这段时间各种AI名词一波接一波的冲击着我的屏幕,Agent,MCP,FunctionCalling,Skill,RAG,它们都是什么东西?
有人说Agent是智能体,那智能体又是什么呢?
有人说MCP是AI时代的USB协议,那么它可以接U盘吗?
它们到底都是什么意思?
Prompt
2023年,OpenAI则刚发布GPT的时候,Al看起来只是一个聊天框。

我们通过聊天框发送一条消息给AI模型,然后AI模型生成一个回复,我们发的消息就叫 User Prompt,也就是用户提示词,一般就是我们提出的问题或者想说的话。
但是现实生活中,当我们和不同人聊天时,即便是完全相同的话,对方也会根据自己的经验给出不同的答案。
比如我说我肚子疼,我妈可能会问我要不要去医院,我爸可能会让我去厕所,我女朋友可能直接就来一句: 滚一边去,老娘也疼。
但是AI并没有这样的人设,所以他就只能给出一个通用的四平八稳的回答,显得非常无趣。于是我们就希望给AI也加上人设。
最直接的方法就是把人设信息和用户要说的话,打包成一条User Prompt发过去。比如你演我的女朋友,我说我肚子疼,然后AI就可能回复:滚一边去,老娘也疼。这样就对味了。
但问题是,你扮演我温柔的女朋友,这句话并不是我们真正想说的内容,显得有一点出戏。于是人们干脆把人设信息单独的拎了出来,放到另外一个Prompt里面,这就是System Prompt,系统提示词。
System Prompt主要用来描选AI的角色、性格、背景信息、语气等等等等。总之只要不是用户直接说出来的内容,都可以放进System Prompt里面,每次用户发送User Prompt的时候,系统会自动把System Prompt也一起发给AI模型,这样整个对话就显得更加自然了。
不过即使人设设定的再完美,说到底AI还是个聊天机器人,你问一个问题,他最多给你答案,或者告诉你怎么做,但实际动手的还是你自己。那么能不能让AI自己去完成任务呢?
AI Agent和Tool
即使我们给AI的提示词写得再详细,比如让它帮忙整理电脑里的文件,AI 只能回答问题或者给出建议,实际动手的还是得靠我们自己,那有没有办法让AI自己完成任务呢?这就需要在用户和AI 中间引入一个智能体Agent来帮忙。
智能体agent就像一个中间人(本质上就是我们写的程序),它负责接收用户的指令,并协调AI和实际工具来干活。
具体来说,我们可以给智能体agent准备好一些基本工具,比如查找文件、读取文件、移动文件等工具。当用户发出指令,比如帮我读取C盘目录下的hello_world.java文件,移动到D盘目录下,最后总结文件内容:
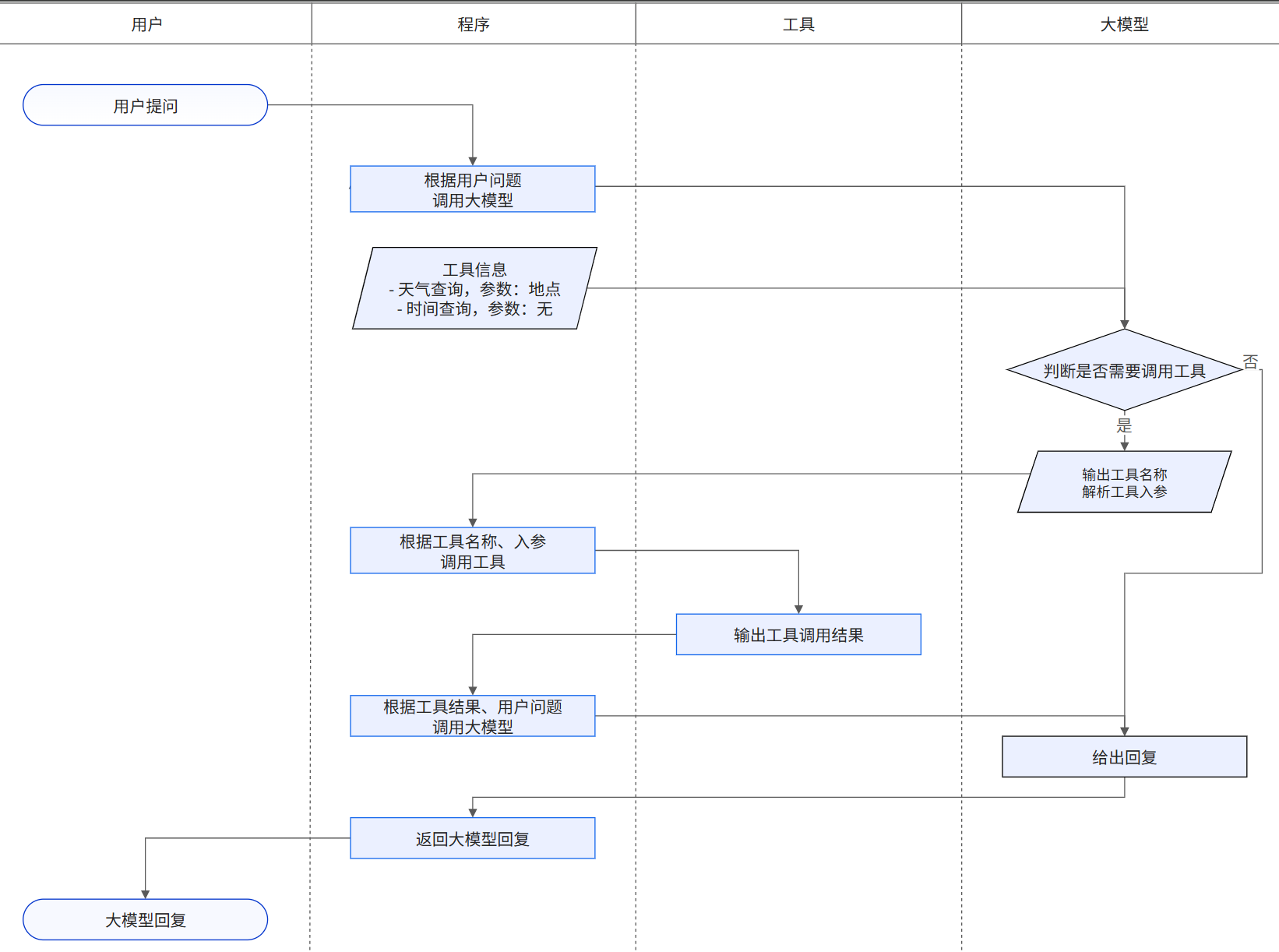
- 智能体agent会先把这个请求传给AI,并附带告诉AI它可以使用哪些工具,工具有哪些作用。
- AI经过思考后,会告诉智能体Agent调用读取文件工具,路径是C://hello_world.java。
- 智能体agent收到指示后,就实际操作工具读取文件,然后把读取的内容反馈给AI。
- AI根据结果决定下一步该做什么,比如可能还需要移动文件,会告诉智能体agent调用移动文件工具,路径是C://hello_world.java 到 D://hello_world.java
- 智能体agent收到指示后,就实际操作工具移动文件,然后把移动结果反馈给AI。
