来源:https://zhuanlan.zhihu.com/p/436465508?utm_id=0,Seven进行了补充完善。本文略显枯燥,可多次观看揣摩
DDD概览
DDD(Domain-Driven Design)领域驱动设计。
DDD的技术画像:
一种思潮:技术主动理解业务,业务如何运行,软件就如何构建。让不怎么使用技术语言的领域专家参与软件建设——让程序员别再跟产品经理打架了
一种架构思想:别再没完没了的重构了,让复杂系统保持年轻,项目越复杂,使用DDD的收益就越大
重点就是解决软件难以理解,演进的问题
什么是DDD?
在领域驱动设计中,领域可以理解为业务,领域专家就是对业务很了解的人,比如你想要做一个在线车票的售票系统,那么平时看到的售票员可能就是领域专家,比如你已经在一个业务上做了5年研发了,经历了各种需求的迭代,讨论,你懂得比新来的产品,业务还多,那么你有可能就是你们公司的领域专家。领域驱动设计的核心就是与领域专家一起通过领域建模的方式去设计软件程序。因此领域专家可能是产品经理,也可能是程序员本身
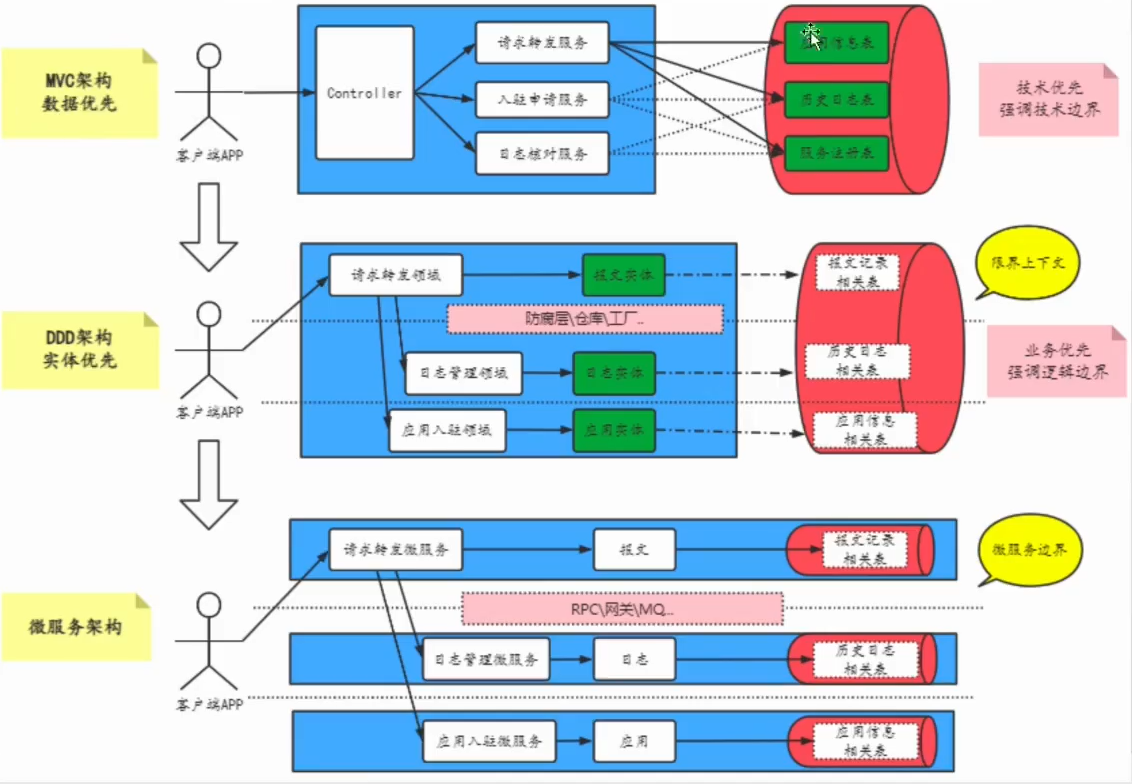
有了MVC,为什么还要DDD
传统MVC架构:大泥球结构严重影响系统的灵活性,如下图所示,如同微服务拆分一样,在前期对系统进行拆分是很容易的。但是当项目做大后,再想对系统进行拆分,就变得无比复杂,因为底层的服务都在互相调用,显得混乱和复杂
通俗理解DDD,就是为了做系统的拆分。DDD把整个系统看成是领域和领域之间的组合,单体设计阶段可能领域都是放在一起,但当某个领域变得复杂或并发压力过大后,就将其拆分成微服务,而领域的拆分是更容易的,这样整个系统的建设就变得更加灵活。从而让整个架构贯穿整个项目周期
领域是什么
领域很抽象,可以通俗理解为不同的业务,他们之间拥有较为明显的边界。比如可以把Java当成是一个领域,其实就是为了将它和python、C++等其他语言区分开
比如在编码阶段,UserController管用户的操作,OrderController管订单的操作,它们之间有明显的边界,有了边界就可以划分领域。但是这种领域划分和DDD还是有区别的,DDD是从设计 到落地 到开发过程 到后续的扩展维护 一直都贯彻的思想。但是这种UserController的方式并不会贯彻这种思想,如在服务层OrderService一般都需要获取到用户信息,此时就需要通过调用UserService里的方法来获取用户信息,这样就导致边界不清晰了(Order领域调用了User领域),因此这种方式还不能称之为领域。
业务优先VS技术优先
如下所示,技术优先的产物,以传统MVC的思想开发的,也就是数据驱动,会根据有哪些数据,设计什么表结构,再进行开发。当业务去看这些包名类名的时候,不去看具体代码,就不知道这些包是做什么的

而将业务划分为一个一个领域后,程序员再通过划分后的领域进行编码,即使是不懂技术的产品经理也能看懂每个包是做什么事,是负责什么业务,从而使得领域专家也参与到系统的设计中来
以通用语言为建设核心
其实每个领域下有相同的包结构,这就可以理解为是某种形式上的通用语言。从而让领域专家和程序员都能理解,并且参与到系统的建设中去
以四层架构为基本思想
DDD四层架构规范:
领域层:Domian Layer:放之四海而皆准的理想。系统的核心,纯粹表达业务能力,不需要任何外部依赖。
应用层:Application Layer:理想与现实,薄薄的一层。协调领域对象,组织形成业务场景。只依赖于领域层。
用户层:UserInterface:护城河。负责与用户进行交互。解释用户请求,返回用户响应。只依赖于应用层
基础层:InfrastructureLayer:业务与数据分离。为领域层提供持久化机制,为其他层提供通用技术能力。
DDD可以做什么
DDD有助于解决系统老化问题
新需求越提越难:产品经理又不懂这个系统怎么设计的,系统越来越复杂,那需求要怎么提
开发越来越难:一个类上千行代码,这怎么看?这段代码有什么用?能不能去掉?
