾯类图结构中可以清楚的看到如何在⼯⼚⽅法模式中通过增加新产品接⼝来实现产品的增加的。
单例模式
详情可以看这篇文章:单例模式
什么是单例模式?单例模式的特点是什么?
单例模式属于创建型模式,⼀个单例类在任何情况下都只存在⼀个实例,构造⽅法必须是私有的、由⾃⼰创建⼀个静态变量存储实例,对外提供⼀个静态公有⽅法获取实例。
优点是内存中只有⼀个实例,减少了开销,尤其是频繁创建和销毁实例的情况下并且可以避免对资源的多重占⽤。缺点是没有抽象层,难以扩展,与单⼀职责原则冲突。
单例模式的常⻅写法有哪些?
饿汉式,线程安全
饿汉式单例模式,顾名思义,类⼀加载就创建对象,这种⽅式⽐较常⽤,但容易产⽣垃圾对象,浪费内存空间。
优点:线程安全,没有加锁,执⾏效率较⾼
缺点:不是懒加载,类加载时就初始化,浪费内存空间
懒加载 (lazy loading):使⽤的时候再创建对象
饿汉式单例是如何保证线程安全的呢?它是基于类加载机制避免了多线程的同步问题,但是如果类被不同的类加载器加载就会创建不同的实例。
懒汉式,双重检查锁
通过 synchronized 关键字加锁保证线程安全, synchronized 可以添加在⽅法上⾯,也可以添加在代码块上⾯,这⾥演示添加在⽅法上⾯,存在的问题是每⼀次调⽤ getInstance 获取实例时都需要加锁和释放锁,这样是⾮常影响性能的。
优点:懒加载,线程安全,效率较⾼
缺点:实现较复杂
- 为什么判断两次
instance==null
第一次判断是在代码块前,第二次是进入代码块后,第二个判断想必都知道,多个线程都堵到代码块前等待锁的释放,进入代码块后要获取到最新的instance值,如果为空就进行创建对象。
那么为什么还要进行第一个判断,第一个判断起到优化作用,假设如果instance已经不为空了,那么没有第一个判断仍然会有线程堵在代码块前等待进一步判断,所以如果不为空,有了第一个判断就不用再去进入代码块进行判断,也就不用再去等锁了,直接返回。
- 为什么要加volatile?
是为了防止指令重排序,给私有变量加 volatile 主要是为了防止第 ② 处执行时,也就是“instance = new Singleton()”执行时的指令重排序的,这行代码看似只是一个创建对象的过程,然而它的实际执行却分为以下 3 步:
- 创建内存空间。
- 在内存空间中初始化对象 Singleton。
- 将内存地址赋值给 instance 对象(执行了此步骤,instance 就不等于 null 了)。
试想一下,如果不加 volatile,那么线程A在执行到上述代码的第 ② 处时就可能会执行指令重排序,将原本是 1、2、3 的执行顺序,重排为 1、3、2。但是特殊情况下,线程 A在执行完第 3 步之后,如果来了线程 B执行到上述代码的第 ① 处,判断 instance 对象已经不为 null,但此时线程 A还未将对象实例化完,那么线程B将会得到一个被实例化“一半”的对象,从而导致程序执行出错,这就是为什么要给私有变量添加 volatile 的原因了。
优化作用,synchronized块只有执行完才会同步到主内存,那么比如说instance刚创建完成,不为空,但还没有跳出synchronized块,此时又有10000个线程调用方法,那么如果没有volatile,此使instance在主内存中仍然为空,这一万个线程仍然要通过第一次判断,进入代码块前进行等待,正是有了volatile,一旦instance改变,那么便会同步到主内存,即使没有出synchronized块,instance仍然同步到了主内存,通过不了第一个判断也就避免了新加的10000个线程进入去争取锁。
静态内部类
优点:懒加载,线程安全,效率较⾼,实现简单
静态内部类单例是如何实现懒加载的呢?⾸先,我们先了解下类的加载时机。
