一般来说,事务越大,拿到的锁就越多,因此死锁的可能性就越大。
Delete同一行记录造成的死锁
DELETE 流程
MySQL 以页作为数据的基本存储单位,每个页内包含两个主要的链表:正常记录链表和垃圾链表。每条记录都有一个记录头,记录头中包括一个关键属性——deleted_flag。
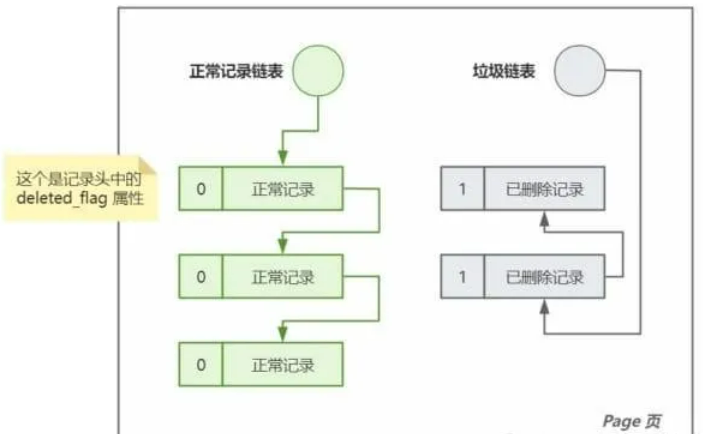
执行 DELETE 操作期间,系统首先将正常记录的记录头中的 delete_flag 标记设置为 1。这一步骤也被称为 delete mark,是数据删除流程的一部分。

在事务成功提交之后,由 purge 线程 负责对已标记为删除的数据执行逻辑删除操作。这一过程包括将记录从正常记录链表中移除,并将它们添加到垃圾链表中,以便后续的清理工作。

针对不同状态下的记录,MySQL 在加锁时采取不同的策略,特别是在处理唯一索引上记录的加锁情况。以下是具体的加锁规则:
- 正常记录: 对于未被标记为删除的记录,MySQL 会施加记录锁,以确保事务的隔离性和数据的一致性。
- delete mark: 当记录已被标记为删除(即 delete_flag 被设置为1),但尚未由 purge 线程清理时,MySQL 会对这些记录施加临键锁,以避免在清理前发生数据冲突。
- 已删除记录: 对于已经被 purge 线程逻辑删除的记录,MySQL 会施加间隙锁,这允许在已删除记录的索引位置插入新记录,同时保持索引的完整性和顺序性。
原因剖析
表 t_order_extra_item_15 具有一个由 (order_id, extra_key) 组成的联合唯一索引。两个事务分别执行以下语句:
| 事务A | 事务B | |
|---|---|---|
| 执行语句 | delete from t_order_extra_item_15 WHERE (order_id = xxx and extra_key = xxx) | delete from t_order_extra_item_15 WHERE (order_id = xxx and extra_key = xxx) |
| 持有锁 | lock_mode X locks rec but not gap(记录锁) | |
| 等待锁 | lock_mode X locks rec but not gap waiting(记录锁) | lock_mode X waiting(临键锁) |
事务 A 试图获取记录锁,但被事务 B 持有的相同的记录锁所阻塞。而且,事务 B 在尝试获取间隙锁时也遇到了阻塞,这是因为事务 A 先前已经请求了记录锁,从而形成了一种相互等待的状态,这种情况最终导致了死锁的发生。
然而事务 B 为何在已经持有记录锁的情况下还需要等待临键锁?唯一合理的解释是,在事务 B 最初执行 DELETE 操作时,它所尝试操作的记录已经被其他事务锁定。当这个其他事务完成了 delete mark 并提交后,事务 B 不得不重新发起对临键锁的请求。
经过深入分析得出结论,在并发环境中,必然存在另一个执行相同 DELETE 操作的事务,我们称之为事务 C。
通过仔细分析业务代码和服务日志,我们迅速验证了这一假设。现在,导致死锁的具体原因已经非常明显。为了帮助大家更好地理解三个事务的执行顺序,我们制定了一个事务执行时序的设想表格。
| 事务 A | 事务 B | 事务 C |
|---|---|---|
| 1. delete from t_order_extra_item_15 WHERE (order_id = xxx and extra_key = xxx ) ) 获取记录锁成功(*lock_mode X locks rec but not gap*) | ||
| 2. delete from t_order_extra_item_15 WHERE (order_id = xxx and extra_key = xxx ) ) 等待获取记录锁( *lock_mode X locks rec but not gap waiting*) | ||
| 3. delete from t_order_extra_item_15 WHERE (order_id = xxx and extra_key = xxx ) ) 等待获取记录锁( *lock_mode X locks rec but not gap waiting*) | ||
| 4. delete mark 设置记录头删除标识位 delete_flag=1 | ||
| 5. 事务提交 | ||
| 6. 获取记录锁成功 记录状态变更重新获取临键锁(*lock_mode X*) | ||
| 7. 发现死锁,回滚该事务 WE ROLL BACK TRANSACTION | ||
| 8. 事务提交 |
在执行流程的第 6 步中,事务 B 尝试重新获取临键锁,这时与事务 A 发生了相互等待的状况,导致死锁的发生。为解决这一问题,数据库管理系统自动回滚了事务 A,以打破死锁状态。
持有记录锁后再请求临键锁为什么需要等待?