测试越来越难:没办法单元测试,一个小需求又要回归测试
技术创新越来越难:外面新技术越来越多,老系统没时间重构,越拖越烂

DDD主要分为两个部分,战略设计与战术设计
战略设计围绕微服务拆分,归类,划分边界
战术设计围绕微服务构建
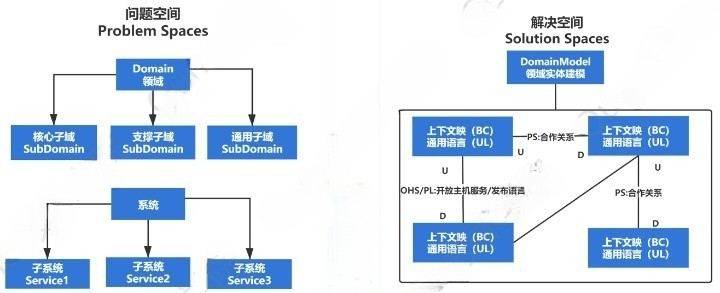
战略设计
官方解释:在某个领域,核心围绕上下文的设计。
主要关注上下文的划分(Bounded Context)、上下文映射的设计(Context Map)、通用语言的定义(Ubiquitous Language)
对以上内容进行大白话解释:
- 某个系统,核心围绕子系统的设计。
- 主要关注系统的划分(就是子领域的划分)、交互方式(比如HTTP、RPC等)、系统内的核心术语定义(通用语言、消除语义二义性)
战略设计要做的:
战术设计
官方解释:核心关注上下文中的实体建模,定义值对象、实体等,更偏向开发细节。
大白话就是:核心关注某个子系统的代码实现,以面向对象的思维设计类的属性和方法。
战术设计术语

实体与值对象
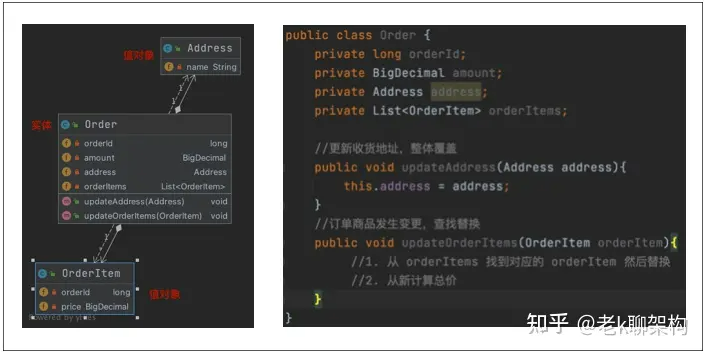
- 实体的特征
官方解释:实体是指描述了领域中唯一的且可持续变化的抽象模型。通常建模时, 名词用于给概念命名,形容词用于描述这些概念,而动词则表示可以完成的操作。
大白话解释:实体就是对象的方法和属性实现业务逻辑的类,一般由唯一标识id和 值对象组成,属性发生改变,可以影响类的状态和逻辑。唯一标识,对唯一性事物进行建模
包含了业务的关键行为,可以随着业务持续变化。其实就是属性会产生变化的业务逻辑
修改时,因为有唯一标识,所以还是同一个实体
- 值对象的特征
官方解释:描述了领域中的一件东西,将不同的相关属性组合成了一个概念整体, 当度量和描述改变时,可以用另外一个值对象予以替换,属性判等、固定不变。
大白话解释:不关心唯一性,具有校验逻辑、等值判断逻辑,只关心值的类。描述事物的某个特征,通常作为实体属性存在,不包含业务逻辑
创建后即不可变
修改时,用另一个值对象予以替换
领域服务
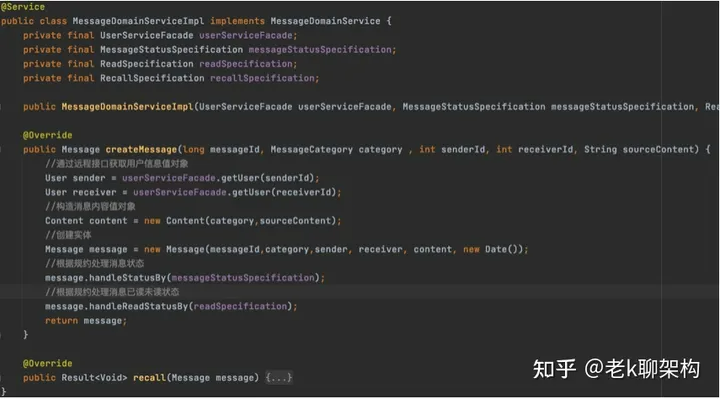
领域服务可以帮助我们分担实体的功能,承接部分业务逻辑,做一些实体不变处理的业务流程,它不是必须的。
在上图中,描述的是一个创建消息的领域服务,因为消息的实体中有用户的值对象,但是用户的信息通常在另一个限界上下文,也就是另一个微服务中,因此需要通过一些facade接口获取,如果把这些接口的调用放在领域实体中就会导致实体过于臃肿,且也不必保持其独立性,因为它需要被类似于Spring这样的框架进行管理,依赖注入一些接口,因此通过领域服务进行辅助是一种很好的方式。
聚合

将实体和值对象在一致性边界之内组成聚合,使用聚合划分限界上下文(微服务)内部的边界,聚合根做为一种特殊的实体,用于管理聚合内部的实体与值对象,并将自身暴露给外部进行引用。
官方解释:实体和值对象会形成聚合,每个聚合 一般是在一个事务中操作,一般都有持久化操作。聚合中,根实体的生命周期决定了聚合整体的生命周期。
大白话解释:就是对象之间的关联,只是规定了关联对象规则,操作聚合时,类似于操作Hibernate中 的One-Many对象的概念。
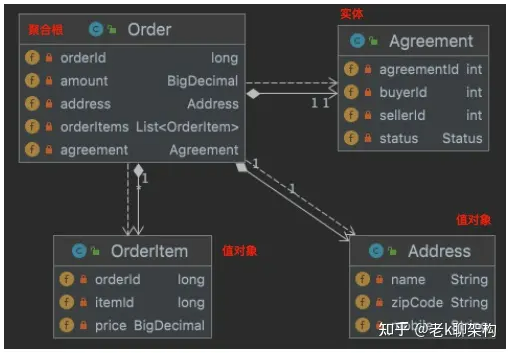
比如在上图中描述的是一个订单聚合,在这个聚合中,它里面有两个实体,一个是订单,一个是退货退款协议,显然退货退款协议应该依托于订单,但是它也符合实体的特征,因此被定义为实体。在此情况下,订单实体就是此聚合的聚合根。
聚合根 首先是实体,是聚合的管理者,是 外部访问的唯一入口
再比如:

工厂和仓库
要想真正将聚合落实到软件设计中,还需要两个非常重要的组件:仓库与工厂。
比如,现在创建了一个订单,订单中包含了多条订单明细,并将它们做成了一个聚合。这时,当订单完成了创建,就需要保存到数据库里,怎么保存呢?需要同时保存订单表与订单明细表,并将其做到一个事务中。这时候谁来负责保存,并对其添加事务呢?
过去我们采用贫血模型,那就是通过订单 DAO 与订单明细 DAO 去完成数据库的保存,然后由订单 Service 去添加事务。这样的设计没有聚合、缺乏封装性,不利于日后的维护。那么,采用聚合的设计应当是什么样呢?
采用了聚合以后,订单与订单明细的保存就会封装在订单仓库中去实现。也就是说采用了领域驱动设计以后,通常就会实现一个仓库(Repository) 去完成对数据库的访问。那么,仓库与数据访问层(DAO)有什么区别呢?
一般来说,数据访问层就是对数据库中某个表的访问,比如订单有订单 DAO、订单明细有订单明细 DAO、用户有用户 DAO。
- 当数据要保存到数据库中时,由 DAO 负责保存,但保存的是某个单表,如订单 DAO 保存订单表、订单明细 DAO 保存订单明细表、用户 DAO 保存用户表;
- 当数据要查询时,还是通过 DAO 去查询,但查询的也是某个单表,如订单 DAO 查订单表、订单明细 DAO 查订单明细表。
那么,如果在查询订单的时候要显示用户名称,怎么办呢?做另一个订单对象,并在该对象里增加“用户名称”。这样,通过订单 DAO 查订单表时,在 SQL 语句中 Join 用户表,就可以完成数据的查询。这时会发现,在系统中非常别扭地设计了两个或多个订单对象,并且新添加的订单对象与领域模型中的订单对象有较大的差别,显得不够直观。系统简单时还好说,但系统的业务逻辑变得越来越复杂时,程序阅读起来越来越困难,变更就变得越来越麻烦。
因此,在应对复杂业务系统时,我们希望程序设计能较好地与领域模型对应上:领域模型是啥样,程序就设计成啥样。我们就将订单对象设计成这样,订单对象的关联设计代码如下:
public class Order {
......
private Long customer_id;
private Customer customer;
private List<OrderItem> orderItems;
/**
* @return the customerId
*/
public Long getCustomerId() {
return customer_id;
}
/**
* @param customerId the customerId to set
*/
public void setCustomerId(Long customerId) {
this.customer_id = customerId;
}
/**
* @return the customer
*/
public Customer getCustomer() {
return customer;
}
/**
* @param customer the customer to set
*/
public void setCustomer(Customer customer) {
this.customer = customer;
}
/**
* @return the orderItems
*/
public List<OrderItem> getOrderItems() {
return orderItems;
}
/**
* @param orderItems the orderItems to set
*/
public void setOrderItems(List<OrderItem> orderItems) {
this.orderItems = orderItems;
}
}可以看到,在订单对象中加入了对用户对象和订单明细对象的引用:
- 订单对象与用户对象是多对一关系,做成对象引用;
- 订单对象与订单明细对象是一对多关系,做成对集合对象的引用。
这样,当订单对象在创建时,在该对象中填入 customerId,以及它对应的订单明细集合 orderItems;然后交给订单仓库去保存,在保存时,就进行了一个封装,同时保存订单表与订单明细表,并在其上添加了一个事务。
这里要特别注意,对象间的关系是否是聚合关系,它们在保存的时候是有差别的。譬如,在本案例中,订单与订单明细是聚合关系,因此在保存订单时还要保存订单明细,并放到同一事务中;然而,订单与用户不是聚合关系,那在保存订单时不会去操作用户表,只有在查询时,比如在查询订单的同时,才要查询与该订单对应的用户。
这是一个比较复杂的保存过程。然而,通过订单仓库的封装,对于客户程序来说不需要关心它是怎么保存的,它只需要在领域对象建模的时候设定对象间的关系,即将其设定为“聚合”就可以了。既保持了与领域模型的一致性、又简化了开发,使得日后的变更与维护变得简单。
有了这样的设计,装载与查询又应当怎样去做呢?所谓的 “装载(Load)”,就是通过主键 ID 去查询某条记录。比如,要装载一个订单,就是通过订单 ID 去查询该订单,那么订单仓库是如何实现对订单的装载呢?