虚拟机规范要求有且只有 5 种情况必须⽴即对类进⾏初始化(加载、验证、准备需要在此之前开始):
- 遇到 new 、getstatic 、putstatic 、invokestatic 这 4 条字节码指令时。⽣成这 4 条指令最常⻅的 Java 代码场景是:使⽤ new 关键字实例化对象的时候、读取或设置⼀个类的静态字段(final 修饰除外,被final 修饰的静态字段是常量,已在编译期把结果放⼊常量池)的时候,以及调⽤⼀个类的静态⽅法的时候。
- 使⽤ java.lang.reflect 包⽅法对类进⾏反射调⽤的时候。
- 当初始化⼀个类的时候,如果发现其⽗类还没有进⾏过初始化,则需要先触发其⽗类的初始化。
- 当虚拟机启动时,⽤户需要指定⼀个要执⾏的主类(包含 main()的那个类),虚拟机会先初始化这个主类。
- 当使⽤ JDK 1.7 的动态语⾔⽀持时,如果⼀个java.lang.invoke.MethodHandle 实例最后的解析结果是REF_getStatic 、REF_putStatic 、REF_invokeStatic 的⽅法句柄,则需要先触发这个⽅法句柄所对应的类的初始化。
这 5 种情况被称为是类的主动引⽤,注意,这⾥《虚拟机规范》中使⽤的限定词是 "有且仅有",那么,除此之外的所有引⽤类都不会对类进⾏初始化,称为被动引⽤。静态内部类就属于被动引⽤的情况。当 getInstance()⽅法被调⽤时,InnerClass 才在 Singleton 的运⾏时常量池⾥,把符号引⽤替换为直接引⽤,这时静态对象 INSTANCE 也真正被创建,然后再被 getInstance()⽅法返回出去,这点同饿汉模式。
枚举单例
优点:简单,⾼效,线程安全,可以避免通过反射破坏枚举单例
枚举在 java 中与普通类⼀样,都能拥有字段与⽅法,⽽且枚举实例创建是线程安全的,在任何情况下,它都是⼀个单例
通过反射可以破坏所有含有无参构造器的单例类,如可以破坏懒汉式、饿汉式、静态内部类的单例模式。但是反射无法破坏通过枚举实现的单例模式,利用反射构造新的对象,由于 enum 没有无参构造器,结果会抛出 NoSuchMethodException 异常。具体可以看这篇文章 单例模式
适配器模式
适配器模式了解吗?
在我们的应⽤程序中我们可能需要将两个不同接⼝的类来进⾏通信,在不修改这两个的前提下我们可能会需要某个中间件来完成这个衔接的过程。这个中间件就是适配器。所谓适配器模式就是将⼀个类的接⼝,转换成客户期望的另⼀个接⼝。它可以让原本两个不兼容的接⼝能够⽆缝完成对接。
作为中间件的适配器将⽬标类和适配者解耦,增加了类的透明性和可复⽤性。
类适配器
原理:通过类继承实现适配,继承 Target 的接⼝,继承 Adaptee 的实现
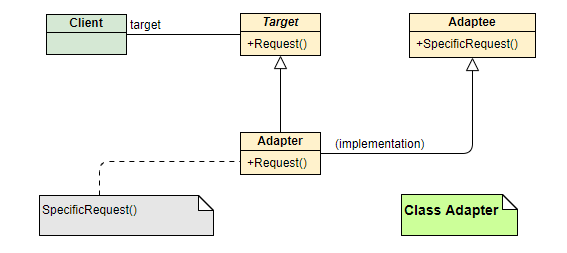
对象适配器
原理:通过类对象组合实现适配
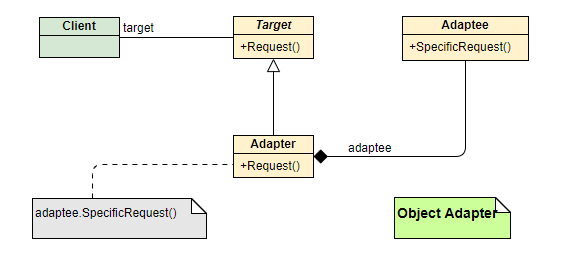
- Target: 定义 Client 真正需要使⽤的接⼝。
- Adaptee: 其中定义了⼀个已经存在的接⼝,也是我们需要进⾏适配的接⼝。
- Adapter: 对 Adaptee 和 Target 的接⼝进⾏适配,保证对 target 中接⼝的调⽤可以间接转换为对 Adaptee 中接⼝进⾏调⽤。
适配器模式的优缺点
优点:
- 提⾼了类的复⽤;
- 组合若⼲关联对象形成对外提供统⼀服务的接⼝;
- 扩展性、灵活性好。
缺点:
- 过多使⽤适配模式容易造成代码功能和逻辑意义的混淆。
- 部分语⾔对继承的限制,可能⾄多只能适配⼀个适配者类,⽽且⽬标类必须是抽象类。
代理模式(proxy pattern)
什么是代理模式?