- AI 收到移动完成的进度后,返回总结内容给智能体。
- 智能体收到AI传来的结果后,向用户报告结果。这样一步步推进,智能体agent全程协调,直到任务完成。
第一个做出尝试的是一个开源项目,叫做AutoGPT,它是本地运行的一个小程序。
如果你想让AutoGPT帮你管理电脑里的文件,那你得先写好一些文件的管理函数,比如说 list_files 用来列目录, read_files 用来读文件等等等等。然后你把这些函数以及它们的功能描述、使用方法,注册到AutoGPT中。
AutoGPT会根据这些信息生成一个System Prompt,告诉AI模型用户给了你哪些工具,他们都是干什么的,以及AI如果想要使用它们,应该返回什么样的格式,最后把这个System Prompt连同用户的请求,比如说帮我找一找原神的安装目录,一起发给AI模型。
如果AI模型足够的聪明,就会按照要求的格式,返回一个调用某个函数的消息。AutoGPT进行解析之后,就可以调用对应的函数了,然后再把结果丟回给AI,AI再根据函数调用的结果,决定下一步应该做什么操作,这个过程就这样反复,直到任务完成为止。
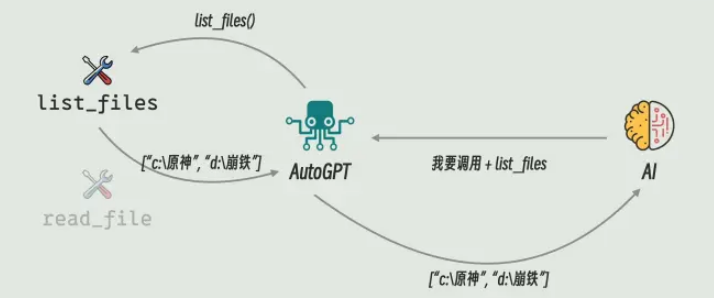
而这些提供给AI 调用的函数或者服务,就叫做Agent Tool。
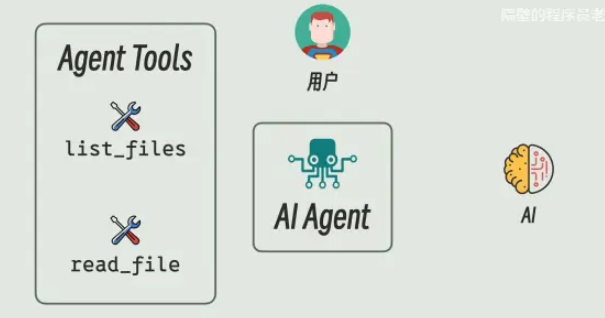
Agent与Tool定义:
- Agent:在AI、工具、用户间协调的程序
- Tool:提供给AI调用的函数。
说白了就是,LLM模型是脑子,Agent是手,模型提供的是思路,具体做事的是Agent
不过这个架构有一个小问题,虽然我们在System Prompt 里面写清楚了Al应该用什么格式返回。但AI模型嘛,说到底它是一个概率模型,还是有可能返回格式不对的内容。
为了处理这些不听话的情况,很多AI Agent会在发现AI回的格式不对时,自动进行重试。一次不行我们就来第二次。
Function Calling
但这种反复的重试总归让人觉得不太靠谱,于是大模型厂商开始出手了,ChatGPT, Claude,Gemini等等,纷纷推出了一个叫做 Function Calling 的新功能。这个功能的核心思想就是统一格式,规范描述。
例如,我们通过System Prompt,告诉AI有哪些工具以及返回的格式。但是这些描述是用自然语言随意写的,只要AI看得懂就行,Function Calling则对这些描述进行了标准化。比如每个Tool都用一个JSON对象来定义工具名。工具名写在name字段、功能说明写在desc 字段,所需要的参数写在params里面等等等等。然后这些JSON对象也从System Prompt中被剥离了出来,单独放到了一个字段里面。最后Function Calling 也规定了AI使用工具时应该返回的格式。所以System Prompt中的格式定义也可以删掉了,这样一来,所有的工具描述都放在相同的地方,所有工具描述也都依照相同的格式,Al使用工具时的回复也都依照相同的格式。
于是人们就能更加有针对性的训练AI模型,让他理解这种调用的场景。甚至在这种情况下,如果AI依然生成了错误的回复,因为回复的格式是固定的,AI服务器端自己就可以检测到。井且进行重试,用户根本感觉不到。这样一来,不仅降低了用户端的开发难度,也节省了用户端重试带来的Token开销。