首先,比较容易想到的是,用 SQL 语句到数据库里去查询这张订单。与 DAO 不同的是:
- 订单仓库在查询订单时,只是简单地查询订单表,不会去 Join 其他表,比如 Join 用户表,不会做这些事情;
- 当查询到该订单以后,将其封装在订单对象中,然后再去通过查询补填用户对象、订单明细对象;
- 通过补填以后,就会得到一个用户对象、多个订单明细对象,需要将它们装配到订单对象中。
这时,那些创建、装配的工作都交给了另外一个组件——工厂来完成。
DDD 的工厂
DDD 中的工厂,与设计模式中的工厂不是同一个概念,它们是有差别的。在设计模式中,为了避免调用方与被调方的依赖,将被调方设计成一个接口下的多个实现,将这些实现放入工厂中。这样,调用方通过一个 key 值就可以从工厂中获得某个实现类。工厂就负责通过 key 值找到对应的实现类,创建出来,返回给调用方,从而降低了调用方与被调方的耦合度。
而 DDD 中的工厂,与设计模式中的工厂唯一的共同点可能就是,它们都要去做创建对象的工作。
DDD 中的工厂,主要的工作是通过装配,创建领域对象,是领域对象生命周期的起点。譬如,系统要通过 ID 装载一个订单:
- 这时订单仓库会将这个任务交给订单工厂,订单工厂就会分别调用订单 DAO、订单明细 DAO 和用户 DAO 去进行查询;
- 然后将得到的订单对象、订单明细对象、用户对象进行装配,即将订单明细对象与用户对象,分别 set 到订单对象的“订单明细”与“用户”属性中;
- 最后,订单工厂将装配好的订单对象返回给订单仓库。
这些就是 DDD 中工厂要做的事情。
DDD 的仓库
然而,当订单工厂将订单对象返回给订单仓库以后,订单仓库不是简单地将该对象返回给客户程序,它还有一个缓存的功能。在DDD 中“仓库”的概念,就是如果服务器是一个非常强大的服务器,那么我们不需要任何数据库。系统创建的所有领域对象都放在仓库中,当需要这些对象时,通过 ID 到仓库中去获取。
但是,在现实中没有那么强大的仓库,因此仓库在内部实现时,会将领域对象持久化到数据库中。数据库是仓库进行数据持久化的一种内部实现,它也可以有另外一种内部实现,就是将最近反复使用的领域对象放入缓存中。这样,当客户程序通过 ID 去获取某个领域对象时,仓库会通过这个 ID 先到缓存中进行查找:
查找到了,则直接返回,不需要查询数据库;
没有找到,则通知工厂,工厂调用 DAO 去数据库中查询,然后装配成领域对象返回给仓库。
仓库在收到这个领域对象以后,在返回给客户程序的同时,将该对象放到缓存中。
以上是通过 ID 装载订单的过程,那么通过某些条件查询订单的过程又是怎么做呢?查询订单的操作同样是交给订单仓库去完成。
- 订单仓库会先通过订单 DAO 去查询订单表,但这里是只查询订单表,不做 Join 操作;
- 订单 DAO 查询了订单表以后,会进行一个分页,将某一页的数据返回给订单仓库;
- 这时,订单仓库就会将查询结果交给订单工厂,让它去补填其对应的用户与订单明细,完成相应的装配,最终将装配好的订单对象集合返回给仓库。
简而言之,采用领域驱动的设计以后,对数据库的访问就不是一个简单的 DAO 了,这不是一种好的设计。通过仓库与工厂,对原有的 DAO 进行了一层封装,在保存、装载、查询等操作中,加入聚合、装配等操作。并将这些操作封装起来,对上层的客户程序屏蔽。这样,客户程序不需要以上这些操作,就能完成领域模型中的各自业务。技术门槛降低了,变更与维护也变得简便了。
生命周期一致性
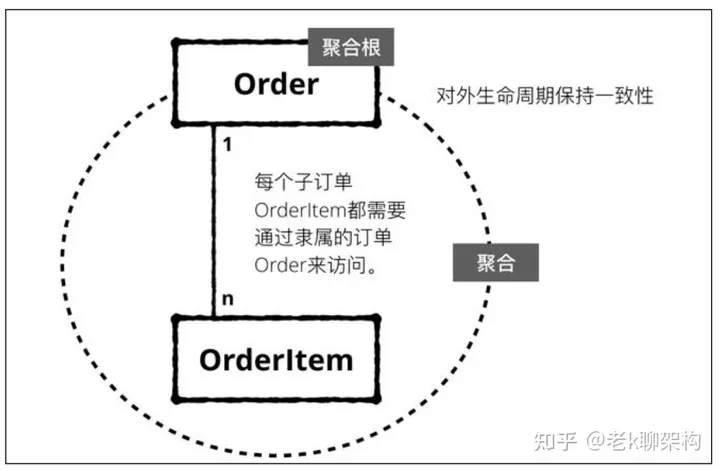
生命周期的一致性,聚合对外的生命周期保持一致,聚合根生命周期结束,聚合的内部所有对象的生命周期也都应该结束。
事务的一致性

事务的一致性,这里的事务指的是数据库事务,每个数据库事务指包含一个聚合,不应该有垮聚合的事务
领域事件
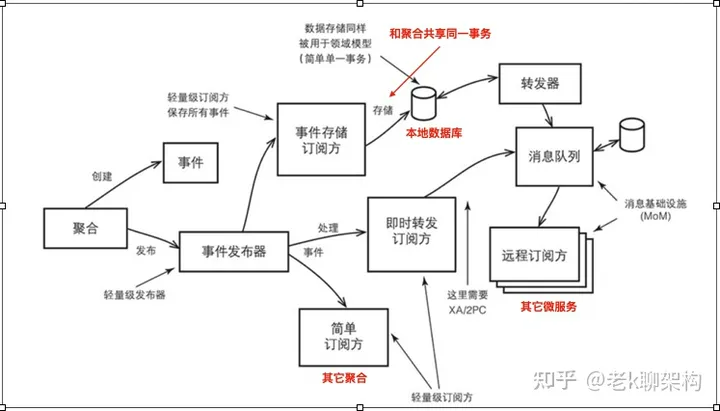
领域事件表示领域中所发生的事情,通过领域事件可以实现微服务内的信息同步,同时也可以实现对外部系统的解耦。
如上图所示,聚合变更后创建领域事件,领域事件有两种方式进行发布。
- 与聚合事务一起进行存储,比如存储进一个本地事件表,在由事件转发器转发到消息队列,这样保证的事件不会丢失。
- 直接进行转发到消息队列,但是此时因为事件还未入口,因此需要在聚合事务与消息队列发布事件之间做XA的2PC事务提交,因为有2PC存在,通常性能不会太好。
资源库
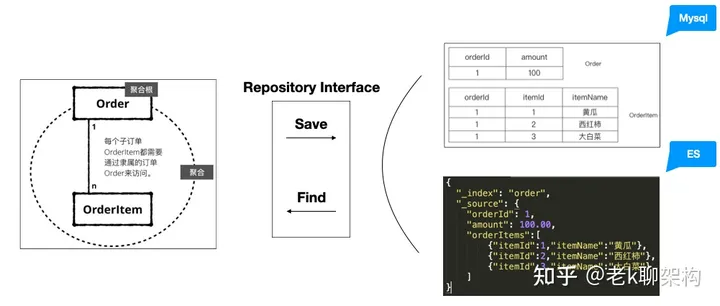
资源库是保存聚合的地方,将聚合实例存放在资源库(Repository)中,之后再通过该资源库来获取相同的实例。
- Save: 聚合对象由Repository的实现,转换为存储所支持的数据结构进行持久化
- Find: 根据存储所支持的数据结构,由Repository的实现转换为聚合对象
应用服务
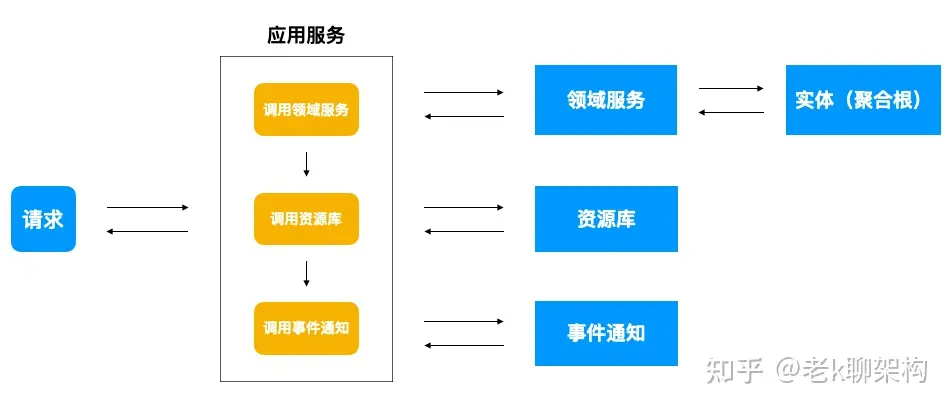
应用服务负责流程编排,它将要实现的功能委托给一个或多个领域对象来实现,本身只负责处理业务用例的执行顺序以及结果的拼装同时也可以在应用服务做些权限验证等工作。
DDD怎么做
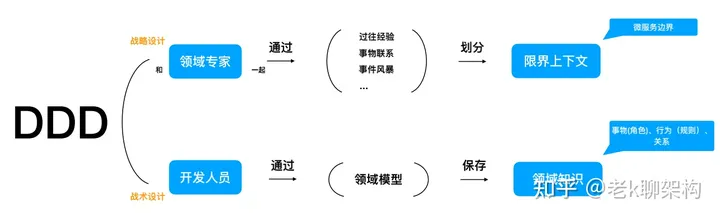
- 领域专家与研发人员一起(研发人员可能就是领域专家),通过一系列的方式方法(DDD并没有明确说明用什么方法),划分出业务的边界,这个边界就是限界上下文,微服务可以以限界上下文指定微服务的拆分,但是微服务的拆分并不是说一定以限界上下文为边界,这里面还需要考虑其它因数,比如3个火枪手原则、两个披萨原则以及组织架构对微服务拆分的影响等。
- 研发人员通过领域模型,领域模型就是DDD中用于指定微服务实现的模型,保存领域知识,通过这种方式DDD通过领域模型围绕业务进⾏建模,并将模型与代码进⾏映射,业务调整影响代码的同时,代码也能直接的反映业务。充血模型编码实践
充血模型编码实践
在DDD实践中,将大量用到充血模型的编码方式
贫血模型与充血模型
贫血模型:像MVC场景下的POJO类就是贫血模型
充血模型:与业务耦合的实体类
但是贫血模型会存在 贫血失忆症 的问题,如Acount实体实际上是为了承载转账业务、充值业务、支付业务等的,但是开发中将Acount实体的所有属性就放到一个类里,慢慢的这个实体承载什么业务就看不出来了,从而失忆了
影片租赁场景
需要说明的是下面的代码基本与《重构》一书中的代码相同,但笔者省略了重构的各个代码优化环节,只展示了贫血模型与充血模型代码的不同。
需求描述
根据顾客租聘的影片打印出顾客消费金额与积分
积分规则
- 默认租聘积一分,如果是新片且租聘大于1天,在加一分
费用规则
普通片 ,租聘起始价2元,如果租聘时间大于2天,每天增加1.5元
新片 ,租聘价格等于租聘的天数
儿童片 ,租聘起始价1.5元,如果租聘时间大于3天,每天增加1.5元
基于贫血模型的实现
下面是影片 Movie 、租赁 Rental 两个贫血模型类,下面这样的代码在我们日常开发中是比较常见,简单来说它们就是只包含属性。与数据库中的数据字段对应,不包含业务逻辑的类,从面向对象角度来说也违背了面向对象里面封装的设计原则。
面向对象封装:隐藏信息、保护数据,只暴露少量接口,提高代码的可维护性与易用性;
public class Movie {