代理模式的本质是⼀个中间件,主要⽬的是解耦合服务提供者和使⽤者。使⽤者通过代理间接的访问服务提供者,便于后者的封装和控制。是⼀种结构性模式。
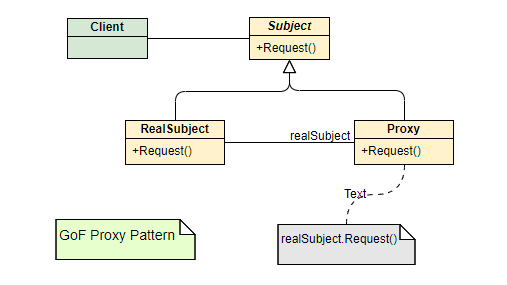
- Subject: 定义 RealSubject 对外的接⼝,且这些接⼝必须被 Proxy 实现,这样外部调⽤ proxy 的接⼝最终都被转化为对 realsubject 的调⽤。
- RealSubject: 真正的⽬标对象。
- Proxy: ⽬标对象的代理,负责控制和管理⽬标对象,并间接地传递外部对⽬标对象的访问。
- Remote Proxy: 对本地的请求以及参数进⾏序列化,向远程对象发送请求,并对响应结果进⾏反序列化,将最终结果反馈给调⽤者;
- Virtual Proxy: 当⽬标对象的创建开销⽐较⼤的时候,可以使⽤延迟或者异步的⽅式创建⽬标对象;
- Protection Proxy: 细化对⽬标对象访问权限的控制;
静态代理和动态代理的区别
- 灵活性 :动态代理更加灵活,不需要必须实现接⼝,可以直接代理实现类,并且可以不需要针对每个⽬标类都创建⼀个代理类。另外,静态代理中,接⼝⼀旦新增加⽅法,⽬标对象和代理对象都要进⾏修改,这是⾮常麻烦的!
- JVM 层⾯ :静态代理在编译时就将接⼝、实现类、代理类这些都变成了⼀个个实际的 class ⽂件。⽽动态代理是在运⾏时动态⽣成类字节码,并加载到 JVM 中的。
观察者模式
说⼀说观察者模式
观察者模式主要⽤于处理对象间的⼀对多的关系,是⼀种对象⾏为模式。该模式的实际应⽤场景⽐较容易确认,当⼀个对象状态发⽣变化时,所有该对象的关注者均能收到状态变化通知,以进⾏相应的处理。
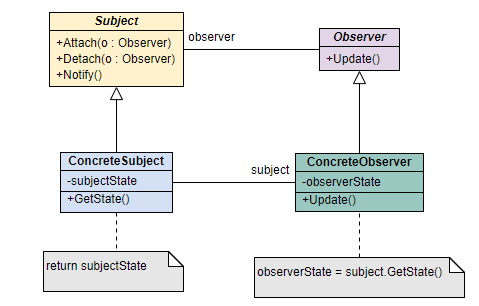
- Subject: 抽象被观察者,仅提供注册和删除观察者对象的接⼝声明。
- ConcreteSubject: 具体被观察者对象,该对象中收集了所有需要被通知的观察者,并可以动态的增删集合中的观察者。当其状态发⽣变化时会通知所有观察者对象。
- Observer: 抽象观察者,为所有观察者定义获得通知的统⼀接⼝;
- ConcreteObserver: 观察者对象,其关注对象为 Subject,能接受 Subject变化时发出的通知并更新⾃身状态。
观察者模式的优缺点
优点:
- 被观察者和观察者之间是抽象耦合的;
- 耦合度较低,两者之间的关联仅仅在于消息的通知;
- 被观察者⽆需关⼼他的观察者;
- ⽀持⼴播通信;
缺点:
- 观察者只知道被观察对象发⽣了变化,但不知变化的过程和缘由;
- 观察者同时也可能是被观察者,消息传递的链路可能会过⻓,完成所有通知花费时间较多;
- 如果观察者和被观察者之间产⽣循环依赖,或者消息传递链路形成闭环,会导致⽆限循环;
你的项⽬是怎么⽤的观察者模式?
在⽀付场景下,⽤户购买⼀件商品,当⽀付成功之后三⽅会回调⾃身,在这个时候系统可能会有很多需要执⾏的逻辑(如:更新订单状态,发送邮件通知,赠送礼品…),这些逻辑之间并没有强耦合,因此天然适合使⽤观察者模式去实现这些功能,当有更多的操作时,只需要添加新的观察者就能实现,完美实现了对修改关闭,对扩展开放的开闭原则。
装饰器模式
什么是装饰器模式?
装饰器模式主要对现有的类对象进⾏包裹和封装,以期望在不改变类对象及其类定义的情况下,为对象添加额外功能。是⼀种对象结构型模式。需要注意的是,该过程是通过调⽤被包裹之后的对象完成功能添加的,⽽不是直接修改现有对象的⾏为,相当于增加了中间层。
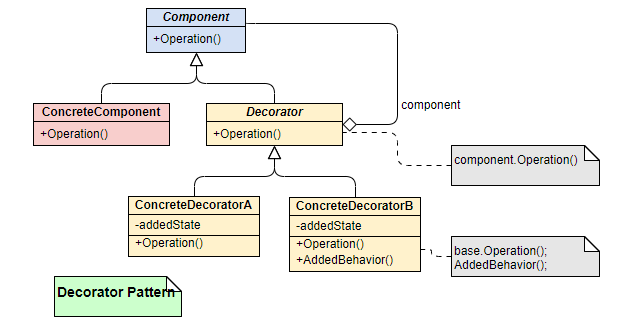
- Component: 对象的接⼝类,定义装饰对象和被装饰对象的共同接⼝;
- ConcreteComponent: 被装饰对象的类定义;
- Decorator: 装饰对象的抽象类,持有⼀个具体的被修饰对象,并实现接⼝类继承的公共接⼝;
- ConcreteDecorator: 具体的装饰器,负责往被装饰对象添加额外的功能;
讲讲装饰器模式的应⽤场景
如果你希望在⽆需修改代码的情况下即可使⽤对象, 且希望在运⾏时为对象新增额外的⾏为, 可以使⽤装饰模式。装饰能将业务逻辑组织为层次结构, 你可为各层创建⼀个装饰, 在运⾏时将各种不同逻辑组合成对象。 由于这些对象都遵循通⽤接⼝, 客户端代码能以相同的⽅式使⽤这些对象。
如果⽤继承来扩展对象⾏为的⽅案难以实现或者根本不可⾏, 你可以使⽤该模式。许多编程语⾔使⽤ final 最终关键字来限制对某个类的进⼀步扩展。 复⽤最终类已有⾏为的唯⼀⽅法是使⽤装饰模式: ⽤封装器对其进⾏封装。
责任链模式
什么是责任链模式?
