Spring基础
详情请查看:Spring概述
谈谈你对Spring的理解
可以从2个层面理解Spring:
- 首先Spring是一个生态:可以构建企业级应用程序所需的一切基础设施
- 但是,通常Spring指的就是Spring Framework,它有两大核心:
- IOC 和 DI 的支持 :Spring 的核心就是一个大的工厂容器,可以维护所有对象的创建和依赖关系,Spring 工厂用于生成 Bean,并且管理 Bean 的生命周期,实现高内聚低耦合的设计理念。
- AOP 编程的支持 :Spring 提供了面向切面编程,面向切面编程允许我们将横切关注点从核心业务逻辑中分离出来,实现代码的模块化和重用。可以方便的实现对程序进行权限拦截、运行监控、日志记录等切面功能。
除了这两大核心还提供了丰富的功能和模块, 数据访问、事务管理、Web开发等。数据访问模块提供了对数据库的访问支持,可以方便地进行数据库操作。事务管理模块提供了对事务的管理支持,确保数据的一致性和完整性。Web开发模块则提供了构建Web应用程序的工具和框架,简化了Web开发的过程。
总结一句话:它是一个轻量级、非入侵式的控制反转 (IoC) 和面向切面 (AOP) 的容器框架。
Spring的优点
- 通过控制反转和依赖注入实现松耦合。
- 支持面向切面的编程,并且把应用业务逻辑和系统服务分开。
- 通过切面和模板减少样板式代码。
- 声明式事务的支持。可以从单调繁冗的事务管理代码中解脱出来,通过声明式方式灵活地进行事务的管理,提高开发效率和质量。
- 方便集成各种优秀框架。内部提供了对各种优秀框架的直接支持(如:Hessian、Quartz、MyBatis等)。
- 方便程序的测试。Spring支持Junit4,添加注解便可以测试Spring程序。
看过源码吗?说下 Spring 由哪些重要的模块组成?
Core Container(核心容器):
- Spring Core:提供了依赖注入(Dependency Injection,Dl)和控制反转(hnversion of control,loC)的实现,所有其他Spring模块的基础,别的模块都会依赖此模块。
- Spring Bean:负责管理Bean的定义和生命周期。通过 IOC 容器完成Bean的创建、依赖注入、初始化、销毁等操作。
- Spring Context:基于Core和Beans的高级容器,提供了类似 JNDI 的上下文功能,还包含了国际化、事件传播、资源访问等功能。
- Spring Expression Language(SpEL):一个强大的表达式语言,用于在运行时查询和操作对象的值
AOP(面向切面编程):
- Spring AOP:提供面向切面编程的功能,可以在方法执行前后或抛出异常时动态插入额外的逻辑,比如日志记录、权限验证、事务管理等。
Data Access(数据访问)
- Spring JDBC:简化了原生JDBC的操作,提供模板方法来管理连接、资源的释放和异常处理
- Spring ORM:支持与主流ORM框架(如Hibernate、JPA、MyBatis等)集成,简化持久层开发。
- Spring Transaction(事务管理):提供声明式和编程式的事务管理机制,与数据库操作密切结合。
Web层:
- Spring Web:提供基础的Web开发支持,包括ServletAPI的集成,适用于构建MVC架构。
- Spring MVC:实现了Model-View-Controler(MVC)模式的框架,用于构建基于HTTP清求的Web应用。它是一个常用的模块,支持注解驱动的Web开发。
- Spring WebFlux:提供基于Reactive Streams的响应式编程模型,专为高并发的异步非阻塞请求设计。
主要回答下核心模块,然后带一下切面、数据访问或者 web 相关的即可。
Spring 用到了哪些设计模式?
1、简单工厂模式:BeanFactory就是简单工厂模式的体现,根据传入一个唯一标识来获得 Bean 对象。
@Override
public Object getBean(String name) throws BeansException {
assertBeanFactoryActive();
return getBeanFactory().getBean(name);
}2、工厂方法模式:FactoryBean就是典型的工厂方法模式。spring在使用getBean()调用获得该bean时,会自动调用该bean的getObject()方法。每个 Bean 都会对应一个 FactoryBean,如 SqlSessionFactory 对应 SqlSessionFactoryBean。
3、单例模式:一个类仅有一个实例,提供一个访问它的全局访问点。Spring 创建 Bean 实例默认是单例的。
4、代理模式:spring 的 aop 使用了动态代理,有两种方式JdkDynamicAopProxy和Cglib2AopProxy。
5、观察者模式:spring 中 observer 模式常用的地方是 listener 的实现,如ApplicationListener。
6、装饰器模式: Spring的BeanWrapper允许在不修改原始Bean类的情况下添加额外的功能,这是装饰器模式的实际应用。
7、策略模式:Spring允许使用策略模式来定义包扫描时的过滤策略,如在@ComponentScan注解中使用的excludeFilters和includeFilters。
8、模板模式: Spring框架的许多模块和外部扩展都采用模板方法模式,例如JdbcTemplate、HibernateTemplate等。
9、责任链模式: Spring AOP通过责任链模式实现通知(Advice)的调用,确保通知按顺序执行。
10、适配器模式:SpringMVC中的适配器HandlerAdatper。由于应用会有多个Controller实现,如果需要直接调用Controller方法,那么需要先判断是由哪一个Controller处理请求,然后调用相应的方法。当增加新的 Controller,需要修改原来的逻辑,违反了开闭原则(对修改关闭,对扩展开放)。
为此,Spring提供了一个适配器接口,每一种 Controller 对应一种 HandlerAdapter 实现类,当请求过来,SpringMVC会调用getHandler()获取相应的Controller,然后获取该Controller对应的 HandlerAdapter,最后调用HandlerAdapter的handle()方法处理请求,实际上调用的是Controller的handleRequest()。每次添加新的 Controller 时,只需要增加一个适配器类就可以,无需修改原有的逻辑。
常用的处理器适配器:SimpleControllerHandlerAdapter,HttpRequestHandlerAdapter,AnnotationMethodHandlerAdapter。
// Determine handler for the current request.
mappedHandler = getHandler(processedRequest);
HandlerAdapter ha = getHandlerAdapter(mappedHandler.getHandler());
// Actually invoke the handler.
mv = ha.handle(processedRequest, response, mappedHandler.getHandler());
public class HttpRequestHandlerAdapter implements HandlerAdapter {
@Override
public boolean supports(Object handler) {//handler是被适配的对象,这里使用的是对象的适配器模式
return (handler instanceof HttpRequestHandler);
}
@Override
@Nullable
public ModelAndView handle(HttpServletRequest request, HttpServletResponse response, Object handler)
throws Exception {
((HttpRequestHandler) handler).handleRequest(request, response);
return null;
}
}Spring事件监听的核心机制是什么?
Spring事件监听的核心机制围绕观察者模式展开:
观察者模式: 它允许一个对象(称为主题或被观察者)维护一组依赖于它的对象(称为观察者),并在主题状态发生变化时通知观察者。
包含三个核心:
- 事件: 事件是观察者模式中的主题状态变化的具体表示,它封装了事件发生时的信息。在Spring中,事件通常是普通的Java对象,用于传递数据或上下文信息。
- 事件发布者: 在Spring中,事件发布者充当主题的角色,负责触发并发布事件。它通常实现了ApplicationEventPublisher接口或使用注解@Autowired来获得事件发布功能。
- 事件监听器: 事件监听器充当观察者的角色,负责监听并响应事件的发生。它实现了ApplicationListener接口,通过onApplicationEvent()方法来处理事件。
总之,Spring事件监听机制的核心机制是观察者模式,通过事件、事件发布者和事件监听器的协作,实现了松耦合的组件通信,使得应用程序更加灵活和可维护。
说说你对设计模式的理解
设计模式是一套经过验证的、被广泛应用于软件开发中的解决特定问题的重复利用的方案集合。它们是在软件开发领域诸多经验的基础上总结出来的,是具有普适性、可重用性和可扩展性的解决方案。
设计模式通过抽象、封装、继承、多态等特性帮助我们设计出高质量、易扩展、易重构的代码,遵循面向对象的设计原则,如单一职责、开闭原则、依赖倒置、里氏替换等,从而提高代码的可维护性、可测试性和可读性。
设计模式的优点在于它们已经被广泛验证,可以避免一些常见的软件开发问题,同时也提供了一种标准化的方案来解决这些问题。使用设计模式可以提高代码的复用性,减少代码的重复编写,增加代码的灵活性和可扩展性。设计模式还能降低项目的风险,提高系统的稳定性。
不过,设计模式不是万能的,对于简单的问题,可能会使代码变得过于复杂,甚至导致反效果。
在使用设计模式时,需要根据具体的问题需求和实际情况来选择合适的模式,避免滥用模式,并保持代码的简洁、清晰和可读性。
Spring IOC
详情请查看:Spring IOC
什么是IOC?
IOC:控制反转, 是一种设计思想,而不是一个具体的技术实现。IoC 并非 Spring 特有,在其他语言中也有应用。它是通过依赖注入(DependencyInjection)实现的。
- 核心思想:由Spring容器管理bean的整个生命周期。通过反射实现对其他对象的控制,包括初始化、创建、销毁等,解放手动创建对象的过程,同时降低类之间的耦合度。
- 依赖注入:通过构造器注入、setter 注入或接口注入,将对象所需的依赖传递给它,而不是让对象自行创建依赖。
为什么叫控制反转?