因为在同一行记录上过去已经有事务在等待获取锁了,为了避免锁饥饿现象的发生,先前请求加锁的事务在锁释放后将获得优先权。分别执行 DELETE FROM t_lock where uniq = 5; 语句,实际操作结果如下;
| 事务 A | 事务 B |
|---|---|
| 1. delete from t_lock WHERE uniq = 5; 获取记录锁成功(*lock_mode X locks rec but not gap*) | |
| 2. delete mark 设置记录头删除标识位 delete_flag=1 | |
| 3. delete from t_lock WHERE uniq = 5; 等待获取临键锁( *lock_mode X waiting*) | |
| 4. delete from t_lock WHERE uniq = 5; 获取临键锁成功(*lock_mode X*) | |
| 5. 发现死锁,回滚该事务 WE ROLL BACK TRANSACTION | |
| 6. 事务提交 |
在操作流程的第四步中,事务 A 尝试请求对 uniq = 5 的临键锁,发现事务 B 已经先行一步请求了同一行记录上的临键锁。然而,事务 B 的这一请求由于事务 A 持有的记录锁而被阻塞,从而相互等待造成了死锁现象。
高版本的 MySQL 会存在 DELETE 死锁吗?
在 MySQL 环境 8.x 版本环境中,DELETE 操作引发的死锁情况得到了改进。通过观察加锁日志发现,事务在对于 delete mark 的记录加锁时,如果已经持有了该记录的记录锁,他将获取间隙锁而不是临键锁,这一变化有效避免了死锁的发生。
select for update造成的死锁
如何产生死锁的
假设一张订单表,其中 id 字段为主键索引,order_no 字段普通索引,也就是非唯一索引:里面有6条记录,如下所示
此时事务A和事务B分别执行以下语句
当事务A执行第一条语句时,事务 A 会在二级索引 order_no 上加上 next-key 锁,锁范围是(1006, +∞]。原因在于表中不存在1007的记录,为了防止幻读,会添加next-key 锁
select id from t_order where order_no = 1007 for update;而事务B执行这条语句时,同样事务 B 会在二级索引 order_no 上加上 next-key 锁,锁范围是(1006, +∞]。
原因在于表中不存在1008的记录,为了防止幻读,会添加next-key 锁
select id from t_order where order_no = 1008 for update;间隙锁的意义只在于阻止区间被插入,因此是可以共存的。一个事务获取的间隙锁不会阻止另一个事务获取同一个间隙范围的间隙锁。这里的这两个事务的锁是可以共存的
之后在事务A执行insert语句和事务B执行insert语句时,就都因为此时已有那个范围内的间隙锁而导致阻塞,最终两个事务都无法继续往下执行,导致死锁。
总结
SELECT FOR UPDATE 的加锁逻辑与 DELETE 语句的加锁逻辑是一致的。加锁的类型完全取决于被加锁记录的状态。都会存在死锁的问题。
只有唯一索引会引发此类死锁问题,主键索引和普通索引均不会。不同索引类型在索引等值加 X 锁情况下的行为如下:
| 主键索引 | 唯一索引 | 普通索引 | |
|---|---|---|---|
| 正常记录 | 记录锁 | 记录锁 | 临键锁 |
| delete mark | 记录锁 | 临键锁 | 临键锁 |
| 已删除记录 | 间隙锁 | 间隙锁 | 间隙锁 |
唯一索引在处理"正常记录"时施加的是记录锁,但在处理处于"delete mark"状态的记录时,它施加的是临键锁。这种加锁类型的不一致性,在执行并发的 DELETE 操作时,增加了导致死锁的风险。
如何避免死锁
- 设置事务等待锁的超时时间,破坏持有并等待条件。当一个事务的等待时间超过该值后,就对这个事务进行回滚,于是锁就释放了,另一个事务就可以继续执行了。在 InnoDB 中,参数 innodb_lock_wait_timeout 是用来设置超时时间的,默认值时 50 秒。
- 开启主动死锁检测。主动死锁检测在发现死锁后,主动回滚死锁链条中的某一个事务,让其他事务得以继续执行。将参数 innodb_deadlock_detect 设置为 on,表示开启这个逻辑,默认就开启。