⼀个请求沿着⼀条“链”传递,直到该“链”上的某个处理者处理它为⽌。⼀个请求可以被多个处理者处理或处理者未明确指定时。
责任链模式⾮常简单异常好理解,相信我它⽐单例模式还简单易懂,其应⽤也⼏乎⽆所不在,甚⾄可以这么说,从你敲代码的第⼀天起你就不知不觉⽤过了它最原始的裸体结构: switch-case 语句。
讲讲责任链模式的应⽤场景
当程序需要使⽤不同⽅式处理不同种类请求, ⽽且请求类型和顺序预先未知时, 可以使⽤责任链模式。该模式能将多个处理者连接成⼀条
链。 接收到请求后, 它会 “询问” 每个处理者是否能够对其进⾏处理。这样所有处理者都有机会来处理请求。
当必须按顺序执⾏多个处理者时, 可以使⽤该模式。 ⽆论你以何种顺序将处理者连接成⼀条链, 所有请求都会严格按照顺序通过链上的处理者。
策略模式
什么是策略模式?
策略模式(Strategy Pattern)属于对象的⾏为模式。其⽤意是针对⼀组算法,将每⼀个算法封装到具有共同接⼝的独⽴的类中,从⽽使得它们可以相互替换。策略模式使得算法可以在不影响到客户端的情况下发⽣变化。其主要⽬的是通过定义相似的算法,替换 if else 语句写法,并且可以随时相互替换。
策略模式有什么好处?
定义了⼀系列封装了算法、⾏为的对象,他们可以相互替换。
举例: Java.util.List 就是定义了⼀个增( add )、删( remove )、改( set )、查( indexOf )策略,⾄于实现这个策略的ArrayList 、LinkedList 等类,只是在具体实现时采⽤了不同的算法。但因为它们策略⼀样,不考虑速度的情况下,使⽤时完全可以互相替换使⽤。
Spring用到了哪些设计模式
JDK 使⽤了哪些设计模式?
桥接模式
这个模式将抽象和抽象操作的实现进⾏了解耦,这样使得抽象和实现可以独⽴地变化。
GOF 在提出桥梁模式的时候指出,桥梁模式的⽤意是”将抽象化(Abstraction)与实现化(Implementation)脱耦,使得⼆者可以独⽴地变化”。这句话有三个关键词,也就是抽象化、实现化和脱耦。
在 Java 应⽤中,对于桥接模式有⼀个⾮常典型的例⼦,就是应⽤程序使⽤JDBC 驱动程序进⾏开发的⽅式。所谓驱动程序,指的是按照预先约定好的接⼝来操作计算机系统或者是外围设备的程序。
适配器模式
⽤来把⼀个接⼝转化成另⼀个接⼝。使得原本由于接⼝不兼容⽽不能⼀起⼯作的那些类可以在⼀起⼯作。
java.util.Arrays#asList()
java.io.InputStreamReader(InputStream)
java.io.OutputStreamWriter(OutputStream)- 举例:InputStreamReader
Reader(字符流)、InputStream(字节流)的适配使用的是InputStreamReader。
InputStreamReader继承自java.io包中的Reader,对他中的抽象的未实现的方法给出实现。如:
public int read() throws IOException {
return sd.read();
}
public int read(char cbuf[], int offset, int length) throws IOException {
return sd.read(cbuf, offset, length);
}如上代码中的sd(StreamDecoder类对象),在Sun的JDK实现中,实际的方法实现是对sun.nio.cs.StreamDecoder类的同名方法的调用封装。类结构图如下:
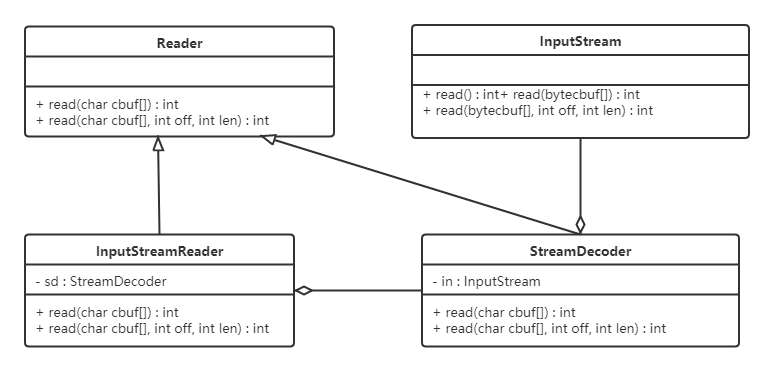
从上图可以看出:
InputStreamReader是对同样实现了Reader的StreamDecoder的封装。
StreamDecoder不是Java SE API中的内容,是Sun JDK给出的自身实现。但我们知道他们对构造方法中的字节流类(InputStream)进行封装,并通过该类进行了字节流和字符流之间的解码转换。
结论:从表层来看,InputStreamReader做了InputStream字节流类到Reader字符流之间的转换。而从如上Sun JDK中的实现类关系结构中可以看出,是StreamDecoder的设计实现在实际上采用了适配器模式。
组合模式
⼜叫做部分-整体模式,使得客户端看来单个对象和对象的组合是同等的。换句话说,某个类型的⽅法同时也接受⾃身类型作为参数。
java.util.Map#putAll(Map)
java.util.List#addAll(Collection)
java.util.Set#addAll(Collection)装饰者模式
动态的给⼀个对象附加额外的功能,这也是⼦类的⼀种替代⽅式。可以看到,在创建⼀个类型的时候,同时也传⼊同⼀类型的对象。这在 JDK ⾥随处可⻅,你会发现它⽆处不在,所以下⾯这个列表只是⼀⼩部分。
java.io.BufferedInputStream(InputStream)
java.io.DataInputStream(InputStream)
java.io.BufferedOutputStream(OutputStream)
java.util.zip.ZipOutputStream(OutputStream)