正是由于这些好处,现在越来越多的AI Agent 开始从System Prompt 指向 Function Calling
相关原理如下:
Function Calling定义:把工具描述从system prompt中剥离,用JSON格式统一定义函数名,函数介绍,参数字段并规范AI调用工具的回复格式。这就是Function Calling的核心:用标准化格式让AI理解怎么调用工具,而不是猜。
举个例子:
工具描述(Tool Definition):
{
"name":"check_weather",//工具唯一名称(AI 调用时会用这个名字)
"description":"获取指定城市的当天天气情况,包括温度、天气状况(晴/雨/多云等)和风力",//工具功能说明(AI靠这个判断是否需要调用)
"parameters":{//调用工具必须传递的参数(类似必填项)
"type":"object",
"properties":{
"city":{//参数1:城市名
"type":"string",
"description":"需要查询天气的城市名称,例如:北京、上海、广州" //参数说明(AI会根据这个问用户要信息)
},
"date":{//参数2:日期(可选参数,默认当天)
"type": "string",
"format":"YYYY-MM-DD",//参数格式约束
"description":"查询的日期,格式为年-月-日,例如:2026-02-03,默认查询当天"
}
},
"required":["city"]//必须传递的参数(这里city 是必填,date 可选)
}
}AI调用格式(Function Call):
{
"function_cal1":{//固定字段,表示这是一个工具调用请求
"name":"check_weather",//工具名(必须和上面定义的 name 一致)
"parameters":{//参数值(严格对应工具定义的 parameters)
"city":"北京",//必填参数:城市名
"date":"2026-02-03"//可选参数:日期(用户指定了,所以带上)
}
}工具返回结果(Tool Response):
{
"temperature":18,//温度(单位:°C)
"condition":"多云转晴",//天气状况
"wind":"3级西北风",//风力
"city":"北京",
"date": "2026-02-03"
}Function Calling的好处:
- 告别猜谜语:以前靠System Prompt用自然语言描述工具,AI可能听不懂;现在用JSON格式,AI一看就会。
- 降低开发难度:开发者不用自己写代码检测AI回复是否正确,若AI回复错误,AI的服务器端可检测并自动重试,降低用户端开发难度和token开销。
- 跨场景通用:无论是ChatGPT还是开源模型,只要支持FunctionCalling,就能用同一套工具。
但Function Calling也有自己的问题,就是没有统一的标准,每家大厂的API定义都不一样,而且很多开源模型还不支持Function Calling。所以真的要写一个跨模型通用的Al Agent其实还挺麻烦的。因此System Prompt和 Function Calling这两种方式,现在在市面上是并存的。
Skills
而最近出现的 Skill 又是什么?