- 控制:指的是对象创建(实例化、管理)的权力
- 反转:控制权交给外部环境(Spring 框架、IoC 容器)
到底控制的是什么?其实就是控制对象的创建,IOC容器根据配置文件来创建对象,在对象的生命周期内,在不同时期根据不同配置进行对象的创建和改造,。
那什么被反转了?其实就是关于创建对象且注入依赖对象的这个动作,本来这个动作是由我们程序员在代码里面指定的,例如对象A依赖对象B,在创建对象A代码里,我们需要写好如何创建对象B,这样才能构造出一个完整的 A。而反转之后,这个动作就由 IOC 容器触发,IOC 容器在创建对象 A 的时候,发现依赖对象 B,根据配置文件,它会创建 B,并将对象 B 注入 A 中。这里要注意,注入的不一定非得是一个对象,也可以注入配置文件里面的一个值给对象 A 等等。
IOC的好处?
ioc的思想最核心的地方在于,资源不由使用资源者管理,而由不使用资源的第三方管理,这可以带来很多好处。
- 资源集中管理,实现资源的可配置和易管理。
- 降低类之间的耦合度。
比如在实际项目中一个 Service 类可能依赖了很多其他的类,假如我们需要实例化这个 Service,可能要每次都要搞清这个 Service 所有底层类的构造函数,这就变得复杂了。而如果使用 IoC 的话,只需要配置好,然后在需要的地方引用就行了,这大大增加了项目的可维护性且降低了开发难度
什么是 Spring Bean?
简单来说,Bean 代指的就是那些被 IoC 容器所管理的对象。
我们需要告诉 IoC 容器管理哪些对象,这个是通过配置元数据来定义的。配置元数据可以是 XML 文件、注解或者 Java 配置类。
什么是依赖注入?
Dl(Dependengy Injecion,依赖注入)普遍认为是 Spng框架中用于实现控制反转(IOC)的一种机制。DI的核心思想是由容器负责对象的依赖注入,而不是由对象自行创建或查找依赖对象。
通过 Dl,Spring 容器在创建一个对象时,会自动将这个对象的依赖注入进去,这样可以让对象与其依赖的对象解耦,提升系统的灵活性和可维护性。
依赖注入主要有两种方式:构造器注入和属性注入。
Spring自动装配的方式有哪些?
- setter方式注入
在基于 setter 的依赖注入中,setter 方法被标注为 @Autowired。一旦使用无参数构造函数或无参数静态工厂方法实例化 Bean,为了注入 Bean 的依赖项,Spring 容器将调用这些 setter 方法。
- 基于属性的依赖注入
在基于属性的依赖注入中,以@Autowired(自动注入)注解注入为例,修饰符有三个属性:Constructor,byType,byName。默认按照byType注入。一旦类被实例化,Spring 容器将设置这些字段。
- constructor:通过构造方法进行自动注入,spring会匹配与构造方法参数类型一致的bean进行注入,如果有一个多参数的构造方法,一个只有一个参数的构造方法,在容器中查找到多个匹配多参数构造方法的bean,那么spring会优先将bean注入到多参数的构造方法中。
- byName:被注入bean的id名必须与set方法后半截匹配,并且id名称的第一个单词首字母必须小写,这一点与手动set注入有点不同。
- byType:查找所有的set方法,将符合参数类型的bean注入。
- 构造器注入
在基于构造函数的依赖注入中,类构造函数被标注为 @Autowired,并包含了许多与要注入的对象相关的参数。
Spring Bean 注册到容器有哪些方式?
Spring Bean 注册到容器的方式主要包括以下几种:
- 基于 XML的配置:使用 XML 文件配置 Bean,并定义 Bean 的依赖关系。
- 基于 @Compoment 注解及其衍生注解,如 @Controller、@Repository、@Service 等进行配置。
- 使用 @configuration 注解声明配置类,并使用@Bean 注解定义 Bean。
- 基于 @Import 注解:可以将普通类导入到 Spring 容器中,这些类会自动被注册为 Bean。
基于属性的依赖注入可能存在什么问题吗?
- 不允许声明不可变域:基于字段的依赖注入在声明为 final/immutable 的字段上不起作用,因为这些字段必须在类实例化时实例化。声明不可变依赖项的唯一方法是使用基于构造器的依赖注入。
- 容易违反单一职责设计原则:使用基于字段的依赖注入,高频使用的类随着时间的推移,会在类中逐渐添加越来越多的依赖项,用着很爽,但很容易忽略类中的依赖已经太多了。但是如果使用基于构造函数的依赖注入,随着越来越多的依赖项被添加到类中,构造函数会变得越来越大,一眼就可以察觉到哪里不对劲。
有一个有超过10个参数的构造函数是一个明显的信号,表明类已经转变一个大而全的功能合集,需要将类分割成更小、更容易维护的块。
因此,尽管属性注入并不是破坏单一责任原则的直接原因,但它隐藏了信号,使我们很容易忽略这些信号。 - 与依赖注入容器紧密耦合:
使用基于字段的依赖注入的主要原因是为了避免 getter 和 setter 的样板代码或为类创建构造函数。最后,这意味着设置这些字段的唯一方法是通过Spring容器实例化类并使用反射注入它们,否则字段将保持 null。
依赖注入设计模式将类依赖项的创建与类本身分离开来,并将此责任转移到类注入容器,从而允许程序设计解耦,并遵循单一职责和依赖项倒置原则(同样可靠)。因此,通过自动装配(Autowired)字段来实现的类的解耦,最终会因为再次与类注入容器(在本例中是 Spring)耦合而丢失,从而使类在Spring容器之外变得无用。
这意味着,如果想在应用程序容器之外使用您的类,例如用于单元测试,将被迫使用 Spring 容器来实例化您的类,因为没有其他可能的方法(除了反射)来设置自动装配字段。 - 隐藏依赖关系:在使用依赖注入时,受影响的类应该使用公共接口清楚地公开这些依赖项,方法是在构造函数中公开所需的依赖项,或者使用方法(setter)公开可选的依赖项。当使用基于字段的依赖注入时,实质上是将这些依赖对外隐藏了。
为什么建议使用构造器注入
- 依赖不可变:其实说的就是final关键字。
- 依赖不为空:(省去了我们对其检查):当要实例化UserServiceImpl的时候,由于自己实现了有参数的构造函数,所以不会调用默认构造函数,那么就需要Spring容器传入所需要的参数,所以就两种情况:1、有该类型的参数->传入,OK 。2:无该类型的参数->报错。
- 完全初始化的状态:这个可以跟上面的依赖不为空结合起来,向构造器传参之前,要确保注入的内容不为空,那么肯定要调用依赖组件的构造方法完成实例化。而在Java类加载实例化的过程中,构造方法是最后一步(之前如果有父类先初始化父类,然后自己的成员变量,最后才是构造方法),所以返回来的都是初始化之后的状态。
如果使用setter注入,缺点显而易见,对于IOC容器以外的环境,除了使用反射来提供它需要的依赖之外,无法复用该实现类。而且将一直是个潜在的隐患,因为你不调用将一直无法发现NPE的存在
// 这里只是模拟一下,正常来说我们只会暴露接口给客户端,不会暴露实现。
UserServiceImpl userService = newUserServiceImpl();
userService.findUserList();// -> NullPointerException, 潜在的隐患总结:对于必需的依赖,建议使用基于构造函数的注入,设置它们为不可变的,并防止它们为 null。对于可选的依赖项,建议使用基于 setter 的注入。
注入 Bean 的注解有哪些?
Spring 内置的 @Autowired 以及 JDK 内置的 @Resource 和 @Inject 都可以用于注入 Bean。
| Annotation | Package | Source |
|---|---|---|
@Autowired | org.springframework.bean.factory | Spring 2.5+ |
@Resource | javax.annotation | Java JSR-250 |
@Inject | javax.inject | Java JSR-330 |
@Autowired 和@Resource使用的比较多一些。
@Autowired和@Resource以及@Inject等注解注的区别
- @Autowired是Spring自带的注解,通过AutowiredAnnotationBeanPostProcessor 类实现的依赖注入
- @Autowired可以作用在CONSTRUCTOR、METHOD、PARAMETER、FIELD、ANNOTATION_TYPE
- @Autowired默认是根据类型(byType )进行自动装配的
- 如果有多个类型一样的Bean候选者,需要指定按照名称(byName )进行装配,则需要配合 @Qualifier。
指定名称后,如果Spring IOC容器中没有对应的组件bean抛出NoSuchBeanDefinitionException。也可以将@Autowired中required配置为false,如果配置为false之后,当没有找到相应bean的时候,系统不会抛异常
@Qualifier 注解有什么作用
当需要创建多个相同类型的 bean 并希望仅使用属性装配其中一个 bean 时,可以使用@Qualifier 注解和 @Autowired 通过指定应该装配哪个 bean 来消除歧义。
为什么不推荐使用 @Autowired ?
因为 Spring 官方实际上推荐的是构造器注入,而不是字段注入
且 @Autowired 实际上 Sping提供的,导致了业务代码和框架绑定,如果更换给其他 IOC 框架则不适用了,而 @Resource 是 ISR-250 提供的,它是 Java 的标准,因此如果非要使用字段注入也应该使用 @Resource。
详情可以看这篇文章:基于属性的依赖注入
将一个类声明为 Bean 的方式有哪些?
- 使用xml方式来声明Bean的定义,Spring容器在启动会加载并解析这个xml,把bean装载到IOC容器中
- 使用@CompontScan注解来扫描声明了@Controller、@Service、@Repository、@Component注解的类
- 使用@Configuration注解声明配置类,并使用@Bean注解实现Bean的定义,这种方式其实是xml配置方式的一种演变,是Spring迈入到无xml 时代的里程碑
- 使用@Import注解,导入配置类或者普通的Bean
- 使用FactoryBean工厂bean, 动态构建一个Bean实例,Spring Cloud OpenFeign 里面的动态代理实例就是使用FactoryBean来实现的
- 实现ImportBeanDefinitionRegistrar接口,可以动态注入Bean实例。这个在Spring Boot里面的启动注解有用到
- 实现ImportSelector接口,动态批量注入配置类或者Bean对象,这个在Spring Boot里面的自动装配机制里面有用到
@Component 和 @Bean 的区别是什么?
@Component注解作用于类,而@Bean注解作用于方法。@Component通常是通过类路径扫描来自动侦测以及自动装配到 Spring 容器中(我们可以使用@ComponentScan注解定义要扫描的路径从中找出标识了需要装配的类自动装配到 Spring 的 bean 容器中)。@Bean注解通常是我们在标有该注解的方法中定义产生这个 bean,@Bean告诉了 Spring 这是某个类的实例,当我需要用它的时候还给我。@Bean注解比@Component注解的自定义性更强,而且很多地方我们只能通过@Bean注解来注册 bean。比如当我们引用第三方库中的类需要装配到Spring容器时,则只能通过@Bean来实现。
@Component、@Controller、@Repository和@Service 的区别?