java.util.Collections#checkedList|Map|Set|SortedSet|SortedMap- 举例-IO流包装类
IO流中的包装类使用到了装饰者模式。BufferedInputStream,BufferedOutputStream,BufferedReader,BufferedWriter。
我们以BufferedWriter举例来说明,先看看如何使用BufferedWriter
public class Demo {
public static void main(String[] args) throws Exception{
//创建BufferedWriter对象
//创建FileWriter对象
FileWriter fw = new FileWriter("C:\\Users\\Think\\Desktop\\a.txt");
BufferedWriter bw = new BufferedWriter(fw);
//写数据
bw.write("hello Buffered");
bw.close();
}
}使用起来感觉确实像是装饰者模式,接下来看它们的结构:
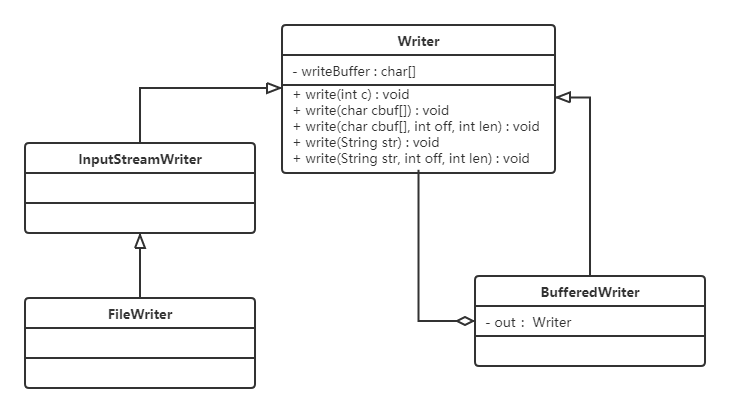
小结:BufferedWriter使用装饰者模式对Writer子实现类进行了增强,添加了缓冲区,提高了写数据的效率。
享元模式
使⽤缓存来加速⼤量⼩对象的访问时间。
java.lang.Integer#valueOf(int)
java.lang.Boolean#valueOf(boolean)
java.lang.Byte#valueOf(byte)
java.lang.Character#valueOf(char)- 举例-Integer
Integer类使用了享元模式。我们先看下面的例子:
public class Demo {
public static void main(String[] args) {
Integer i1 = 127;
Integer i2 = 127;
System.out.println("i1和i2对象是否是同一个对象?" + (i1 == i2));
Integer i3 = 128;
Integer i4 = 128;
System.out.println("i3和i4对象是否是同一个对象?" + (i3 == i4));
}
}运行上面代码,结果如下:

为什么第一个输出语句输出的是true,第二个输出语句输出的是false?通过反编译软件进行反编译,代码如下:
public class Demo {
public static void main(String[] args) {
Integer i1 = Integer.valueOf((int)127);
Integer i2 Integer.valueOf((int)127);
System.out.println((String)new StringBuilder().append((String)"i1\u548ci2\u5bf9\u8c61\u662f\u5426\u662f\u540c\u4e00\u4e2a\u5bf9\u8c61\uff1f").append((boolean)(i1 == i2)).toString());
Integer i3 = Integer.valueOf((int)128);
Integer i4 = Integer.valueOf((int)128);
System.out.println((String)new StringBuilder().append((String)"i3\u548ci4\u5bf9\u8c61\u662f\u5426\u662f\u540c\u4e00\u4e2a\u5bf9\u8c61\uff1f").append((boolean)(i3 == i4)).toString());
}
}上面代码可以看到,直接给Integer类型的变量赋值基本数据类型数据的操作底层使用的是 valueOf() ,所以只需要看该方法即可
public final class Integer extends Number implements Comparable<Integer> {
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer cache[];
static {
int h = 127;
String integerCacheHighPropValue =
sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
int i = parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
} catch( NumberFormatException nfe) {
}
}
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
// range [-128, 127] must be interned (JLS7 5.1.7)
assert IntegerCache.high >= 127;
}
private IntegerCache() {}
}