Skill 是一个用自然语言定义的、具有特定领域上下文(Domain Context)的逻辑指令集,本质上是通过延迟加载(Lazy Loading)优化 Token 消耗的 sub-agent
在团队协作中,很多"隐性知识"都在老员工脑子里,比如代码规范、排查流程、Review 标准。Skills 的核心价值,就是把这些隐性规则变成显性的文档(SOP),让 AI 能够自主阅读、理解并执行。
与传统编程不同,Skills 不强制规定每一步的代码逻辑,而是用自然语言将决策权下放给模型——模型通过 load_skill() 动态加载 SKILL.md 后,将其中定义的规则、流程和约束实时注入到推理上下文中,指导后续的工具调用和决策。这既保留了 Agent 处理不确定性的优势,又避免了纯代码编排的僵化。
为什么不用"基于 Function Calling 封装"?这个表述容易让人误以为 Skill 是某种 Function Calling 的语法糖。实际上,Skill 的核心机制是上下文注入——Agent 读取 Markdown 文档,把其中的规则和流程纳入推理上下文。Function Calling 只是 Agent 执行某些动作(如调脚本、查资源)时可能用到的底层手段,不是 Skills 本身的定义层。
注意:
load_skill()是对"Agent 读取并激活 SKILL.md"这一过程的概念性描述,不同工具的实际触发方式会有差异。
Agent+skills,在很多时候,就是workflow的一种呈现,Skill本质是规范化的Prompt,甚至宝玉老师在一篇文章中的原话更为激进:“几乎所有能用 workflow 完成的AI任务,都可以用Agent + Skills实现。”
Prompt是啥呢,Prompt就像你站在他旁边,当场口头交代任务。而Skills,就像你给他一本公司内部的那种SOP手册,你们肯定见过无数了。而且这手册不是那种一张长到让人窒息的Word,它更像一个知识库般的文件夹,里面可以放规范、脚本、模板、参考资料等等,Agent呢,会在需要时自己去翻。Skills可以认为就是按需加载的Prompt技能包
skill在md文件中有 名称 和 描述 两个元数据,其它都不是必须的。而元数据会合并到 tools 的工具描述中,Agent每次请求都会把skills带上(这里只会带上元数据信息,而不是一整个skill,防止大量消耗token),大模型会根据用户的问题去找对应的工具,根据元数据描述找到对应的skill,再要求Agent去读取那个 skill的md文件,大模型再给出解决方案。
再往详细了说,Skill也可以认为是对Function Call做了一层业务化的封装和组织。因为在实际项目中,单个函数的能力太零散了,比如我们要做一个"智能邮件助手",可能需要"发送邮件"、"查询邮件"、"标记已读"、"删除邮件"等好几个函数配合使用,这时候我们就会把这些相关的Function打包成一个"邮件处理Skill"。
从结构上看,Skill 很简单,核心就是一个 SKILL.md 文件,包含元数据**(描述什么时候用)和正文(具体的执行 SOP)。
设计上的亮点是“渐进式披露”:
- 元数据常驻上下文,AI 知道有哪些技能可用。
- 正文按需加载,只有触发时才读取,避免挤占 Token。
复杂点的 Skill,还会有附加的资源目录、脚本和参考文档。
举个例子:数据平台要让 AI 自主排查慢查询、审查代码规范、生成报告,这些能力你怎么组织?