它们本质上没区别,其它三个都是 @Component 的衍生注解,之所以做了这些划分主要是为了更好地组织和管理应用的各个层次,提高代码的可读性和可维护性。
- @Component:最普通的组件,可以被注入到spring容器进行管理。
- @Controller:将类标记为 Spring Web MVC 控制器。
- @Service:将类标记为业务层组件。
- @Repository:将类标记为数据访问组件,即DAO组件。
IOC容器初始化过程?
- 从XML中读取配置文件。
- 将bean标签解析成 BeanDefinition,如解析 property 元素, 并注入到 BeanDefinition 实例中。
- 将 BeanDefinition 注册到容器 BeanDefinitionMap 中。
- BeanFactory 根据 BeanDefinition 的定义信息创建实例化和初始化 bean。
单例bean的初始化以及依赖注入一般都在容器初始化阶段进行,只有懒加载(lazy-init为true)的单例bean是在应用第一次调用getBean()时进行初始化和依赖注入。
// AbstractApplicationContext
// Instantiate all remaining (non-lazy-init) singletons.
finishBeanFactoryInitialization(beanFactory);多例bean 在容器启动时不实例化,即使设置 lazy-init 为 false 也没用,只有调用了getBean()才进行实例化。
loadBeanDefinitions采用了模板模式,具体加载 BeanDefinition 的逻辑由各个子类完成。
Bean的生命周期
了解 Spring 生命周期的意义就在于,可以利用 Bean 在其存活期间的指定时刻完成一些相关操作,即扩展点。这种时刻可能有很多,但一般情况下,会在 Bean 被初始化后和被销毁前执行一些相关操作。具体扩展点的使用可以看这篇文章。
简洁面试版:
- 实例化
- 通过反射去推断构造函数进行实例化
- 实例工厂、 静态工厂
- 依赖注入(DI)
- 解析自动装配(byname bytype constractor none @Autowired)
- 属性赋值(Populate Properties):Spring容器将Bean的属性值通过setter方法或其他方式进行赋值。
- 初始化
- 调用很多Aware回调方法 (初始化前的扩展机制)
- 调用BeanPostProcessor.postProcessBeforeInitialization (初始化前)
- 调用生命周期回调初始化方法
- 调用BeanPostProcessor.postProcessAfterInitialization, 如果bean实现aop则会在这里创建动态代理 (初始化后)
- 使用
- 销毁
- 在spring容器关闭的时候进行调用
- 调用生命周期回调销毁方法
详细版:
- 加载Bean定义:通过 loadBeanDefinitions 扫描所有xml配置、注解将Bean记录在beanDefinitionMap中。即IOC容器的初始化过程
- Bean实例化:遍历 beanDefinitionMap 创建bean,最终会使用getBean中的doGetBean方法调用 createBean来创建Bean对象
- 构建对象:容器通过 createBeanInstance 进行对象构造
- 获取构造方法(大部分情况下只有一个构造方法)
- 如果只有一个构造方法,无论这个构造方法有没有入参,都用这个构造方法
- 有多个构造方法时
- 先拿带有@Autowired的构造方法,但是如果多个构造方法都有@Autowired就会报错
- 如果没有带有@Autowired的构造方法,那就找没有入参的;如果多个构造方法都是有入参的,那也会报错
- 准备参数
- 先根据类进行查找
- 如果这个类有多个实例,则再根据参数名匹配
- 如果没有找到则报错
- 构造对象:无参构造方法则直接实例化
- 获取构造方法(大部分情况下只有一个构造方法)
- 填充属性:通过populateBean方法为Bean内部所需的属性进行赋值,通常是 @Autowired 注解的变量;通过三级缓存机制进行填充,也就是依赖注入
- 初始化Bean对象:通过initializeBean对填充后的实例进行初始化
- 执行Aware:检查是否有实现者三个Aware:
BeanNameAware,BeanClassLoaderAware,BeanFactoryAware;让实例化后的对象能够感知自己在Spring容器里的存在的位置信息,创建信息 - 初始化前:BeanPostProcessor,也就是拿出所有的后置处理器对bean进行处理,当有一个处理器返回null,将不再调用后面的处理器处理。
- 初始化:afterPropertiesSet,init- method;
- 实现了InitializingBean接口的类执行其afterPropertiesSet()方法
- 从BeanDefinition中获取initMethod方法
- 初始化后:BeanPostProcessor,;获取所有的bean的后置处理器去执行。AOP也是在这里做的
- 执行Aware:检查是否有实现者三个Aware:
- 注册销毁:通过reigsterDisposableBean处理实现了DisposableBean接口的Bean的注册
- Bean是否有注册为DisposableBean的资格:
- 是否有destroyMethod。
- 是否有执行销毁方法的后置处理器。
- DisposableBeanAdapter: 推断destoryMethod
- 完成注册
- Bean是否有注册为DisposableBean的资格:
- 构建对象:容器通过 createBeanInstance 进行对象构造
- 添加到单例池:通过 addSingleton 方法,将Bean 加入到单例池 singleObjects
- 销毁
- 销毁前:如果有@PreDestory 注解的方法就执行
- 如果有自定义的销毁后置处理器,通过 postProcessBeforeDestruction 方法调用destoryBean逐一销毁Bean
- 销毁时:如果实现了destroyMethod就执行 destory方法
- 执行客户自定义销毁:调用 invokeCustomDestoryMethod执行在Bean上自定义的destroyMethod方法
- 有这个自定义销毁就会执行
- 没有自定义destroyMethod方法就会去执行close方法
- 没有close方法就会去执行shutdown方法
- 都没有的话就都不执行,不影响
BeanFactory和FactoryBean的区别?
BeanFactory:管理Bean的容器,Spring中生成的Bean都是由这个接口的实现来管理的。
- 核心概念:Beanfactory负责从配置源(XML、Java 配置类、注解等)中读取 Bean 的定义,并负责创建、管理这些 Bean 的生命周期。
- 延迟加载:Beanfactory的一个重要特性是延迟初始化,即它只会在 Bean 首次请求时才会实例化该 Bean,而不是在容器启动时就立即创建所有的 Bean。
不过 BeanFactory 本身只是一个接口,一般我们所述的 BeanFactory 指的是它实现类
- DefaultListableBeanFactory:Beanfactory的默认实现,通常用于内部处理 Bean 的实例化和管理工作。它支持所有基本的依赖注入特性,如构造器注入、setter 注入等
- XmlBeanFactory(已废弃):基于XML 文件配置的 Beanfactory实现,已经在 Spring 3.x中被淘汰,现推荐使用 ApplicationContext,
FactoryBean:通常是用来创建比较复杂的bean,一般的bean 直接用xml配置即可,但如果一个bean的创建过程中涉及到很多其他的bean 和复杂的逻辑,直接用xml配置比较麻烦,这时可以考虑用FactoryBean,可以隐藏实例化复杂Bean的细节。
- 核心概念:FactoryBean 是一个实现了
FactoryBean<T>接口的 Bean,通过它可以自定义复杂对象的创建逻辑。Spring 容器会调用 getobject()方法来获取实际的 Bean 实例 - 使用场景:FactoryBean 通常用于需要创建复杂对象或需要使用代理模式生成 Bean 的场景
当配置文件中bean标签的class属性配置的实现类是FactoryBean时,通过 getBean()方法返回的不是FactoryBean本身,而是调用FactoryBean#getObject()方法所返回的对象,相当于FactoryBean#getObject()代理了getBean()方法。如果想得到FactoryBean必须使用 '&' + beanName 的方式获取。
Mybatis 提供了 SqlSessionFactoryBean,可以简化 SqlSessionFactory的配置:
public class SqlSessionFactoryBean implements FactoryBean<SqlSessionFactory>, InitializingBean, ApplicationListener<ApplicationEvent> {
@Override
public void afterPropertiesSet() throws Exception {
notNull(dataSource, "Property 'dataSource' is required");
notNull(sqlSessionFactoryBuilder, "Property 'sqlSessionFactoryBuilder' is required");
state((configuration == null && configLocation == null) || !(configuration != null && configLocation != null),
"Property 'configuration' and 'configLocation' can not specified with together");
this.sqlSessionFactory = buildSqlSessionFactory();
}
protected SqlSessionFactory buildSqlSessionFactory() throws IOException {
//复杂逻辑
}
@Override
public SqlSessionFactory getObject() throws Exception {
if (this.sqlSessionFactory == null) {
afterPropertiesSet();
}
return this.sqlSessionFactory;
}
}在 xml 配置 SqlSessionFactoryBean:
<bean id="tradeSqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="trade" />
<property name="mapperLocations" value="classpath*:mapper/trade/*Mapper.xml" />
<property name="configLocation" value="classpath:mybatis-config.xml" />
<property name="typeAliasesPackage" value="com.bytebeats.mybatis3.domain.trade" />
</bean>Spring 将会在应用启动时创建 SqlSessionFactory,并使用 sqlSessionFactory 这个名字存储起来。
Spring 中的 ObjectFactory 是什么?
ObjectFactory是 Spring 框架中的一个接口,主要用于延迟获取 Bean 实例。
ObjectFactory 提供了一种延迟加载的机制,它通过 getObject() 方法返回一个 Bean的实例,使用 ObjectFactory 可以避免在容器启动时立即创建所有 Bean,即只有在真正需要使用 Bean 时才会从 Spring容器中获取Bean 实例,有助于优化性能。
Spring 中的 ApplicationContext 是什么?
ApplicationContext 是多个底层接口组合后的接口。它主要提供了五大功能.
- 核心容器 BeanFactory
- 国际化 MessageSource
- 资源获取 ResourceLoader
- 环境信息 EnvironmentCapable
- 事件发布 ApplicationEventPublisher
BeanFactory和ApplicationContext有什么区别?