public static final int CHILDRENS = 2;
public static final int REGULAR = 0;
public static final int NEW_RELEASE = 1;
private String title;
private Integer priceCode;
public Movie(String title, Integer priceCode) {
this.title = title;
this.priceCode = priceCode;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public Integer getPriceCode() {
return priceCode;
}
public void setPriceCode(Integer priceCode) {
this.priceCode = priceCode;
}
}
plain
public class Rental {
/**
* 租的电影
*/
private Movie movie;
/**
* 已租天数
*/
private int daysRented;
public Rental(Movie movie, int daysRented) {
this.movie = movie;
this.daysRented = daysRented;
}
public Movie getMovie() {
return movie;
}
public void setMovie(Movie movie) {
this.movie = movie;
}
public int getDaysRented() {
return daysRented;
}
public void setDaysRented(int daysRented) {
this.daysRented = daysRented;
}
}接着是Customer类,Customer类的问题是里面包含了原本应该是Movie与Reatal的业务逻辑,给人感觉很重,Customer可以类别日常开发的XxxService,想想是不是在Service层中不断的堆砌业务逻辑。
public class Customer{
private String name;
private List<Rental> rentals = new ArrayList<>();
public Customer(String name) {
this.name = name;
}
public void addRental(Rental rental) {
this.rentals.add(rental);
}
public String getName() {
return name;
}
/**
* 根据顾客租聘的影片打印出顾客消费金额与积分
* @return
*/
public String statement(){
double totalAmount = 0;
String result = getName()+"的租聘记录 \n";
for (Rental each : rentals){
double thisAmount = getAmount(each);
result += "\t" + each.getMovie().getTitle() + " \t" + thisAmount +" \n";
totalAmount += thisAmount;
}
int frequentRenterPoints = getFrequentRenterPoints(rentals);
result += "租聘总价 : "+ totalAmount + "\n";
result += "获得积分 : "+ frequentRenterPoints;
return result;
}
/**
* 获取积分总额
* @param rentals
* @return
*/
private int getFrequentRenterPoints(List<Rental> rentals){
return rentals.stream()
.mapToInt(rental -> {
//默认租聘积一分,如果是 Movie.NEW_RELEASE 且租聘大于1天,在加一分
int point = 1;
if(rental.getMovie().getPriceCode().equals(Movie.NEW_RELEASE) && rental.getDaysRented() > 1){
point ++;
}
return point;
})
.sum();
}
/**
* 获取单个影片租聘的价格
* 1. 普通片 ,租聘起始价2元,如果租聘时间大于2天,每天增加1.5元
* 2. 新片 ,租聘价格等于租聘的天数
* 3. 儿童片 ,租聘起始价1.5元,如果租聘时间大于3天,每天增加1.5元
* @param rental
* @return
*/
private double getAmount(Rental rental){
double thisAmount = 0;
switch (rental.getMovie().getPriceCode()){
case Movie.REGULAR:
thisAmount += 2;
if(rental.getDaysRented() > 2){
thisAmount += (rental.getDaysRented() - 2) * 1.5;
}
break;
case Movie.NEW_RELEASE:
thisAmount += rental.getDaysRented();
break;
case Movie.CHILDRENS:
thisAmount += 1.5;
if(rental.getDaysRented() > 3){
thisAmount += (rental.getDaysRented() - 3) * 1.5;
}
break;
default:
//nothings todo
break;
}
return thisAmount;
}
}最后运行主程序类,进行输出
主程序类
public class Main {
public static void main(String[] args) {
Movie movie1 = new Movie("儿童片", Movie.CHILDRENS);
Movie movie2 = new Movie("普通片", Movie.REGULAR);
Movie movie3 = new Movie("新片", Movie.NEW_RELEASE);
Customer customer = new Customer("张三");
customer.addRental(new Rental(movie1,1));
customer.addRental(new Rental(movie2,3));
customer.addRental(new Rental(movie3,5));
System.out.println(customer.statement())
}
}得到下面结果
张三的租聘记录
儿童片 1.5
普通片 3.5
新片 5.0
租聘总价 : 10.