方案一:把审查标准写进系统 Prompt,再挂上对应的 Function Calling 接口,大模型按需去调。那么当工作流节点涨到二三十个的时候,每次的Prompt 大概消耗多少 token?这种方案能跑,但本质上是把所有东西塞进一个方法里——上下文一长,模型注意力稀释,开始幻觉;需求一变,牵一发动全身;换个项目,从头再写。
方案二:把每一项专项能力(代码审查标准、慢查询排查流程、报告生成规范)分别写成独立的 SKILL.md——元数据常驻上下文,正文按需加载;新人能读懂,换项目能复用,Agent 按需激活执行,互不干扰。
这样做的好处是代码组织更清晰,复用性也更强,团队协作的时候也能按Skill来分工。例如在项目中专门建一个skills目录,每个Skill对应一个独立的模块,里面包含这个领域的所有函数定义和实现逻辑。从架构角度看,Skill是Function Call在工程实践中自然演化出来的一种组织形式。
MCP
以上我们讲的都是Al Agent和AI模型之间的交互方式,按下来我们再看另一边,Al Agent是怎么跟Agent Tools来进行通信的。最简单的做法是把AIAgent和Agent Tools写在同一个程序里面,直接函数调用搞定,这也是现在大多数Agent的做法。
但是后来人们逐渐发现,有些Tool的功能其实挺通用的,比如说一个浏览网页的工具,可能多个Agent都需要,那我总不能在每个Agent面都拷贝一份相同的代码吧,太麻烦了,也不优雅,于是大家想到了一个办法。把Tool变成服务统一的托管,让所有的Agent都采调用,这就是MCP
MCP是一个通信协议,专门用来规范Agent和Tool服务之间是怎么交互的,运行Tool的服务叫做MCP Server,週用它的Agent叫做MCP Client。它想解决的核心问题是,现在市面上各家大模型、各种工具、各类数据源之间的对接都是"各自为政"的,开发者要对接不同的系统就得写不同的适配代码,特别麻烦。
MCP规定了MCP Server如何和MCP Client通信,以及MCP Server要提供哪些接口,比如说用采查询MCP Server中有哪些Tool,Tool的功能、描述需要的参数、格式等等的接口。
也就是说,所谓的MCP,就是Agent工具列表的一个扩展和延伸,让Agent可调用的工具变得更多。具体来说,MCP定义了服务端和客户端之间如何传递上下文、如何声明可用工具、如何返回执行结果等一整套规范。
除了普通的Tool这这种函数调用的形式,MCP Server也可以直接提供数据,提供类似文件读写的服务叫做Resources,或者为Agent提供提示词的模板叫做Prompt
MCP Server既可以和Agent跑在同一台机器上,通过标准输入输出进行通信,也可以被部署在网络上,通过HTTP进行通信。
这里需要注意的是,虽然MCP是为了AI而定制出来的标准,但实际上MCP本身却和AI模型没有关系
他并不关心Agent用的是哪个模型,MCP只负责帮Agent管理工具、资源和提示词
从这个角度看,MCP是站在更高的生态层面去思考问题,它不是要替代Function Call或者Skill,而是要给它们提供一套统一的"交流语言"。
RAG
RAG(检索、增强、生成)
RAG简单说就是先从资料库找答案,再让AI基于找到的内容生成回答 的这个过程。RAG是目前最火的AI问答方案,很多企业知识助手、智能客服背后使用的技术都是RAG。
为什么直接喂文档给大模型不行?
举个例子:如果你的产品手册有几百上千页,直接发给AI模型会出大问题!首先模型有上下文窗口限制,可能读了后面忘前面;其次输入越多推理成本越高,钱包会哭;最后输入量大了回答速度也会变慢,用户等不及。
RAG如何解决这些痛点?
RAG的聪明之处在于:只把和问题相关的片段发给模型!比如用户问产品保修政策,RAG会从几百页手册里精准揪出几个相关段落发给模型,大大提升效率和准确性。
A2A
以上说的都是单个Agent的之间的通信和使用,那么如果是多个Agent之间呢,如何互相通信呢?
A2A 是 Google 在 2025 年发布的协议,专门解决多个 AI Agent 之间怎么互相通信的问题。我理解它和 MCP 的区别是这样的:
- MCP 解决的是「单个 Agent 怎么连工具和数据」
- A2A 解决的是「多个 Agent 之间怎么分工协作」。
一个 Agent 通过 A2A 可以把子任务委托给另一个专业 Agent,接收方按自己的 Skill 声明承接,支持异步长任务和流式推送结果。两者是互补的,不冲突:MCP 向下连工具,A2A 向上连 Agent,在复杂的多 Agent 系统里这两个通常都要用到。
扩展:Skills 和 Prompt、MCP、Function Calling 究竟有什么区别?