}可以看到 Integer 默认先创建并缓存 -128 ~ 127 之间数的 Integer 对象,当调用 valueOf 时如果参数在 -128 ~ 127 之间则计算下标并从缓存中返回,否则创建一个新的 Integer 对象。
代理模式
代理模式是⽤⼀个简单的对象来代替⼀个复杂的或者创建耗时的对象。
java.lang.reflect.Proxy抽象⼯⼚模式
抽象⼯⼚模式提供了⼀个协议来⽣成⼀系列的相关或者独⽴的对象,⽽不⽤指定具体对象的类型。它使得应⽤程序能够和使⽤的框架的具体实现进⾏解耦。这在 JDK 或者许多框架⽐如 Spring 中都随处可⻅。它们也很容易识别,⼀个创建新对象的⽅法,返回的却是接⼝或者抽象类的,就是抽象⼯⼚模式了。
java.util.Calendar#getInstance()
java.util.Arrays#asList()
java.util.ResourceBundle#getBundle()
java.sql.DriverManager#getConnection()
java.sql.Connection#createStatement()
java.sql.Statement#executeQuery()
java.text.NumberFormat#getInstance()
javax.xml.transform.TransformerFactory#newInstance()建造者模式
定义了⼀个新的类来构建另⼀个类的实例,以简化复杂对象的创建。建造模式通常也使⽤⽅法链接来实现。
java.lang.StringBuilder#append()
java.lang.StringBuffer#append()
java.sql.PreparedStatement
javax.swing.GroupLayout.Group#addComponent()⼯⼚⽅法
就是⼀个返回具体对象的⽅法。
java.lang.Proxy#newProxyInstance()
java.lang.Object#toString()
java.lang.Class#newInstance()
java.lang.reflect.Array#newInstance()
java.lang.reflect.Constructor#newInstance()
java.lang.Boolean#valueOf(String)
java.lang.Class#forName()- 举例-Collection.iterator方法
public class Demo {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("令狐冲");
list.add("风清扬");
list.add("任我行");
//获取迭代器对象
Iterator<String> it = list.iterator();
//使用迭代器遍历
while(it.hasNext()) {
String ele = it.next();
System.out.println(ele);
}
}
}对上面的代码大家应该很熟,使用迭代器遍历集合,获取集合中的元素。而单列集合获取迭代器的方法就使用到了工厂方法模式。我们看通过类图看看结构:

Collection接口是抽象工厂类,ArrayList是具体的工厂类;Iterator接口是抽象商品类,ArrayList类中的Iter内部类是具体的商品类。在具体的工厂类中iterator()方法创建具体的商品类的对象。
原型模式
使得类的实例能够⽣成⾃身的拷⻉。如果创建⼀个对象的实例⾮常复杂且耗时时,就可以使⽤这种模式,⽽不重新创建⼀个新的实例,你可以拷⻉⼀个对象并直接修改它。
java.lang.Object#clone()
java.lang.Cloneable单例模式
⽤来确保类只有⼀个实例。Joshua Bloch 在 Effetive Java 中建议到,还有⼀种⽅法就是使⽤枚举。
java.lang.Runtime#getRuntime()
java.awt.Toolkit#getDefaultToolkit()
java.awt.GraphicsEnvironment#getLocalGraphicsEnvironment()
java.awt.Desktop#getDesktop()- 举例-Runtime类
Runtime类就是使用的单例设计模式。
public class Runtime {
private static Runtime currentRuntime = new Runtime();
/**
* Returns the runtime object associated with the current Java application.
* Most of the methods of class <code>Runtime</code> are instance
* methods and must be invoked with respect to the current runtime object.
*
* @return the <code>Runtime</code> object associated with the current
* Java application.