获得积分 :基于充血模型的实现
类没有变化,只是类里面的实现发生了变化,接下来就逐一看看类的实现都发生了那些改变。
重构后影片 Movie 类
- 删除了不必要setXXX方法
- 增加了 getCharge 获取费用电影费用的方法,将原本 Customer 的逻辑交由Movie类实现。
public class Movie {
public static final int CHILDRENS = 2;
public static final int REGULAR = 0;
public static final int NEW_RELEASE = 1;
private String title;
private Integer priceCode;
public Movie(String title, Integer priceCode) {
this.title = title;
this.priceCode = priceCode;
}
public String getTitle() {
return title;
}
public Integer getPriceCode() {
return priceCode;
}
/**
*获取单个影片租聘的价格
* 1. 普通片 ,租聘起始价2元,如果租聘时间大于2天,每天增加1.5元
* 2. 新片 ,租聘价格等于租聘的天数
* 3. 儿童片 ,租聘起始价1.5元,如果租聘时间大于3天,每天增加1.5元
* @param daysRented
* @return
*/
public double getCharge(int daysRented){
double thisAmount = 0;
switch (this.priceCode){
case REGULAR:
thisAmount += 2;
if(daysRented > 2){
thisAmount += (daysRented - 2) * 1.5;
}
break;
case NEW_RELEASE:
thisAmount += daysRented;
break;
case CHILDRENS:
thisAmount += 1.5;
if(daysRented > 3){
thisAmount += (daysRented - 3) * 1.5;
}
break;
default:
//nothings todo
break;
}
return thisAmount;
}
}重构后租赁 Rental 类
- 移除了部分不必要的 get / set 方法
- 增加一个 getPoint 方法,计算租赁积分,将原本 Customer 的逻辑交由获取积分的业务交由getPoint实现,但总积分的计算还是在Customer。
- 增加一个 getCharge 方法,具体调用Movie::getCharge传入租赁天数得到租赁的费用,因为在这个需求中主体是租赁
public class Rental {
/**
* 租的电影
*/
private Movie movie;
/**
* 已租天数
*/
private int daysRented;
public Rental(Movie movie, int daysRented) {
this.movie = movie;
this.daysRented = daysRented;
}
public Movie getMovie() {
return movie;
}
/**
* 默认租聘积一分,如果是新片且租聘大于1天,在加一分
* @return
*/
public int getPoint(){
int point = 1;
if(this.movie.getPriceCode().equals(Movie.NEW_RELEASE) && this.daysRented > 1){
point ++;
}
return point;
}
/**
* 获取费用
* @return
*/
public double getCharge(){
return this.movie.getCharge(this.daysRented);
}
}
// 瘦身后的Customer
public class Customer {
private String name;
private List<Rental> rentals = new ArrayList<>();
public Customer(String name) {
this.name = name;
}
public void addRental(Rental rental) {
this.rentals.add(rental);
}
public String getName() {
return name;
}
/**
* 根据顾客租聘的影片打印出顾客消费金额与积分
* @return
*/
public String statement(){
double totalAmount = 0;
String result = getName()+"的租聘记录 \n";
for (Rental each : rentals){
double thisAmount = each.getCharge();
result += "\t" + each.getMovie().getTitle() + " \t" + thisAmount +" \n";
totalAmount += thisAmount;
}
int frequentRenterPoints = getFrequentRenterPoints(rentals);
result += "租聘总价 : "+ totalAmount + "\n";
result += "获得积分 : "+ frequentRenterPoints;
return result;
}
/**
* 获取积分总额
* @param rentals
* @return
*/
private int getFrequentRenterPoints(List<Rental> rentals){
return rentals.stream()
.mapToInt(Rental::getPoint)
.sum();
}
}最后我们运行主程序类,得到同样的输出。
订单的场景
需求描述
- 创建订单
- 设置订单优惠
订单场景贫血模型实现
Order 类 , 只包含了属性的Getter,Setter方法
public class Order {
private long orderId;
private int buyerId;
private int sellerId;
private BigDecimal amount;
private BigDecimal shippingFee;
private BigDecimal discountAmount;
private BigDecimal payAmount;
private String address;
}OrderService ,根据订单创建中的业务逻辑,组装order数据对象,最后进行持久化
public class OrderService {
/* 创建订单
* @param buyerId
* @param sellerId
* @param orderItems
*/
public void createOrder(int buyerId,int sellerId,List<OrderItem> orderItems){
//新建一个Order数据对象
Order order = new Order();
order.setOrderId(1L);
//算订单总金额
BigDecimal amount = orderItems.stream()
.map(OrderItem::getPrice)
.reduce(BigDecimal.ZERO,BigDecimal::add);
order.setAmount(amount);
//运费
order.setShippingFee(BigDecimal.TEN);
//优惠金额
order.setDiscountAmount(BigDecimal.ZERO);
//支付总额 = 订单总额 + 运费 - 优惠金额
BigDecimal payAmount = order.getAmount().add(order.getShippingFee()).subtract(order.getDiscountAmount());
order.setPayAmount(payAmount);
//设置买卖家
order.setBuyerId(buyerId);
order.setSellerId(sellerId);
//设置收获地址
order.setAddress(JSON.toJSONString(new Address()));
//写库
orderDao.insert(order);
orderItems.forEach(orderItemDao::insert);
}在此种方式下,核心业务逻辑散落在OrderService中,比如获取订单总额与订单可支付金额是非常重要的业务逻辑,同时对象数据逻辑一同混编,在此种模式下,代码不能够直接反映业务,也违背了面向对象的SRP原则。
设置优惠
/* 设置优惠
* @param orderId
* @param discountAmount
*/
public void setDiscount(long orderId, BigDecimal discountAmount){
Order order = orderDao.find(orderId);
order.setDiscountAmount(discountAmount);
//从新计算支付金额
BigDecimal payAmount = order.getAmount().add(order.getShippingFee()).subtract(discountAmount);
order.setPayAmount(payAmount);
//orderDao => 通过主键更新订单信息
orderDao.updateByPrimaryKey(order);
}贫血模型在设置折扣时因为需要考虑到折扣引发的支付总额的变化,因此还需要在从新的有意识的计算支付总额,因为面向数据开发需要时刻考虑数据的联动关系,在这种模式下忘记了修改某项关联数据的情况可能是时有发生的。
订单场景充血模型实现
Order 类,包含了业务关键属于以及行为,同时具有良好的封装性
/**
* @author zhengyin
* Created on 2021/10/
*/
@Getter
public class Order {
private long orderId;
private int buyerId;
private int sellerId;
private BigDecimal shippingFee;
private BigDecimal discountAmount;
private Address address;
private Set<OrderItem> orderItems;
//空构造,只是为了方便演示
public Order(){}
public Order(long orderId,int buyerId ,int sellerId,Address address, Set<OrderItem> orderItems){
this.orderId = orderId;
this.buyerId = buyerId;
this.sellerId = sellerId;
this.address = address;
this.orderItems = orderItems;
}
/**
* 更新收货地址
* @param address
*/
public void updateAddress(Address address){
this.address = address;
}
/**
* 支付总额等于订单总额 + 运费 - 优惠金额
* @return
*/
public BigDecimal getPayAmount(){
BigDecimal amount = getAmount();
BigDecimal payAmount = amount.add(shippingFee);
if(Objects.nonNull(this.discountAmount)){
payAmount = payAmount.subtract(discountAmount);
}
return payAmount;
}
/**
* 订单总价 = 订单商品的价格之和
* amount 可否设置为一个实体属性?
*/
public BigDecimal getAmount(){
return orderItems.stream()
.map(OrderItem::getPrice)
.reduce(BigDecimal.ZERO,BigDecimal::add);
}
/**
* 运费不能为负
* @param shippingFee
*/
public void setShippingFee(BigDecimal shippingFee){
Preconditions.checkArgument(shippingFee.compareTo(BigDecimal.ZERO) >= 0, "运费不能为负");
this.shippingFee = shippingFee;
}
/**
* 设置优惠
* @param discountAmount
*/
public void setDiscount(BigDecimal discountAmount){
Preconditions.checkArgument(discountAmount.compareTo(BigDecimal.ZERO) >= 0, "折扣金额不能为负");
this.discountAmount = discountAmount;
}
/**
* 原则上,返回给外部的引用,都应该防止间接被修改
* @return
*/
public Set<OrderItem> getOrderItems() {
return Collections.unmodifiableSet(orderItems);
}
}OrderService , 仅仅负责流程的调度
/* 创建订单
* @param buyerId
* @param sellerId
* @param orderItems
*/
public void createOrder(int buyerId, int sellerId, Set<OrderItem> orderItems){
Order order = new Order(1L,buyerId,sellerId,new Address(),orderItems);
//运费不随订单其它信息一同构造,因为运费可能在后期会进行修改,因此提供一个设置运费的方法
order.setShippingFee(BigDecimal.TEN);
orderRepository.save(order);
}在此种模式下,Order类完成了业务逻辑的封装,OrderService仅负责业务逻辑与存储之间的流程编排,并不参与任何的业务逻辑,各模块间职责更明确。
设置优惠
/* 设置优惠
* @param orderId
* @param discountAmount
*/
public void setDiscount(long orderId, BigDecimal discountAmount){
Order order = orderRepository.find(orderId);
order.setDiscount(discountAmount);
orderRepository.save(order);
}在充血模型的模式下,只需设置具体的优惠金额,因为在Order类中已经封装了相关的计算逻辑,比如获取支付总额时,是实时通过优惠金额来计算的。
* 支付总额等于订单总额 + 运费 - 优惠金额
* @return
*/
public BigDecimal getPayAmount(){
BigDecimal amount = getAmount();
BigDecimal payAmount = amount.add(shippingFee);
if(Objects.nonNull(this.discountAmount)){
payAmount = payAmount.subtract(discountAmount);
}
return payAmount;
}写到这里,可能读者会有疑问,文章都在讲充血模型的业务,那数据怎么进行持久化?