BeanFactory和ApplicationContext是Spring的两大核心接口,都可以当做Spring的容器。其中ApplicationContext是BeanFactory的子接口。
两者区别如下:
1、功能上的区别。BeanFactory是Spring里面最底层的接口,包含了各种Bean的定义,读取bean配置文档,管理bean的加载、实例化,控制bean的生命周期,维护bean之间的依赖关系。
ApplicationContext接口作为BeanFactory的派生,除了提供BeanFactory所具有的功能外,还提供了更完整的框架功能,如继承MessageSource、支持国际化、统一的资源文件访问方式、同时加载多个配置文件等功能。
2、加载方式的区别。BeanFactroy采用的是延迟加载形式来注入Bean的,即只有在使用到某个Bean时(调用getBean()),才对该Bean进行加载实例化。这样,我们就不能发现一些存在的Spring的配置问题。如果Bean的某一个属性没有注入,BeanFacotry加载后,直至第一次使用调用getBean方法才会抛出异常。
而ApplicationContext是在容器启动时,一次性创建了所有的Bean。这样,在容器启动时,我们就可以发现Spring中存在的配置错误,这样有利于检查所依赖属性是否注入。 ApplicationContext启动后预载入所有的单例Bean,那么在需要的时候,不需要等待创建bean,因为它们已经创建好了。
相对于基本的BeanFactory,ApplicationContext 唯一的不足是占用内存空间。当应用程序配置Bean较多时,程序启动较慢。
3、创建方式的区别。BeanFactory通常以编程的方式被创建,ApplicationContext还能以声明的方式创建,如使用ContextLoader。
4、注册方式的区别。BeanFactory和ApplicationContext都支持BeanPostProcessor、BeanFactoryPostProcessor的使用,但两者之间的区别是:BeanFactory需要手动注册,而ApplicationContext则是自动注册。
Bean的作用域
- singleton:单例,Spring中的bean默认都是单例的。
- prototype:每次请求都会创建一个新的bean实例。
- request:每一次HTTP请求都会产生一个新的bean,该bean仅在当前HTTP request内有效。
- session:每一次HTTP请求都会产生一个新的bean,该bean仅在当前HTTP session内有效。
- global-session:全局session作用域。
- websocket (仅 Web 应用可用):每一次 WebSocket 会话产生一个新的 bean。
Bean 是线程安全的吗?
Spring 框架中的 Bean 是否线程安全,取决于其作用域和状态。
我们这里以最常用的两种作用域 prototype 和 singleton 为例介绍。几乎所有场景的 Bean 作用域都是使用默认的 singleton ,重点关注 singleton 作用域即可。
prototype 作用域下,每次获取都会创建一个新的 bean 实例,不存在资源竞争问题,所以不存在线程安全问题。singleton 作用域下,IoC 容器中只有唯一的 bean 实例,可能会存在资源竞争问题(取决于 Bean 是否有状态)。如果这个 bean 是有状态的话,那就存在线程安全问题(有状态 Bean 是指包含可变的成员变量的对象)。
不过,大部分 Bean 实际都是无状态(无状态就是不包含可变的成员变量)的(比如 Dao、Service),这种情况下,虽然说它本身不是线程安全的,但是只是调用了其中的方法,不会造成线程安全问题。
对于有状态单例 Bean 的线程安全问题,常见的有两种解决办法:
- 在 Bean 中尽量避免定义可变的成员变量:确保单例 Bean 是无状态的或仅使用线程安全的数据结构
- 在类中定义一个
ThreadLocal成员变量,将需要的可变成员变量保存在ThreadLocal中(推荐的一种方式)。 - 加锁:如果需要在单例 Bean 中管理共享资源,可以通过 synchronized 关键字或其他线程同步机制(使用线程安全的数据结构)来确保线程安全。
遇到过 bean的并发安全问题吗?
- 首先开发的时候我们会有严格的代码规范,所有的单例Bean都只用来处理业务逻辑,不会定义可变的成员变量
- 所有的请求状态都放在方法的局部变量或者ThreadLocal里,每个请求进来都是独立的,不会互相影响。
- 如果确实需要用到有状态的Bean,我们会设置成prototype作用域,或者用对象池来管理实例。
- 另外我们做压测的时候也会专门做并发安全的校验,模拟高并发请求检查有没有数据错乱的情况,上线这么久以来基本没出现过Spring Bean相关的并发安全问题。
Spring AOP
详情请查看:Spring AOP
什么是AOP?
面向切面编程,作为面向对象的一种补充,将公共逻辑(事务管理、日志、缓存等)封装成切面,跟业务代码进行分离,可以减少系统的重复代码和降低模块之间的耦合度。切面就是那些与业务无关,但所有业务模块都会调用的公共逻辑。
面向切面编程和面向对象编程的区别,两者有冲突吗?
面向切面编程(AOP)和面向对象编程(OOP)是两种不同的编程范式,它们各自解决不同类型的问题,并且通常可以互补使用而不是冲突。
OOP 关注的是对象和它们的交互,强调的是数据和行为的封装。
AOP关注的是横切关注点,强调的是将与业务无关的代码(如日志、事务)从业务逻辑中分离出来。
AOP 和 OOP 是互补的。OOP 关注的是业务逻辑的实现和数据的封装,而 AOP 关注的是横切关注点的管理。你可以在 OOP 代码中使用 AOP 来简化和管理横切关注点。
并且AOP 通常在 OOP 代码的基础上实现。例如 AOP 框架(如 AspectJ、Spring AOP)都是基于 OOP 语言(如Java)实现的。
AOP有哪些实现方式?
AOP有两种实现方式:静态代理和动态代理。
- 静态代理
静态代理:代理类在编译阶段生成,在编译阶段将通知织入Java字节码中,也称编译时增强。AspectJ使用的是静态代理。
缺点:代理对象需要与目标对象实现一样的接口,并且实现接口的方法,会有冗余代码。同时,一旦接口增加方法,目标对象与代理对象都要维护。
- 动态代理
动态代理:代理类在程序运行时创建,AOP框架不会去修改字节码,而是在内存中临时生成一个代理对象,在运行期间对业务方法进行增强,不会生成新类。
Spring AOP的实现原理
Spring的AOP实现原理其实很简单,就是通过动态代理实现的。如果我们为Spring的某个bean配置了切面,那么Spring在创建这个bean的时候,实际上创建的是这个bean的一个代理对象,我们后续对bean中方法的调用,实际上调用的是代理类重写的代理方法。而Spring的AOP使用了两种动态代理,分别是JDK的动态代理,以及CGLib的动态代理。
底层实现主要分两部分:创建AOP动态代理和调用代理
- 在启动Spring会创建AOP动态代理:
- 首先通过AspectJ解析切点表达式:在创建代理对象时,Spring AOP使用AspectJ来解析切点表达式。它会根据定义的条件匹配目标Bean的方法。如果Bean不符合切点的条件,将跳过,否则将会通动态代理包装Bean对象:具体会根据目标对象是否实现接口来选择使用JDK动态代理或CGLIB代理。这使得AOP可以适用于各种类型的目标对象。
- 在调用阶段:
- Spring AOP使用责任链模式来管理通知的执行顺序。通知拦截链包括前置通知、后置通知、异常通知、最终通知和环绕通知,它们按照配置的顺序形成链式结构。
- 通知的有序执行: 责任链确保通知按照预期顺序执行。前置通知在目标方法执行前执行,后置通知在目标方法成功执行后执行,异常通知在方法抛出异常时执行,最终通知无论如何都会执行,而环绕通知包裹目标方法,允许在方法执行前后添加额外的行为。
综上所述,Spring AOP在创建启动阶段使用AspectJ解析切点表达式如果匹配使用动态代理,而在调用阶段使用责任链模式确保通知的有序执行。这些机制共同构成了Spring AOP的底层实现。
Spring AOP 和 AspectJ AOP 有什么区别?
Spring AOP 属于运行时增强,而 AspectJ 是编译时增强。 Spring AOP 基于代理(Proxying),而 AspectJ 基于字节码操作(Bytecode Manipulation)。
Spring AOP 已经集成了 AspectJ ,AspectJ 应该算的上是 Java 生态系统中最完整的 AOP 框架了。AspectJ 相比于 Spring AOP 功能更加强大,但是 Spring AOP 相对来说更简单,
如果我们的切面比较少,那么两者性能差异不大。但是,当切面太多的话,最好选择 AspectJ ,它比 Spring AOP 快很多。
Spring AOP:是 Spring 框架提供的一种 AOP 实现,主要用于运行时的代理机制。
- 特点:Spring AOP 是基于动态代理实现的,适用于Spring 容器管理的 Bean,较轻量级,使用方便。
- 使用场景:适合大部分业务场景,尤其是需要简单 AOP 功能的 Spring 应用。
AspectJ:AspectJ 是功能更强大的 AOP 框架,支持编译时、类加载时和运行时的 AOP 功能。
- 特点:AspectJ 支持更加灵活的切点和增强操作,提供编译期和加载期的织入方式,性能较高。
- 使用场景:适合对性能要求较高或需要复杂切点匹配的场景,如日志、监控等
注意:在日常开发中,我们经常会在 Spring 项目中使用
@Aspect、@Before、@Pointcut等注解,这容易让人产生混淆。实际上,这是 Spring 对 AspectJ 语法风格的借用(即“使用 AspectJ 的语法,但由 Spring AOP 的代理机制执行”),其底层依然是基于动态代理的 Spring AOP。只有当显式配置了 AspectJ 编译器或 Java Agent 启用加载时织入(LTW)时,才是真正的 AspectJ 织入。在真实项目中,90%的场景都是使用的 Spring AOP
JDK动态代理和CGLIB动态代理的区别?