Skills vs Prompt
| 维度 | Prompt | Skills |
|---|---|---|
| 本质 | 单次对话的文本指令 | 可持久化、可发现的能力单元 |
| 复用性 | 随对话上下文丢失,难以维护 | 标准化封装,跨项目、多场景复用 |
| 加载机制 | 全量载入(挤占 Token) | 延迟加载(按需读取正文) |
- Prompt:用户即时表达意图的载体(如"分析这份报表")。
- Skills:包含**元数据(何时使用)+ 正文(如何执行)**的完整方案,通过
load_skill()机制按需加载到上下文。
Skills vs MCP
这是最容易产生误解的地方。
| 维度 | MCP (Model Context Protocol) | Skills |
|---|---|---|
| 核心思路 | 标准化连接:通过 JSON-RPC 统一数据格式 | 逻辑编排:用自然语言描述复杂执行路径 |
| 定义方式 | 在 Server 端用代码写死逻辑 | 在 SKILL.md 中用自然语言引导模型决策 |
| 环境依赖 | 需要运行一个 MCP Server 进程 | 依赖可执行环境(如本地 Shell 或沙箱) |
| 哲学 | 以协议为中心:一次编写,所有 AI 通用 | 以模型为中心:利用模型推理能力处理不确定性 |
- MCP 解决的是连通性:它像 USB-C,让 AI 能以统一格式读文件、查数据库。
- Skills 解决的是编排逻辑:它像一份说明书,告诉 AI 如何执行复杂任务流——这些任务完全可以包括调用多个 MCP 工具。
- 两者的关系:它们不是竞争关系,而是解决不同层面的问题。MCP 负责把外部系统接入进来,Skills 负责决定什么时候用、怎么组合这些能力。一个高级 Skill 的底层往往就是调用多个 MCP 工具。
Function Calling vs Skills
| 维度 | Function Calling | Skills |
|---|---|---|
| 层级 | 底层机制 | 上层应用 |
| 依赖关系 | 基础能力 | 在执行时可能使用 Function Calling(如加载文档、执行脚本、读取资源) |
| 粒度 | 原子操作(单次工具调用) | 复合流程(多步骤决策 + 工具组合) |
Skills 没有创造新能力,而是通过自然语言文档将能力组织成更易用的形式:
- Agent 读取
SKILL.md,将规则和流程注入推理上下文。 - 根据上下文指导,Agent 可能通过 Function Calling 执行脚本、读取资源或调用 MCP 工具。
系统总结
| 组件 | 一句话定义 | 形象类比 | 关键理解 |
|---|---|---|---|
| Prompt | 即时意图表达的载体 | 用户说的话 | 单次、易失 |
| Function Calling | LLM 输出结构化调用的能力 | 神经信号 | 一切的基础,实现非结构化 → 结构化转换 |
| MCP | 标准化的工具接入协议 | USB-C 接口 | 解决外部系统"如何接入"(连通性) |
| Skills | 用自然语言定义的 sub-agent | 任务说明书 | 解决复杂任务"如何编排"(执行逻辑),可调用 MCP 工具 |
四层关系:Function Calling 是地基 → Prompt 表达意图 → MCP 负责连通外部系统 → Skills 负责编排复杂任务流(可调用 MCP)
这里需要澄清一个常见误解:MCP 和 Skills 不是竞争关系,也不是非此即彼。
- MCP 解决外部系统如何接入:让 AI 能以统一格式读文件、查数据库、调用 API。
- Skills 解决复杂任务如何编排:用自然语言定义执行流程,这些流程完全可以包含调用多个 MCP 工具。
在实际项目中,两者经常配合使用:一个 Skill 的正文里会指导 Agent 先用 MCP 读取数据库,再用 MCP 调用外部 API,最后生成报告。
一句话总结:Prompt 承载意图,Function Calling 实现交互,MCP 负责连通外部系统,Skills 负责编排复杂任务流——从'说什么'到'怎么做'再到'聪明地做'。
AI相关链接汇总
- 提示词工程指南
- 国内AI排名
- LMArena
- AgentScope Java:阿里巴巴通义实验室开源的 多智能体(Multi-Agent)开发框架