数据持久化时我们通过封装的 OrderRepository 来进行持久化操作,根据存储方式的不同提供不同的实现,以数据库举例,那么我们需要将Order转换为PO对象,也就是持久化对象,这时的持久化对象就是面向数据表的贫血模型对象。
比如下面的伪代码
private final OrderDao orderDao;
private final OrderItemDao orderItemDao;
public OrderRepository(OrderDao orderDao, OrderItemDao orderItemDao) {
this.orderDao = orderDao;
this.orderItemDao = orderItemDao;
}
public void save(Order order){
// 在此处通过Order实体,创建数据对象 new OrderPO() ; new OrderItemPO();
// orderDao => 存储订单数据
// orderItemDao => 存储订单商品数据
}
public Order find(long orderId){
//找到数据对象,OrderPO
//找到数据对象,OrderItemPO
//组合返回,order实体
return new Order();
}
}也就是说,在贫血模型中,数据和业务逻辑是割裂的,而在充血模型中数据和业务是内聚的。
支付功能DDD架构设计实战
业务需求:用户购买商品后,向商家进行支付
产品设计:实现步骤拆解
从数据库中查出用户和商户的具体信息
调用风控系统的微服务,进行风险评估
实现转入转出操作,计算双方金额变化,保存到数据库
发送交易的kafka,进行后续审计和风控
开发人员:简单,都不用设计了,随手就来
从而得到如下代码
public class PaymentController{
private PayService payService;
public Result pay(String merchantAccount,BigDecimal amount){
Long userid = (Long) session.getAttribute("userid");
return payService.pay(userld,merchantAccount, amount);
}
}
public class PayServicelmpl implements PayService{
private AccountDao accountDao;//操作数据库
private KafkaTemplate<String, String> kafkaTemplate;//操作kafka
private RiskCheckService riskCheckService;//风控微服务接口
public Resuit pay(Long userid,String merchantAccount,BigDecimal amount){
//1.从数据库读取数据
AccountDO clientDO = accountDAO.selectByUserid(userld);
AccountDO merchantDO= accountDAO.selectByAccountNumber(merchantAccount);
//2.业务参数校验
if (amount>(clientDO.getAvailable() {
throw new NoMoneyException();
}
//3.调用风控微服务
RiskCode riskCode =riskCheckService.checkPayment(...);
//4.检查交易合法性
if("0000"!= riskCode){
throw new invalideOperException;
}
//5.计算新值,并且更新字段
BigDecimal newSource = clientDO.getAvailable().subtract(amount);
BigDecimal newTarget= merchantDO.getAvailable().add(amount);
clientDO.setAvailable(newSource);
merchantDO.setAvailable(newTarget);
//6.更新到数据库
accountDAO.update(clientDO);
accountDAO.update(merchantDO);
//7.发送审计消息
String message = sourceUserld + "," + targetÃccountNumber + "," + targetAmount;
kafkaTemplate.send(TOPIC_AUDIT_LOG, message);
return Result.SUCCESS;
}
}存在的问题
这种是最常用的实现方式,但是在项目严谨的过程中,会带来项目老化的风险,也就是项目中“坏的味道”
可维护性差:大量的第三方模块影响核心代码稳定性。如风控微服务依赖于第三方的风控,假设以后风控系统做了什么变化,但是这个和业务本身的转账业务是无关的,是只在风控系统中改变的,但以上这种架构风控改动了,导致这块代码也可能需要跟着改动,造成可维护性差
可拓展性差:业务逻辑与数据库存储相互依赖,无法复用。如未来其它系统中也需要使用到这种转账的流程,但另一套系统的表结构,或第三方服务不一样,导致可拓展性差
可测试性差:庞大事务脚本与基础设施强耦合,无法单元测试。如果要测从数据库中读取的信息是对的这段代码,无法较为清晰的进行单元测试
最后的结果:业务多发生几次迭代后,这段代码就将成为一个可怕的黑洞
如何实现高质量应用?
高内聚,低耦合:类本身是内敛的,并且希望将每部分的改动只在某个模块内改动,而不需要改动业务本身的逻辑
遵循三大设计原则:
- 单一职责原则:一个类只负责单一职责,另一种理解也就是一个类应该只有一个引起他变化的原因。如上示例, 就是 只有转账业务流程变化了,才去改这段代码,只要转账业务流程不变,这段代码就不变。
- 开放封闭原则:对扩展开放,对修改封闭
- 依赖反转原则:程序之间应该只依赖于抽象接口,而不要依赖于具体实现。如上示例,虽然PayServicelmpl是实现于PayService这个接口,但是这种实现类是没有扩展的可能性的,因为没有其他业务会再来实现这个接口。
接下来对系统进行改造设计
一、抽象数据存储层
- 使用充血模型的实体对象,描述核心业务能力:系统能做什么事情,一目了然
一般会将引起属性变化的方法写到实体里
// 有业务逻辑的,称为实体
public class Account{
private Long id;
private Long accountNumber;
private BigDecimal available;
public void withdraw(BigDecimal money){
//转入操作
available =available + money;
}
public void deposit(BigDecimal money){
//转出操作
if(available < money){
throws new InsufficientMoneyException();
}
available=available -money;
}