*/
public static Runtime getRuntime() {
return currentRuntime;
}
/** Don't let anyone else instantiate this class */
private Runtime() {}
...
}可以看出Runtime类使用的是饿汉式(静态属性)方式来实现单例模式的。
责任链模式
通过把请求从⼀个对象传递到链条中下⼀个对象的⽅式,直到请求被处理完毕,以实现对象间的解耦。
java.util.logging.Logger#log()
javax.servlet.Filter#doFilter()命令模式
将操作封装到对象内,以便存储,传递和返回。
java.lang.Runnable
javax.swing.Action- 举例-Runable
Runable是一个典型命令模式,Runnable担当命令的角色,Thread充当的是调用者,start方法就是其执行方法
//命令接口(抽象命令角色)
public interface Runnable {
public abstract void run();
}
//调用者
public class Thread implements Runnable {
private Runnable target;
public synchronized void start() {
if (threadStatus != 0)
throw new IllegalThreadStateException();
group.add(this);
boolean started = false;
try {
start0();
started = true;
} finally {
try {
if (!started) {
group.threadStartFailed(this);
}
} catch (Throwable ignore) {
}
}
}
private native void start0();
}会调用一个native方法start0(),调用系统方法,开启一个线程。而接收者是对程序员开放的,可以自己定义接收者。
/**
* jdk Runnable 命令模式
* TurnOffThread : 属于具体
*/
public class TurnOffThread implements Runnable{
private Receiver receiver;
public TurnOffThread(Receiver receiver) {
this.receiver = receiver;
}
public void run() {
receiver.turnOFF();
}
}/**
* 测试类
*/
public class Demo {
public static void main(String[] args) {
Receiver receiver = new Receiver();
TurnOffThread turnOffThread = new TurnOffThread(receiver);
Thread thread = new Thread(turnOffThread);
thread.start();
}
}解释器模式
这个模式通常定义了⼀个语⾔的语法,然后解析相应语法的语句。
java.util.Pattern
java.text.Normalizer
java.text.Format迭代器模式
提供⼀个⼀致的⽅法来顺序访问集合中的对象,这个⽅法与底层的集合的具体实现⽆关。
java.util.Iterator
java.util.Enumeration- 举例-Iterator
迭代器模式在JAVA的很多集合类中被广泛应用,接下来看看JAVA源码中是如何使用迭代器模式的。
List<String> list = new ArrayList<>();
Iterator<String> iterator = list.iterator(); //list.iterator()方法返回的肯定是Iterator接口的子实现类对象
while (iterator.hasNext()) {
System.out.println(iterator.next());
}看完这段代码是不是很熟悉,与我们上面代码基本类似。单列集合都使用到了迭代器,我们以ArrayList举例来说明
List:抽象聚合类
ArrayList:具体的聚合类
Iterator:抽象迭代器
list.iterator():返回的是实现了 Iterator 接口的具体迭代器对象
具体的来看看 ArrayList的代码实现
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
public Iterator<E> iterator() {
return new Itr();
}
private class Itr implements Iterator<E> {
int cursor; // 下一个要返回元素的索引
int lastRet = -1; // 上一个返回元素的索引
int expectedModCount = modCount;
Itr() {}
//判断是否还有元素
public boolean hasNext() {
return cursor != size;
}
//获取下一个元素
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
...
}这部分代码还是比较简单,大致就是在 iterator 方法中返回了一个实例化的 Iterator 对象。Itr是一个内部类,它实现了 Iterator 接口并重写了其中的抽象方法。
注意: 当我们在使用JAVA开发的时候,想使用迭代器模式的话,只要让我们自己定义的容器类实现java.util.Iterable并实现其中的iterator()方法使其返回一个 java.util.Iterator 的实现类就可以了。
中介者模式
通过使⽤⼀个中间对象来进⾏消息分发以及减少类之间的直接依赖。
java.util.Timer
java.util.concurrent.Executor#execute()
java.util.concurrent.ExecutorService#submit()
java.lang.reflect.Method#invoke()备忘录模式
⽣成对象状态的⼀个快照,以便对象可以恢复原始状态⽽不⽤暴露⾃身的内容。 Date 对象通过⾃身内部的⼀个 long 值来实现备忘录模式。
java.util.Date
java.io.Serializable观察者模式
它使得⼀个对象可以灵活的将消息发送给感兴趣的对象。
java.util.EventListener
javax.servlet.http.HttpSessionBindingListener
javax.servlet.http.HttpSessionAttributeListener
javax.faces.event.PhaseListener状态模式
通过改变对象内部的状态,使得你可以在运⾏时动态改变⼀个对象的⾏为。
java.util.Iterator
javax.faces.lifecycle.LifeCycle#execute()策略模式
使⽤这个模式来将⼀组算法封装成⼀系列对象。通过传递这些对象可以灵活的改变程序的功能。
java.util.Comparator#compare()
javax.servlet.http.HttpServlet
javax.servlet.Filter#doFilter()- 举例-Comparator