Spring AOP中的动态代理主要有两种方式:JDK动态代理和CGLIB动态代理。SpringFramework 默认使用的动态代理是JDK动态代理 (由于后续版本已经整合了CGLIB,所以如果这个代理类没有实现接口,会用 CGLIB),SpringBoot 2.x版本的默认动态代理是 CGLIB
- JDK动态代理
如果目标类实现了接口,Spring AOP会选择使用JDK动态代理目标类。代理类根据目标类实现的接口动态生成,不需要自己编写,生成的动态代理类和目标类都实现相同的接口。JDK动态代理的核心是InvocationHandler接口和Proxy类。
缺点:目标类必须有实现的接口。如果某个类没有实现接口,那么这个类就不能用JDK动态代理。
- CGLIB动态代理
通过继承实现。如果目标类没有实现接口,那么Spring AOP会选择使用CGLIB来动态代理目标类。CGLIB(Code Generation Library)可以在运行时动态生成类的字节码,动态创建目标类的子类对象,在子类对象中增强目标类。
CGLIB是通过继承的方式做的动态代理,因此如果某个类被标记为final,那么它是无法使用CGLIB做动态代理的。
优点:目标类不需要实现特定的接口,更加灵活。
什么时候采用哪种动态代理?
- 如果目标对象实现了接口,默认情况下会采用JDK的动态代理实现AOP
- 如果目标对象实现了接口,可以强制使用CGLIB实现AOP
- 如果目标对象没有实现了接口,必须采用CGLIB库
- 两者的区别:
- jdk动态代理使用jdk中的类Proxy来创建代理对象,它使用反射技术来实现,不需要导入其他依赖。cglib需要引入相关依赖:
asm.jar,它使用字节码增强技术来实现。 - 当目标类实现了接口的时候Spring Aop默认使用jdk动态代理方式来增强方法,没有实现接口的时候使用cglib动态代理方式增强方法。
AspectJ 定义的通知类型有哪些?
- Before(前置通知):目标对象的方法调用之前触发
- After (后置通知):目标对象的方法调用之后触发
- AfterReturning(返回通知):目标对象的方法调用完成,在返回结果值之后触发
- AfterThrowing(异常通知):目标对象的方法运行中抛出 / 触发异常后触发。AfterReturning 和 AfterThrowing 两者互斥。如果方法调用成功无异常,则会有返回值;如果方法抛出了异常,则不会有返回值。
- Around (环绕通知):编程式控制目标对象的方法调用。环绕通知是所有通知类型中可操作范围最大的一种,因为它可以直接拿到目标对象,以及要执行的方法,所以环绕通知可以任意的在目标对象的方法调用前后搞事,甚至不调用目标对象的方法
Spring AOP相关术语
- 切面(Aspect):切面是通知和切点的结合。通知和切点共同定义了切面的全部内容。
- 连接点(Join point):指方法,在Spring AOP中,一个连接点总是代表一个方法的执行。连接点是在应用执行过程中能够插入切面的一个点。这个点可以是调用方法时、抛出异常时、甚至修改一个字段时。切面代码可以利用这些点插入到应用的正常流程之中,并添加新的行为。
- 通知(Advice):在AOP术语中,切面的工作被称为通知。
- 切入点(Pointcut):切点的定义会匹配通知所要织入的一个或多个连接点。我们通常使用明确的类和方法名称,或是利用正则表达式定义所匹配的类和方法名称来指定这些切点。
- 引入(Introduction):引入允许我们向现有类添加新方法或属性。
- 目标对象(Target Object): 被一个或者多个切面(aspect)所通知(advise)的对象。它通常是一个代理对象。
- 织入(Weaving):织入是把切面应用到目标对象并创建新的代理对象的过程。在目标对象的生命周期里有以下时间点可以进行织入:
Spring通知有哪些类型?
在AOP术语中,切面的工作被称为通知。通知实际上是程序运行时要通过Spring AOP框架来触发的代码段。
Spring切面可以应用5种类型的通知:
- 前置通知(Before):在目标方法被调用之前调用通知功能;
- 后置通知(After):在目标方法完成之后调用通知,此时不会关心方法的输出是什么;
- 返回通知(After-returning ):在目标方法成功执行之后调用通知;
- 异常通知(After-throwing):在目标方法抛出异常后调用通知;
- 环绕通知(Around):通知包裹了被通知的方法,在被通知的方法调用之前和调用之后执行自定义的逻辑。
多个切面的执行顺序如何控制?
5种类型的通知执行顺序:
- 正常执行:前置--->方法---->返回--->后置
- 异常执行:前置--->方法---->异常--->后置
同类型切面执行顺序:
- 通常使用
@Order注解直接定义切面顺序 - . 实现
Ordered接口重写getOrder方法。
什么情况下AOP会失效,怎么解决?
大部分失效是由于:
- 内部方法调用: 如果在同一个类中的一个方法调用另一个方法,AOP通知可能不会触发,因为AOP通常是通过代理对象拦截外部方法调用的。
解决方式是注入本类对象进行调用, 或者设置暴露当前代理对象到本地线程, 可以通过AopContext.currentProxy() 拿到当前正在调用的动态代理对象。 - 静态方法: AOP通常无法拦截静态方法的调用,因为静态方法不是通过对象调用的。
解决方法是将静态方法调用替换为实例方法调用,或者考虑其他技术来实现横切关注点。 - AOP配置问题: 错误的AOP配置可能导致通知不正确地应用于目标方法,或者在不希望的情况下应用。
解决方法是仔细检查AOP配置,确保切点表达式和通知类型正确配置。 - 代理问题: 如果代理对象不正确地创建或配置,AOP通知可能无法生效。
解决方法是调试底层源码确保代理对象正确创建,并且AOP通知能够拦截代理对象的方法调用。
SpringMVC
说说你对 SpringMVC 的理解
SpringMVC是一种基于 Java 的实现MVC设计模型的请求驱动类型的轻量级Web框架,属于Spring框架的一个模块。
它通过一套注解,让一个简单的Java类成为处理请求的控制器,而无须实现任何接口。同时它还支持RESTful编程风格的请求。
Spring MVC 基于 servlet API 构建的,可以说核心就是 DispatcherServlet,即一个前端控制器。它通过注解、配置等方式,将 HTTP 请求映射到控制器方法,然后由控制器处理请求逻辑并将数据返回给视图层进行渲染。它的主要功能包括请求映射、数据绑定、视图解析、表单处理、异常处理等,帮助我们快速构建 Web 应用。
Spring 和 Spring MVC 的关系是什么?
Spring 是基础,Spring MVC 构建于 Spring 核心之上,利用其提供的容器管理、依赖注入、AOP 等功能来实现 Web 层的处理
什么是MVC模式?
MVC的全名是Model View Controller ,是模型(model)-视图(view)-控制器(controller)的缩写,是
一种软件设计典范。它是用一种业务逻辑、数据与界面显示分离的方法来组织代码,将众多的业务逻辑聚集到一个部件里面,在需要改进和个性化定制界面及用户交互的同时,不需要重新编写业务逻辑,达到减少编码的时间。
View,视图是指用户看到并与之交互的界面。比如由html元素组成的网页界面,或者软件的客户端界面。MVC的好处之一在于它能为应用程序处理很多不同的视图。在视图中其实没有真正的处理发生,它只是作为一种输出数据并允许用户操纵的方式。
model,模型是指模型表示业务规则。在MVC的三个部件中,模型拥有最多的处理任务。被模型返回的数据是中立的,模型与数据格式无关,这样一个模型能为多个视图提供数据,由于应用于模型的代码只需写一次就可以被多个视图重用,所以减少了代码的重复性。
controller,控制器是指控制器接受用户的输入并调用模型和视图去完成用户的需求,控制器本身不输出任何东西和做任何处理。它只是接收请求并决定调用哪个模型构件去处理请求,然后再确定哪个视图来显示返回的数据。
什么是 Restful 风格的接口?
Restful风格的接口是一种基于资源的设计风格,用于构建面向 Web的 API。
REST(Representational State Transfer)是一种无状态的架构风格,它以 HTTP 协议为基础,通过定义资源和标准的操作方法来组织接口,使得客户端和服务器之间的交互更加简单、清晰和高效。
示例:假设有一个用户资源,URI为/users,RESTful API设计如下
- GET /users:获取所有用户。
- GET /users/{id}:获取指定 ID 的用户。
- POST /users :创建新用户。
- PUT /users/{id}:更新指定 ID 的用户。
- DELETE /users/{id}:删除指定 ID 的用户
Spring MVC 的核心组件有哪些?
记住了下面这些组件,也就记住了 SpringMVC 的工作原理。
| 核心组件 | 核心职责 | |
|---|---|---|
| DispatcherServlet | 前端控制器,整个流程的入口和总调度,负责接收请求并协调各组件。 | |
| HandlerMapping | 处理器映射器,根据请求 URL 找到对应的 Controller 及拦截器。 | |
| HandlerAdapter | 处理器适配器,负责调用具体的 Controller 方法,解耦了调度器和处理器。 | |
| ViewResolver | 视图解析器,将 Controller 返回的逻辑视图名解析为具体的物理视图。 | |
| Interceptor | 拦截器,在 Controller 执行前后进行增强处理(如日志、权限校验)。 |
MVC 中的视图解析器有什么作用?
视图解析器 (ViewResolver)是 Spring MVC框架中的一个接口,负责将逻辑视图名称解析为实际的视图对象(如 JSP、Thymeleaf、FreeMarker 模板等)。根据控制器返回的视图名称,找到对应的视图文件,并将模型数据传递给视图,生成最终的 HTML 响应。来看下工作流程:
- 接收视图名称:控制器返回一个逻辑视图名称
- 视图解析:视图解析器根据逻辑视图名称和配置,解析并找到实际的视图文件
- 渲染视图:将模型数据传递给视图对象,由视图对象生成最终的 HTML响应。
SpringMVC 工作原理了解吗?