}- 使用仓库与工厂,封装实体持久化控制,摆脱数据库限制
public interface AccountRepository{
......
}
public class AccountRepositoryImpl implements AccountRepository{
@Autowired
private AccountDao accountDAO;//与数据库交互
@Autowired
private AccountBuilder accountBuilder;//工厂组装类
@Override
public Account find(Long id){
AccountDO accountDO=accountDAO.selectById(id);
return accountBuilder.toAccount(accountDO);
}
@Override
public Account find(Long accountNumber){
AccountDO accountDO= accountDAO.selectByAccountNumber(accountNumber);
return accountBuilder.toAccount(accountDO);
}
@Override
public Account save(Account account){
AccountDO accountDO=accountBuilder.fromAccount(account);
if(accountDO.getId()==null){
accountDAO.insert(accountDO);
} else{
accountDAO.update(accountDO);
}
return accountBuilder.toAccount(accountDO);
}
}这样就可以把与数据库交互的所有的事都交由这个类来做,与数据库交互的过程与业务之间是没有影响的。假设未来需要换与数据库交互的结构,如将Hibernate换成mybatis,那其实就是另外起一个实现类,将DAO换成mapper即可
DDD中的工厂类(accountBuilder):通过工厂类来组装复杂的实体。主要通过这个类来完成 贫血模型的实体 和 充血模型实体 之间的转换。
假设Acount实体比较多,这个实体可能来自不同的表,可以通过这个工厂类来进行组装。也就是说,业务实体和数据库的表结构之间是可以拆分的;而传统开发是基于数据模型的,基本上是根据表进行设计的
如数据库中 数据的多对多的关系,在逻辑层面比较好实现,比如类A与类B的关系,实体里设计A:List<B>,B:List<A>。而数据库中只能通过A表、B表、及中间对应关系的A-B表
二、抽象第三方服务
这里也叫 **防腐层 :**通过构建防腐层隔离外部服务。
public interface Busisafeservice{
......
}
public class BusiSafeServiceImpl implements BusiSafeService{
@Autowired
private RiskChkService riskChkService;
public Result checkBusi(Long userId,Long mechantAccount,BigDecimal money){
//参数封装
RiskCode riskCode = riskCheckService.checkPayment(...);
if("0000".equals(reskCode.getCode()){
return Result.SUCCESS;
}
return Result.REJECT;
}
}无论这个风控服务是通过微服务还是通过HTTP,无论什么方式,在业务上是不变的,业务上只需要调用风控,风控告知业务是否继续进行即可
三、抽象中间件
//没有业务逻辑的实体,在DDD中称为值对象
public class AuditMessage{
private Long UserId;
private Long clientAccount;
private Long merchantAccount;
private BigDecimal money;
private Date data;
......
}
public interface uditMessageProducer{
......
}
public class AuditMessageProducerImpl implements AuditMessageProducer{
private KafkaTemplate<String,String> kafkaTemplate;
public SendResult send(AuditMessage message){
String messageBody = message.getBody();
kafkaTemplate.send("some topic",messageBody);
return SendResult.SUCCESS;
}
}无论对中间件消息的什么改变,都不会影响到业务逻辑。
四、用领域服务封装多实体逻辑
用领域服务,封装跨实体业务。保持实体的纯粹性,跨淤泥而不染
public interface AccountTransferService{
void transfer(Account sourceAccount,Account targetAccount,Money money);
}
public class AccountTransferServicelmpl implements AccountTransferService{
public void transfer(Account sourceAccount,Account targetAccount,Moneymoney){
sourceAccount.deposit(money);
targetAccount.withdraw(money);
}
}只需要调用自己的实体的业务动作,如Account实体有转入转出的能力,但需要两个实体才能完成转账的动作,而金额变化交由实体自己去做。
由多个实体构成的业务场景,交由领域层来完成,但是领域层只是薄薄的一层,只负责组装业务场景,不负责具体的逻辑实现,具体的实现交由实体去做
主业务逻辑
public class PayServiceImpl extends PayService{
private AccountRepository accountRepository;
private AuditMessageProducer auditMessageProducer;
private BusiSafeService busiSafeService;
private AccountTransferService accountTransferService;
public Result pay(Accout client,Account merchant,Money amount){
// 加载数据
Account clientAccount= accountRepository.find(client.getId());
Account merAccount= accountRepository.find(merchant.getId());
// 交易检查