Comparator 中的策略模式。在Arrays类中有一个 sort() 方法,如下:
public class Arrays{
public static <T> void sort(T[] a, Comparator<? super T> c) {
if (c == null) {
sort(a);
} else {
if (LegacyMergeSort.userRequested)
legacyMergeSort(a, c);
else
TimSort.sort(a, 0, a.length, c, null, 0, 0);
}
}
}Arrays就是一个环境角色类,这个sort方法可以传一个新策略让Arrays根据这个策略来进行排序。就比如下面的测试类。
public class demo {
public static void main(String[] args) {
Integer[] data = {12, 2, 3, 2, 4, 5, 1};
// 实现降序排序
Arrays.sort(data, new Comparator<Integer>() {
public int compare(Integer o1, Integer o2) {
return o2 - o1;
}
});
System.out.println(Arrays.toString(data)); //[12, 5, 4, 3, 2, 2, 1]
}
}这里我们在调用Arrays的sort方法时,第二个参数传递的是Comparator接口的子实现类对象。所以Comparator充当的是抽象策略角色,而具体的子实现类充当的是具体策略角色。环境角色类(Arrays)应该持有抽象策略的引用来调用。那么,Arrays类的sort方法到底有没有使用Comparator子实现类中的 compare() 方法吗?让我们继续查看TimSort类的 sort() 方法,代码如下:
class TimSort<T> {
static <T> void sort(T[] a, int lo, int hi, Comparator<? super T> c,
T[] work, int workBase, int workLen) {
assert c != null && a != null && lo >= 0 && lo <= hi && hi <= a.length;
int nRemaining = hi - lo;
if (nRemaining < 2)
return; // Arrays of size 0 and 1 are always sorted
// If array is small, do a "mini-TimSort" with no merges
if (nRemaining < MIN_MERGE) {
int initRunLen = countRunAndMakeAscending(a, lo, hi, c);
binarySort(a, lo, hi, lo + initRunLen, c);
return;
}
...
}
private static <T> int countRunAndMakeAscending(T[] a, int lo, int hi,Comparator<? super T> c) {
assert lo < hi;
int runHi = lo + 1;
if (runHi == hi)
return 1;
// Find end of run, and reverse range if descending
if (c.compare(a[runHi++], a[lo]) < 0) { // Descending
while (runHi < hi && c.compare(a[runHi], a[runHi - 1]) < 0)
runHi++;
reverseRange(a, lo, runHi);
} else { // Ascending
while (runHi < hi && c.compare(a[runHi], a[runHi - 1]) >= 0)
runHi++;
}
return runHi - lo;
}
}上面的代码中最终会跑到 countRunAndMakeAscending() 这个方法中。我们可以看见,只用了compare方法,所以在调用Arrays.sort方法只传具体compare重写方法的类对象就行,这也是Comparator接口中必须要子类实现的一个方法。
模板⽅法模式
让⼦类可以重写⽅法的⼀部分,⽽不是整个重写,你可以控制⼦类需要重写那些操作。
java.util.Collections#sort()
java.io.InputStream#skip()
java.io.InputStream#read()
java.util.AbstractList#indexOf()- 举例-InputStream
InputStream类就使用了模板方法模式。在InputStream类中定义了多个 read() 方法,如下:
public abstract class InputStream implements Closeable {
//抽象方法,要求子类必须重写
public abstract int read() throws IOException;
public int read(byte b[]) throws IOException {
return read(b, 0, b.length);
}
public int read(byte b[], int off, int len) throws IOException {
if (b == null) {
throw new NullPointerException();
} else if (off < 0 || len < 0 || len > b.length - off) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return 0;
}
int c = read(); //调用了无参的read方法,根本调用的是子类的实现。该方法是每次读取一个字节数据
if (c == -1) {
return -1;
}
b[off] = (byte)c;
int i = 1;
try {
for (; i < len ; i++) {
c = read();
if (c == -1) {
break;
}
b[off + i] = (byte)c;
}
} catch (IOException ee) {
}
return i;
}
}从上面代码可以看到,无参的 read() 方法是抽象方法,要求子类必须实现。而 read(byte b[]) 方法调用了 read(byte b[], int off, int len) 方法,所以在此处重点看的方法是带三个参数的方法。
在该方法中第18行、27行,可以看到调用了无参的抽象的 read() 方法。
总结如下: 在InputStream父类中已经定义好了读取一个字节数组数据的方法是每次读取一个字节,并将其存储到数组的第一个索引位置,读取len个字节数据。具体如何读取一个字节数据呢?由子类实现。
访问者模式
提供⼀个⽅便的可维护的⽅式来操作⼀组对象。它使得你在不改变操作的对象前提下,可以修改或者扩展对象的⾏为。
javax.lang.model.element.Element and
javax.lang.model.element.ElementVisitor
javax.lang.model.type.TypeMirror and
javax.lang.model.type.TypeVisitor