Spring MVC 的工作流程可以分为以下几个关键步骤:
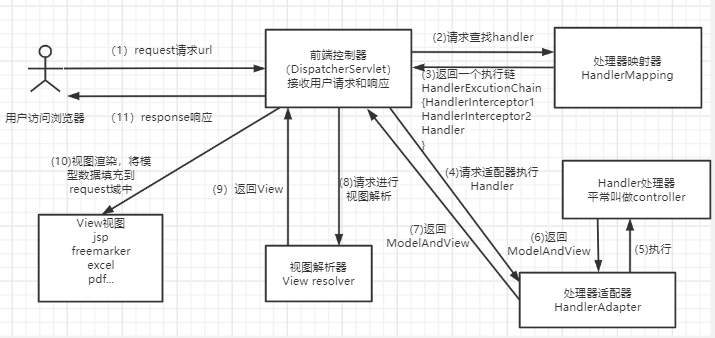
- 请求到达:用户发起 HTTP 请求,请求首先到达 Web 服务器(如 Tomcat),然后被转发给 SpringMVC 的核心入口——
DispatcherServlet(前端控制器)。 - 查找处理器:
DispatcherServlet调用HandlerMapping**(处理器映射器)。HandlerMapping 会根据请求的 URL 找到对应的处理器(Controller),并将该 Controller 和相关的拦截器封装成一个处理器执行链(HandlerExecutionChain)返回。 - 获取适配器:
DispatcherServlet拿到执行链后,会调用HandlerAdapter(处理器适配器)。适配器负责适配不同类型的 Controller,并准备执行环境。 - 拦截器前置处理:在执行 Controller 方法之前,会先执行拦截器链中的
preHandle()方法。如果返回false,请求将被中断(常用于登录校验、权限控制等)。 - 执行业务逻辑:
HandlerAdapter正式调用 Controller 中的具体方法,处理业务逻辑。处理完成后,通常会返回一个ModelAndView对象(包含模型数据和逻辑视图名)。 - 拦截器后置处理:Controller 执行完毕后(且未发生异常),会执行拦截器的
postHandle()方法,此时可以对返回的ModelAndView进行修改。 - 视图解析:
DispatcherServlet将ModelAndView中的逻辑视图名交给ViewResolver(视图解析器)。ViewResolver 会将其解析为具体的物理视图(如 JSP、Thymeleaf 页面)。 - 视图渲染与响应:具体的
View对象将模型数据渲染到页面上,生成最终的 HTML 或 JSON 等响应内容,最后由DispatcherServlet返回给客户端。 - 拦截器完成处理:无论请求成功还是失败,最后都会执行拦截器的
afterCompletion()方法,通常用于资源清理工作
调用 HandlerAdapter适配不同类型的 Controller 是什么含义?
在 SpringMVC 的发展过程中,Controller 的写法其实发生过很大的变化。DispatcherServlet 作为一个统一的调度中心,它只认一种东西——Handler(处理器)。但是,具体的 Controller 实现方式却五花八门。
如果没有适配器,DispatcherServlet 的代码里就会写满各种 if-else 判断:
- “如果是注解类型的 Controller,我就用反射调方法……”
- “如果是实现了某个接口的 Controller,我就调它的 handle 方法……”
这样代码耦合度极高,且难以扩展。适配器模式完美解决了这个问题:它为每一种 Controller 都提供了一个专门的“翻译官”(适配器)。
假设我们有以下两种不同风格的 Controller:
1. 基于注解的 Controller(现代最常用)
@Controller
public class UserController {
@RequestMapping("/user")
public String getUser() {
return "userPage";
}
}2. 基于接口实现的 Controller(早期 SpringMVC 的写法)
public class OldUserController implements Controller {
@Override
public ModelAndView handleRequest(HttpServletRequest request, HttpServletResponse response) {
return new ModelAndView("oldUserPage");
}
}**适配器的作用过程:**当请求 /user 过来时,DispatcherServlet 通过 HandlerMapping 找到了 UserController 这个对象。但它不知道该怎么执行这个对象(是调 getUser 方法?还是调 handleRequest 方法?)。
这时,它会去问所有的适配器:“你们谁能处理这个 Controller?”
- RequestMappingHandlerAdapter(专门处理注解的适配器)站出来说:“我能处理!它上面有
@RequestMapping注解,我会用反射去调用它的getUser方法。” - SimpleControllerHandlerAdapter(专门处理接口的适配器)看到
OldUserController时会说:“我能处理!它实现了Controller接口,我会直接调用它的handleRequest方法。”
为什么现在感觉不到适配器的存在?如果你现在只写基于注解的 @Controller,你确实很少会直接感知到适配器的存在。因为 Spring 在底层已经自动帮你注册好了默认的适配器(主要是 RequestMappingHandlerAdapter)。
Spring MVC的常用注解有哪些?
- @Controller:用于标识此类的实例是一个控制器。
- @RequestMapping:映射Web请求(访问路径和参数)。
- @ResponseBody:注解返回数据而不是返回页面
- @RequestBody:注解实现接收 http 请求的 json 数据,将 json 数据转换为 java 对象。
- @PathVariable:获得URL中路径变量中的值
- @RestController:@Controller+@ResponseBody
Spring MVC中的Controller是什么?如何定义一个Controller?
Controller 是 Spring MVC 框架中的核心组件之一。负责处理客户端的请求,并返回相应的视图或数据。Controller通过接收用户请求,调用业务层逻辑处理,最后将数据返回给视图层进行渲染,或者直接返回JSON、XML等格式的数据给客户端。
定义 Controller 的步骤:
- 使用 @Controller 或 @RestController 注解:类上标记 @Controller 注解,表示这是一个控制器,Spring会将其注册为一个Spring MVC的 Bean,如果是用于RESTful API的开发,可以使用 @RestController,它是@controller 和 @ResponseBody 的组合注解,默认返回 JSON 数据。
- 使用 @Requestapping 注解映射请求路径:在方法上使用@Requestapping或其行生注解(如@Getmapping、@postmapping 等)来映射 HTTP 请求,
Spring MVC 中如何处理表单提交?
在 Spring MVC 中,表单提交是通过 @ModelAttribute、@RequestParam、@RequestBody 等注解来处理的。
- @ModelAttribute :可以自动将表单中的字段与 Java 对象的属性进行绑定,通常用于处理复杂的表单提交。
- @RequestParam :用于处理表单中单个字段的数据。对于简单的表单,可以使用该注解从请求中获取参数值
- @Requesteody:如果表单数据是以JSON 格式提交的,可以使用 @RequestBody 注解将请求体中的 JSON 数据映射为 Java 对象。
Spring MVC的异常如何处理?
可以将异常抛给Spring框架,由Spring框架来处理;只需要配置简单的异常处理器,在异常处理器中添视图页面即可。
- 使用系统定义好的异常处理器 SimpleMappingExceptionResolver
- 使用自定义异常处理器
- 使用异常处理注解
- 局部异常处理@ExceptionHandler 注解:用于局部的异常处理,通常定义在控制器类中。它可以捕获特定的异常,并返回自定义的错误信息或视图。
- 全局异常处理@ControllerAdvice:应用于所有的控制器。通过这个注解,可以定义全局的异常处理逻辑,避免在每个控制器中重复编写相同的异常处理代码。
SpringMVC 父子容器是什么知道吗?
父容器:父容器指的是 Spring 的根容器,通常是 Spring 应用上下文(ApplicationContext),如 ContextLoaderListener加载的根容器。它主要用于管理应用程序的全局Bean,如服务层(Service)、数据访问层(DAO)等。
子容器:是Web 容器,每个 DispatcherServlet 实例都会创建一个子容器,用于管理 Web 层(如控制器和拦截器)中的 Bean
父子容器的关系:
- 子容器可以访问父容器的 Bean:如果一个 Bean在父容器中定义,子容器也可以直接访问它,这种机制有助于 Web层(子容器)使用服务层或 DAO 层(父容器)中的 Bean
- 父容器不能访问子容器的 Bean:父容器无法访问子容器中的 Bean,这是 Sping MVC的设计之一。父容器中的 Bean 和子容器中的 Bean 被分开管理,避免了不必要的耦合。
父子容器最经典的使用场景就是传统的 SSM(Spring + SpringMVC + MyBatis)架构项目。
- 父容器配置文件(如
applicationContext.xml):扫描@Service、@Repository注解,配置数据源、事务管理器和 AOP 切面。 - 子容器配置文件(如
spring-mvc.xml):扫描@Controller注解,配置<mvc:annotation-driven/>、视图解析器和拦截器。
Spring Boot 中的变化:如果你现在使用的是 Spring Boot,你会发现默认情况下已经不再使用父子容器架构了。Spring Boot 提倡“约定优于配置”,默认采用单容器模式,将 Controller、Service、DAO 等所有 Bean 都放在同一个
ApplicationContext中管理。这样大大简化了配置和启动流程。只有在一些需要高度定制化或集成多个独立 Web 模块的复杂场景下,才会在 Spring Boot 中手动去配置父子容器
RequestBody和RequestParam的区别
- @RequestBody一般处理的是在ajax请求中声明contentType: "application/json; charset=utf-8"时候。也就是json数据或者xml数据。
- @RequestParam一般就是在ajax里面没有声明contentType的时候,为默认的x-www-form-urlencoded格式时。
能说说 Spring 拦截链的实现吗?
在 Spring 中,拦截链通常指的是一系列拦截器(如 AOP切面、过滤器、拦截器等)依次作用于请求或方法调用,实现横切关注点的处理,比如日志记录、权限控制、事务管理等。
Spring 拦截链的核心实现包括以下几个方面:
- HandlerInterceptor (MVC 拦载器):用于拦截 HTTP 请求并进行预处理和后处理,通过实现 HandlerInterceptor 接口的 pretHandle、postHandle 和 afterCompletion 方法,可以在请求到达控制器之前、控制器方法执行之后以及请求完成后进行处理。
- Fiter(过滤器):基于 Servlet API的过滤器,可对请求进行初步筛选,应用于安全验证、编码过滤、跨域处理等场景。过滤器通过 Fiter 接口的 dofilter 方法拦截请求。
- AOP 拦截链(切面):SpingAOP提供的方法级别的拦截,通过定义切面(Aspect)可以实现方法的前后处理,切面中的 @Before、@After、@Around 等注解用于控制拦截的执行顺序。
过滤器和拦截器有什么区别?