Result preCheck = busiSafeService.checkBusi(client,merchant, money);
if(preCheck !=Result.SUCCESS){
return Result.REJECT;
}
//转账业务
accountTransferService.transfer(client,merchant,money);
// 保存数据
accountRepository.save(client);
accountRepository.save(merchant);
//发送审计消息
AuditMessage message = new AuditMessage(clientmerchant,money);
auditMessageProducer.send(message);
return Result.SUCCESS;
}
}同样的功能,这样重新编排后有什么好处?——针对开的四大问题
需求更容易梳理:业务逻辑纯净清晰,没有了业务逻辑与实现细节之间的复杂转换。
更容易单元测试:业务与基础设施隔离,没有基础设施,依然很容易设计单元测试案例。各个功能组件的依赖都是独立的,可以编写单元测试案例单独测试。
更容易开发:领域内服务自治,不用担心其他模块的影响。下单模块的Account与账户管理模块的Account属性与方法都可以完全不同,没有任何直接关联。
技术容易更新:业务与数据隔离很清晰,改ORM技术只需要改仓库层实现,对业务无影响
改造后组件间的依赖关系:
对于领域层的实体:不需要任何外部依赖,实体中有无外部逻辑都可以声明业务
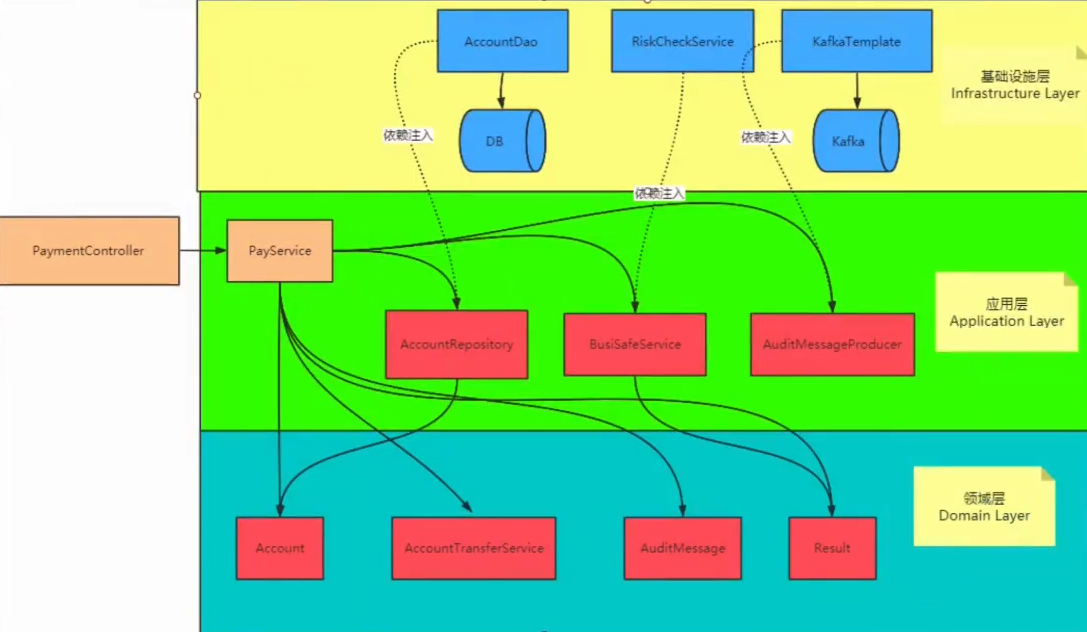
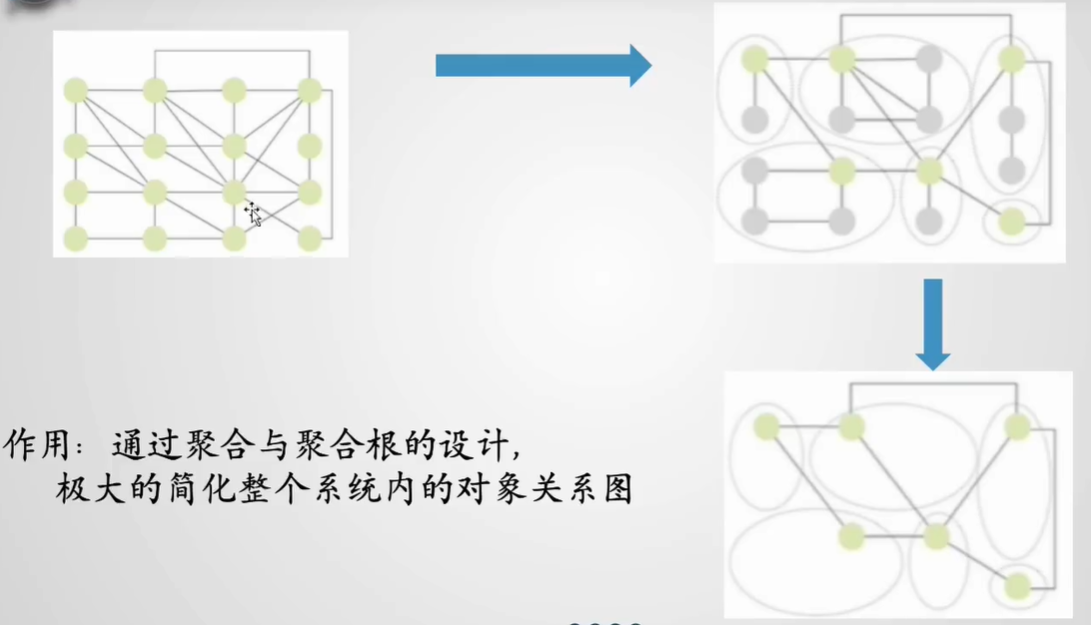
从以上改造可以看出,DDD有一个很大的弊端:类爆炸。
而解决类爆炸问题的,在DDD 中就有一个思想 —— 聚合
聚合
聚合的作用:聚合是用来确保这些领域对象在实现共同的业务逻辑时,能保证数据的一致性。
其实就是将同一个业务逻辑的 值对象和实体 看成一个整体,这个整体就称为聚合
每个聚合内部有一个外部访问聚合的唯一入口,称为聚合根。每个聚合中应确定唯一的聚合根实体,也就是领域内部唯一一个对外开放的访问接口 。这样就可以减少类之间的依赖关系。
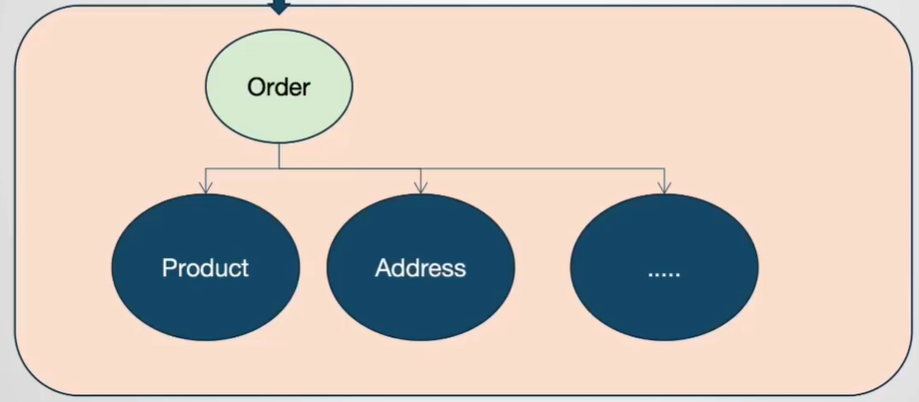
但是这样同时也带来了另一个问题:比如在订单场景下,想统计每一天卖出了多少商品,需要对卖出的商品数做一个排名。按照DDD的理解,Order是聚合根,product是Order中的一个属性,那就需要先统计Order订单,再从Order订单中统计product商品,再统计排名。
这里其实就涉及到DDD对于业务的理解。
领域之间的合作方式
有了领域划分后,就需要保证领域之间的边界。这个边界就是限界上下文(BoundedContext)。
限界上下文是一种概念,有很多种实现方式。在Java中可以落地为一层接口,以接口的方式 将领域的能力进行隔离和封装
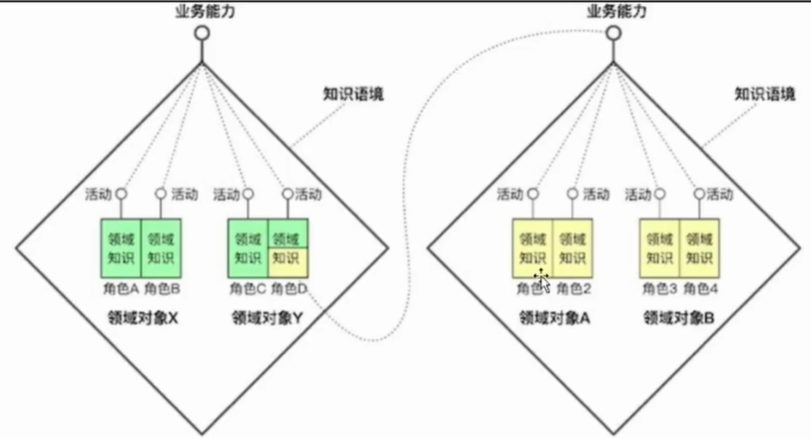
有了限界上下文的划分,单体、微服务、事件驱动这些架构就都只是领域之间不同的协作方式。而领域本身是保持稳定的。
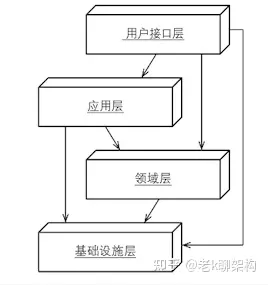
DDD推荐的架构模式
架构模式用于指导服务内的具体实现,对于服务内的逻辑分层,职能角色,依赖关系都有现实的指导意义。
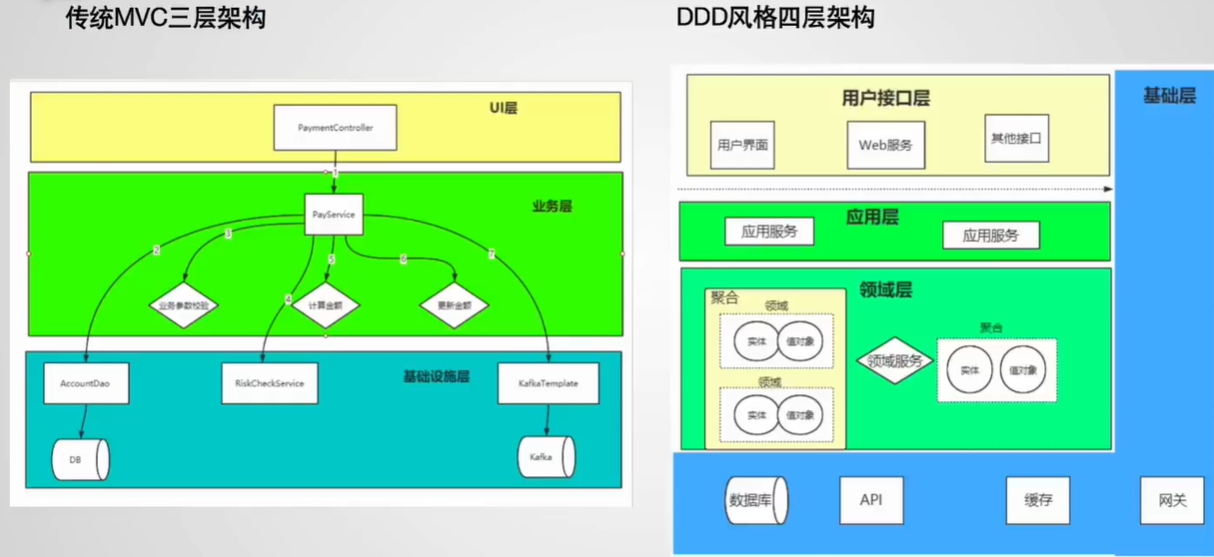
DDD分层
在一个典型的DDD分层架构中,分为用户界面层(Interfacce) , 应用层(Application), 领域层(Domain) ,基础设施层 (Infrastructure), 其中领域层是DDD分层架构中的核心,它是保存领域知识的地方。
分层架构的一个重要原则是:每层只能与位于其下方的层发生耦合。
在传统的DDD分层中,下图是他们的依赖关系。
如果没有使用过DDD可能对此理解不是很直观,可以将用户界面层想象为Controller,应用层与领域层想象为Service,基础设施层想象为Repository或者DAO,可能会好理解一些
可以看到,在传统的DDD分层架构中,基础层是被其它层所共同依赖的,它处于最底层,这可能导致重心偏移(想象一下在Service依赖DAO的场景),然而在DDD中领域层才是核心,因此要改变这种依赖。
如何改变这种依赖关系呢,在面向对象设计中有一种设计原则叫做依赖倒置原则( Dependence Inversion Principle,DIP)。
DIP的定义为:
高层模块不应该依赖于底层模块,二者都应该依赖于抽象。
抽象不应该依赖于细节,细节应该依赖于抽象。
根据DIP改进以后的架构如下图所示。
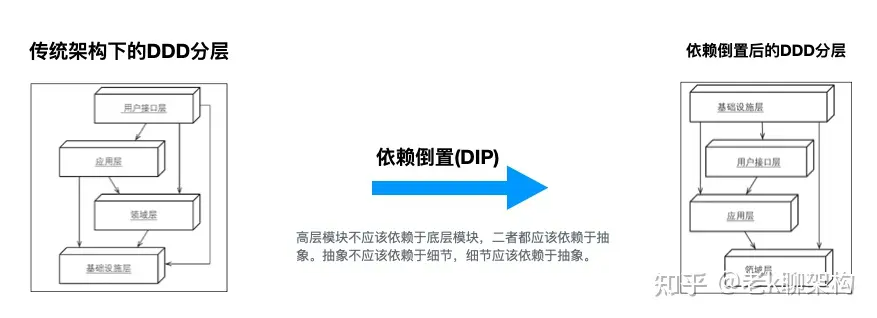
改进后的DDD分层,将整个依赖过程反过来了,但实际上仅仅是反过来了这么简单吗?在DIP的理论中,高层模块与低层模块是不相互依赖的,他们都依赖于一个抽象,那么这么看来,模块之间就不再是一种强耦合的关系了。
比如,在DIP之前,领域层直接依赖于基础设施层。
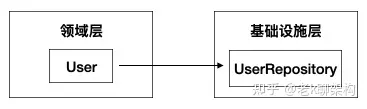
改进后,他们依赖于IUserRepository的抽象,抽象由基础层去实现,领域层并不关心如何实现。
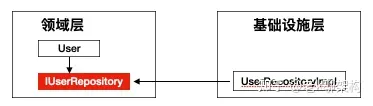
由此各模块可以对内实现强内聚对外提供松耦合依赖。
六边形架构(端口适配器架构)
六边形架构,对于每种外界类型,都有一个适配器与之相对应。业务核心逻辑被包裹在内部,外界通过应用层API与内部进行交互,内部的实现无须关注外部的变化,更加聚焦。在这种架构下还可以轻易地开发用于测试的适配器。
同时六边形架构又名“端口适配器架构”, 这里的端口不一定指传统意义上的服务端口,可以理解为一种通讯方式,比如在一个服务中,我们可能会提供给用户浏览器的基于HTTP的通讯方式,提供给服务内部的基于RPC的通讯方式,以及基于MQ的通讯方式等,适配器指的是用于将端口输入转换为服务内部接口可以理解的输入。
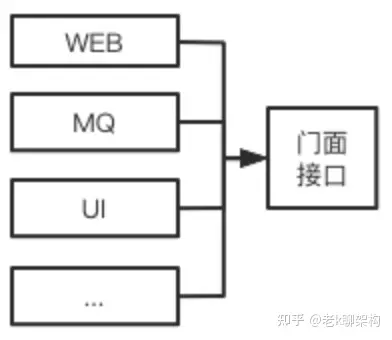
刚才我们讨论的是外部向领域服务内部输入部分的端口+适配器模式,同时输出时也同样,比如当我们的要将领域对象进行存储时,我们知道有各种各样的存储系统,比如Mysql、ES、Mongo等,假如说我们可以抽象出一个适配器,用于适配不同的存储系统,那么我们就可以灵活的切换不同的存储介质,这对于我们开发测试,以及重构都是很有帮助的,而在DDD中这个抽象的适配器就资源库。
理解到这些以后,我们来看下六边形架构的整体架构。
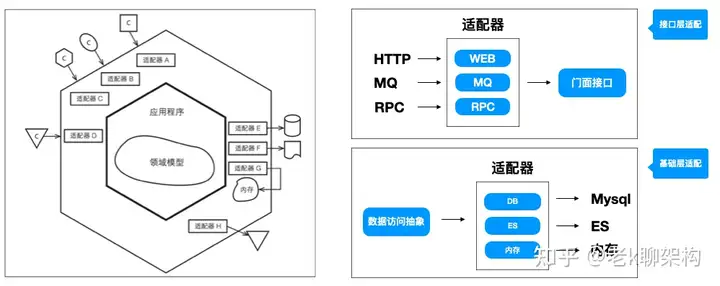
在此中架构下,业务层被聚焦在内部的六边形,内部的六边形不关心外部如何运作,只关注与内部的业务实现,这也是DDD推崇的方式,研发人员应该更关注于业务的实现也就是领域层的工作,而不是
聚焦在技术的实现。结合分层架构的思想,外部的六边形可以理解为接口层与基础层,内部理解为应用层与领域层,内部通过DIP与外部解耦。
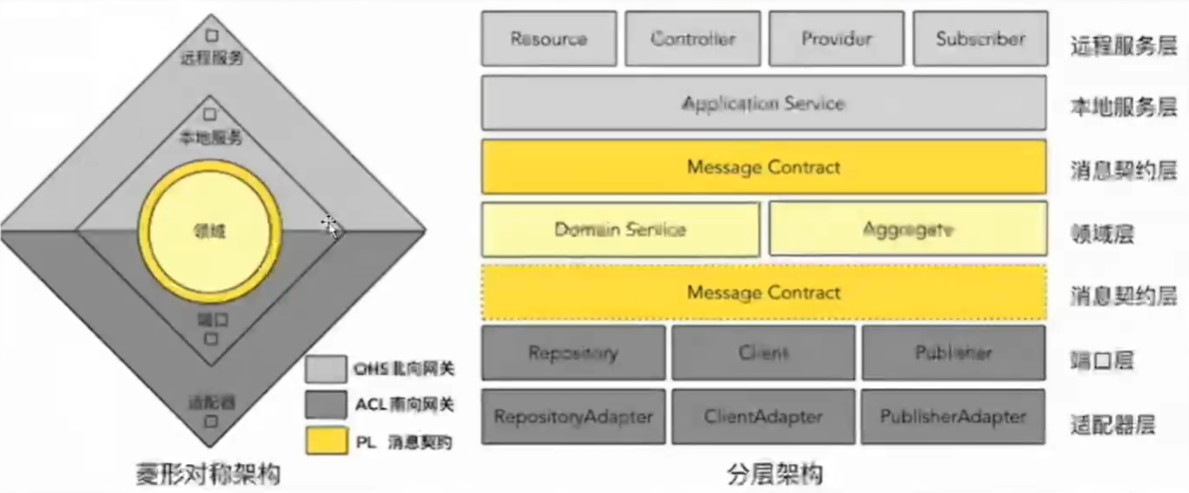
菱形编程模型
消息契约层:将充血实体 转换为 贫血POJO