过滤器(Filter)和拦截器(Interceptor)都是用于解决项目中与请求处理、响应管理和业务逻辑控制相关问题的工具,但它们之间存在明显的区别。
- 来源不同:拦截器是基于java反射机制的,是Servlet 相关的包,而过滤器是基于函数回调,是Spring的包。
- 触发时机不同:请求的执行顺序是:请求进入容器 > 进入过滤器 > 进入 Servlet > 进入拦截器 > 执行控制器(Controller);所以过滤器和拦截器的执行时机也是不同的,过滤器会先执行,然后才会执行拦截器,最后才会进入真正的要调用的方法。
- 拦截器不依赖于Servlet容器,而过滤器依赖于servlet容器。
- 拦截器只能对action请求起作用,而过滤器可以对几乎所以的请求起作用。
- 拦截器可以访问action上下文,值栈里的对象,而过滤器不能。
- 在Action的生命周期周,拦截器可以被多次调用,而过滤器只能在容器初始化的时候被调用一次。
- 使用场景不同:
- 拦截器更接近业务系统,所以拦截器主要用来实现项目中的业务判断的,比如:登录判断、权限判断、日志记录等业务。
- 过滤器通常是用来实现通用功能过滤的,比如:敏感词过滤、字符集编码设置、响应数据压缩等功能。
Spring WebFlux 是什么?它与 Spring MVC 有何不同?
Spring WebFlux:
- 异步非阻塞框架:Spring WebFlux是Spring5 引入的响应式 Web 框架,旨在支持异步非阻塞编程模型
- 基于 Reactor: WebFlux基于 Reactor 库,支持响应式流(Reactive Streams)规范,使用 Mono 和 Flux来表示单个和多个异步序列。
- 适用于高并发:WebFlux 适用于需要处理大量并发请求的场景,如实时数据流和高负载应用。
Spring MVC:
- 同步阻塞框架:Spring MVC是一个基于 Servlet 的传统 Web 框架,使用同步阻塞模型处理请求
- 基于 Servlet APl:Spring MVC 使用标准的 Servlet API,通常每个请求对应一个线程。
- 广泛应用:Spring MVC适用于大多数 Web 应用,特别是传统的 CRUD 操作和企业应用
适用场景:
- Spring MVC:适用于 IO 操作较少、请求数相对较少的应用。。
- Spring WebFlux:适用于 IO 操作频繁、高并发、低延迟的应用。
MVC 中的国际化支持是如何实现的?
主要通过 LocaleResolver 和 ResourceBundleMessagesource实现,它可以根据用户的语言环境(Locale)来动态选择和显示对应语言的文本或内容,从而支持多语言的 Web 应用程序
实现国际化的核心步骤:
- 定义国际化资源文件:使用 messages.properties 等资源文件来存储不同语言的文本内容。Spring MVC 会根据当前用户的 Locale(区域设置)加载对应的资源文件。
- 配置 LocaleResolver:LocaleResolver 用于确定用户的语言环境(Locale),可以基于请求参数、会话、Cookie 等来解析用户的 Locale
- 配置 ResourceBundlemesagesource:Spring 使用ResourceBundleMessagesource 来加载国际化资源文件,并根据用户的 Locale 返回相应的语言内容
- 使用 @Requestmapping 或 Thymeleaf 等模板引擎的国际化标签来实现动态内容切换。
Spring 事务
详情请查看:Spring 事务
为什么用事务?什么情况下用事务?
- 涉及多个数据库操作的业务方法:当一个业务方法需要执行多个数据库操作(如插入、更新、删除)时,必须使用事务确保这些操作要么全部成功,要么全部失败。(或多个表的操作,或多个数据库的操作)
- 数据一致性要求高的操作:例如订单的处理,创建订单、扣减库存、记录交易日志等操作必须在一个事务中完成
这里说的事务是指单机事务,即本地事务。单机事务的边界是单个数据库连接,涉及到多个数据库连接,则需要用到分布式事务
事务的四大特性?
事务特性ACID:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。
- 原子性(Atomicity):语句要么全执行,要么全不执行,是事务最核心的特性,事务本身就是以原子性来定义的;实现主要基于undo log
- 持久性(Durability):保证事务提交后不会因为宕机等原因导致数据丢失;实现主要基于redo log
- 隔离性(Isolation):数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性保证事务执行尽可能不受其他事务影响;InnoDB默认的隔离级别是RR,RR的实现主要基于锁机制(包含next-key lock)、MVCC(包括数据的隐藏列、基于undo log的版本链、ReadView)
- 一致性(Consistency):事务追求的最终目标,是指事务操作前和操作后,数据满足完整性约束,数据库保持一致性状态。一致性的实现既需要数据库层面的保障,也需要应用层面的保障
常见的InnoDB是支持事务的,但是MyISAM是不支持事务的
Spring 事务实现方式有哪些?
事务就是一系列的操作原子执行。Spring事务机制主要包括声明式事务和编程式事务。
- 编程式事务:通过编程的方式管理事务,这种方式带来了很大的灵活性,但很难维护。
- 声明式事务:将事务管理代码从业务方法中分离出来,通过aop进行封装。Spring声明式事务使得我们无需要去处理获得连接、关闭连接、事务提交和回滚等这些操作。使用
@Transactional注解开启声明式事务。
@Transactional相关属性如下:
| 属性 | 类型 | 描述 |
|---|---|---|
| value | String | 可选的限定描述符,指定使用的事务管理器 |
| propagation | enum: Propagation | 可选的事务传播行为设置 |
| isolation | enum: Isolation | 可选的事务隔离级别设置 |
| readOnly | boolean | 读写或只读事务,默认读写 |
| timeout | int (in seconds granularity) | 事务超时时间设置 |
| rollbackFor | Class对象数组,必须继承自Throwable | 导致事务回滚的异常类数组 |
| rollbackForClassName | 类名数组,必须继承自Throwable | 导致事务回滚的异常类名字数组 |
| noRollbackFor | Class对象数组,必须继承自Throwable | 不会导致事务回滚的异常类数组 |
| noRollbackForClassName | 类名数组,必须继承自Throwable | 不会导致事务回滚的异常类名字数组 |
说一下 spring 的事务隔离级别?
Spring的事务隔离级别是指在并发环境下,事务之间相互隔离的程度。Spring框架支持多种事务隔离级别,可以根据具体的业务需求来选择适合的隔离级别。以下是常见的事务隔离级别:
- DEFAULT(默认):使用数据库默认的事务隔离级别。通常为数据库的默认隔离级别,如Oracle为READ COMMITTED,MySQL为REPEATABLE READ。
- READ_UNCOMMITTED:最低的隔离级别,允许读取未提交的数据。事务可以读取其他事务未提交的数据,可能会导致脏读、不可重复读和幻读的问题。
- READ_COMMITTED:保证一个事务只能读取到已提交的数据。事务读取的数据是其他事务已经提交的数据,避免了脏读的问题。但可能会出现不可重复读和幻读的问题。
- REPEATABLE_READ:保证一个事务在同一个查询中多次读取的数据是一致的。事务期间,其他事务对数据的修改不可见,避免了脏读和不可重复读的问题。但可能会出现幻读的问题。
- SERIALIZABLE:最高的隔离级别,保证事务串行执行,避免了脏读、不可重复读和幻读的问题。但会降低并发性能,因为事务需要串行执行。
通过@Transactional注解的isolation属性来指定事务隔离级别。
有哪些事务传播行为?
在TransactionDefinition接口中定义了七个事务传播行为:
PROPAGATION_REQUIRED如果存在一个事务,则支持当前事务。如果没有事务则开启一个新的事务。如果嵌套调用的两个方法都加了事务注解,并且运行在相同线程中,则这两个方法使用相同的事务中。如果运行在不同线程中,则会开启新的事务。PROPAGATION_SUPPORTS如果存在一个事务,支持当前事务。如果没有事务,则非事务的执行。PROPAGATION_MANDATORY如果已经存在一个事务,支持当前事务。如果不存在事务,则抛出异常IllegalTransactionStateException。PROPAGATION_REQUIRES_NEW总是开启一个新的事务。需要使用JtaTransactionManager作为事务管理器。PROPAGATION_NOT_SUPPORTED总是非事务地执行,并挂起任何存在的事务。需要使用JtaTransactionManager作为事务管理器。PROPAGATION_NEVER总是非事务地执行,如果存在一个活动事务,则抛出异常。PROPAGATION_NESTED如果一个活动的事务存在,则运行在一个嵌套的事务中。如果没有活动事务, 则按PROPAGATION_REQUIRED 属性执行。
PROPAGATION_NESTED 与PROPAGATION_REQUIRES_NEW的区别:
使用PROPAGATION_REQUIRES_NEW时,内层事务与外层事务是两个独立的事务。一旦内层事务进行了提交后,外层事务不能对其进行回滚。两个事务互不影响。
使用PROPAGATION_NESTED时,外层事务的回滚可以引起内层事务的回滚。而内层事务的异常并不会导致外层事务的回滚,它是一个真正的嵌套事务。
Spring 事务传播行为有什么用?
主要作用是定义和管理事务边界,尤其是一个事务方法调用另一个事务方法时,事务如何传播的问题。它解决了多个事务方法嵌套执行时,是否要开启新事务、复用现有事务或者挂起事务等复杂情况。
总结用途:
- 控制事务的传播和嵌套:根据具体业务需求,可以指定是否使用现有事务或开启新的事务,解决事务的传播问题。
- 确保独立操作的事务隔离:某些操作(如日志记录、发送通知)应当独立于主事务执行,即使主事务失败,这些操作也可以成功完成
- 控制事务的边界和一致性:不同的业务场景可能需要不同的事务边界,例如强制某个方法必须在事务中执行,或者确保某个方法永远不在事务中运行
谈谈对Spring事务和AOP底层实现原理的区别
Spring的声明式事务其实也是通过AOP的这一套底层实现原理实现的,都是通过同一个bean的后置处理器来完成的动态代理创建的,只是:
- 创建动态代理的匹配方式不一样: 区别就是AOP的增强通常是通过切面+切点+通知来完成的, 在创建bean的时候发现bean和切点表达式匹配就会创建动态代理。 而事务内置一个增强类, 在创建bean的时候, 一旦发现你的类加了@Transactional注解 就会创建动态代理。
- 执行动态代理的增强不一样: 在执行AOP的bean时会先执行动态代理的增强类, 通过责任链分别按顺序执行通知。
在执行事务的bean的时候会先执行动态代理的增强类, 在执行目标方法前进行异常捕捉,出现异常回滚事务, 无异常提交事务。
Spring事务在什么情况下会失效?
- 应用在非 public 修饰的方法上
之所以会失效是因为@Transactional 注解依赖于Spring AOP切面来增强事务行为,这个 AOP 是通过代理来实现的
而无论是JDK动态代理还是CGLIB代理,Spring AOP的默认行为都是只代理public方法。
- 被用 final 、static 修饰方法
和上边的原因类似,被用 final 、static 修饰的方法上加 @Transactional 也不会生效。
- static 静态方法属于类本身的而非实例,因此代理机制是无法对静态方法进行代理或拦截的
- final 修饰的方法不能被子类重写,事务相关的逻辑无法插入到 final 方法中,代理机制无法对 final 方法进行拦截或增强。
- 同一个类中方法调用
比如有一个类Test,它的一个方法A,A再调用本类的方法B(不论方法B是用public还是private修饰),但方法A没有声明注解事务,而B方法有。则外部调用方法A之后,方法B的事务是不会起作用的。
那为啥会出现这种情况?其实这还是由于使用Spring AOP代理造成的,因为只有当事务方法被当前类以外的代码调用时,才会由Spring生成的代理对象来管理。
但是如果是A声明了事务,A的事务是会生效的。
- Bean 未被 spring 管理
上边我们知道 @Transactional 注解通过 AOP 来管理事务,而 AOP 依赖于代理机制。因此,Bean 必须由Spring管理实例! 要确保为类加上如 @Controller、@Service 或 @Component注解,让其被Spring所管理,这很容易忽视。
- 异步线程调用
如果我们在 testMerge() 方法中使用异步线程执行事务操作,通常也是无法成功回滚的,来个具体的例子。
假设testMerge() 方法在事务中调用了 testA(),testA() 方法中开启了事务。接着,在 testMerge() 方法中,我们通过一个新线程调用了 testB(),testB() 中也开启了事务,并且在 testB() 中抛出了异常。此时,testA() 不会回滚 和 testB() 回滚。
testA() 无法回滚是因为没有捕获到新线程中 testB()抛出的异常;testB()方法正常回滚。
在多线程环境下,Spring 的事务管理器不会跨线程传播事务,事务的状态(如事务是否已开启)是存储在线程本地的 ThreadLocal 来存储和管理事务上下文信息。这意味着每个线程都有一个独立的事务上下文,事务信息在不同线程之间不会共享。
- 数据库引擎不支持事务
事务能否生效数据库引擎是否支持事务是关键。常用的MySQL数据库默认使用支持事务的innodb引擎。一旦数据库引擎切换成不支持事务的myisam,那事务就从根本上失效了。
- RollbackFor 没设置对,比如默认没有任何(设置 RuntimeException 或者 Error 才能捕获),则方法内抛出 IOException 则不会回滚,需要配置 @Transactional(rollbackFor=Exception.class)。
- 异常被捕获了,比如代码抛错,但是被 catch 了,仅打了 log 没有抛出异常,这样事务无法正常获取到错误,因此不会回滚。
Spring多线程事务 能否保证事务的一致性
在多线程环境下,Spring事务管理默认情况下无法保证全局事务的一致性。这是因为Spring的本地事务管理是基于线程的,每个线程都有自己的独立事务。
- Spring的事务管理通常将事务信息存储在ThreadLocal中,这意味着每个线程只能拥有一个事务。这确保了在单个线程内的数据库操作处于同一个事务中,保证了原子性。
- 可以通过如下方案进行解决:
- 编程式事务: 为了在多线程环境中实现事务一致性,您可以使用编程式事务管理。这意味着您需要在代码中显式控制事务的边界和操作,确保在适当的时机提交或回滚事务。
- 分布式事务: 如果您的应用程序需要跨多个资源(例如多个数据库)的全局事务一致性,那么您可能需要使用分布式事务管理(如2PC/3PC TCC等)来管理全局事务。这将确保所有参与的资源都处于相同的全局事务中,以保证一致性。
总之,在多线程环境中,Spring的本地事务管理需要额外的协调和管理才能实现事务一致性。这可以通过编程式事务、分布式事务管理器或二阶段提交等方式来实现,具体取决于您的应用程序需求和复杂性。
但在 Seata 框架中,事务一致性是通过分布式事务协调器(TC)来保证的。TC 负责协调分布式事务的各个参与者(RM),确保它们按照相同的顺序执行事务操作,从而保证事务的一致性。 具体来说,当一个事务开始时,TC 会生成一个全局事务 ID(XID),并将其传播给所有的 RM。每个 RM 在执行事务操作时,都会将自己的操作记录到本地事务日志中,并将 XID 和操作记录发送给 TC。TC 会根据 XID 和操作记录,协调各个 RM 的执行顺序,确保它们按照相同的顺序执行事务操作。如果在执行过程中出现异常,TC 会根据事务回滚策略,决定是否回滚事务。 通过这种方式,Seata 框架可以保证分布式事务的一致性,即使在多个节点之间进行事务操作,也可以确保数据的一致性和可靠性。(了解)
@Transactional(rollbackFor = Exception.class)注解了解吗?
Exception 分为运行时异常 RuntimeException 和非运行时异常。事务管理对于企业应用来说是至关重要的,即使出现异常情况,它也可以保证数据的一致性。
当 @Transactional 注解作用于类上时,该类的所有 public 方法将都具有该类型的事务属性,同时,我们也可以在方法级别使用该标注来覆盖类级别的定义。
@Transactional 注解默认回滚策略是只有在遇到RuntimeException(运行时异常) 或者 Error 时才会回滚事务,而不会回滚 Checked Exception(受检查异常)。这是因为 Spring 认为RuntimeException和 Error 是不可预期的错误,而受检异常是可预期的错误,可以通过业务逻辑来处理。
而使用 rollbackFor = {Exception.class} ,则确保所有异常都能触发回滚
循环依赖
什么是循环依赖?
循环依赖(Circular Dependency)是指两个或多个模块,组件之间相互依赖形成一个闭环。简而言之,
模块A依赖模块B,而模块B又依赖于模块A。这会导依赖链的循环,无法确定加载或初始化的顺序。
Spring怎么解决循环依赖的问题?
解决步骤:
- Spring 首先创建 Bean 实例,并将其加入三级缓存中(Factory)。
- 当一个 Bean 依赖另一个未初始化的 Bean 时,Spring 会从三级缓存中获取 Bean 的工厂,并生成该 Bean 的对象(若有代理则是代理对象)代理对象存入二级缓存,解决循环依赖。
- 一旦所有依赖 Bean 被完全初始化,Bean 将转移到一级缓存中。
详细内容如下:
首先,有两种Bean注入的方式。
构造器注入和属性注入。
- 对于构造器注入的循环依赖,Spring处理不了,会直接抛出
BeanCurrentlylnCreationException异常。 - 对于属性注入的循环依赖(单例模式下),是通过三级缓存处理来循环依赖的。
而非单例对象的循环依赖,则无法处理。
下面分析单例模式下属性注入的循环依赖是怎么处理的:
首先,Spring单例对象的初始化大略分为三步:
createBeanInstance:实例化bean,使用构造方法创建对象,为对象分配内存。populateBean:进行依赖注入。initializeBean:初始化bean。
Spring为了解决单例的循环依赖问题,使用了三级缓存:
- 一级缓存
singletonObjects:完成了初始化的单例对象map,bean name --> bean instance,存完整单例bean。 - 二级缓存
earlySingletonObjects:完成实例化未初始化的单例对象map,bean name --> bean instance,存放的是早期的bean,即半成品,此时还无法使用(只用于循环依赖提供的临时bean对象)。 - 三级缓存
singletonFactories(循环依赖的出口,解决了循环依赖): 单例对象工厂map,bean name --> ObjectFactory,单例对象实例化完成之后会加入singletonFactories。它存的是一个对象工厂,用于创建对象并放入二级缓存中。同时,如果对象有Aop代理,则对象工厂返回代理对象。
这三个 map 是如何配合的呢?
- 首先,获取单例 Bean 的时候会通过 BeanName 先去 singletonObjects(一级缓存)查找完整的 Bean,如果找到则直接返回,否则进行步骤 2
- 看对应的 Bean 是否在创建中,如果不在直接返回找不到(返回null),如果是,则会去 earlySingletonObjects(二级缓存) 查找 Bean,如果找到则返回,否则进行步骤 3
- 去 singletonfactores(三级缓存)通过 BeanName查找到对应的工厂,如果存着工厂则通过工厂创建 Bean,并目放置到earlySingletonObjects 中
- 如果三个缓存都没找到,则返回 null
从上面的步骤我们可以得知,如果查询发现 Bean 还未创建,到第二步就直接返回 null,不会继续查二级和三级缓存。返回 null 之后,说明这个Bean 还未创建,这个时候会标记这个 Bean 正在创建中,然后再调用 createBean 来创建 Bean,而实际创建是调用方法 doCreateBean。
在调用createBeanInstance进行实例化之后,会调用addSingletonFactory,将单例对象放到singletonFactories中。
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized (this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) {
this.singletonFactories.put(beanName, singletonFactory);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
}假如A依赖了B的实例对象,同时B也依赖A的实例对象。
- A首先完成了实例化,并且将自己添加到singletonFactories中
- 接着进行依赖注入,发现自己依赖对象B,此时就尝试去get(B)
- 发现B还没有被实例化,对B进行实例化
- 然后B在初始化的时候发现自己依赖了对象A,于是尝试get(A),尝试一级缓存singletonObjects和二级缓存earlySingletonObjects没找到,尝试三级缓存singletonFactories,由于A初始化时将自己添加到了singletonFactories,所以B可以拿到A对象,然后将A从三级缓存中移到二级缓存中
- B拿到A对象后顺利完成了初始化,然后将自己放入到一级缓存singletonObjects中
- 此时返回A中,A此时能拿到B的对象顺利完成自己的初始化
由此看出,属性注入的循环依赖主要是通过将实例化完成的bean添加到singletonFactories来实现的。而使用构造器依赖注入的bean在实例化的时候会进行依赖注入,不会被添加到singletonFactories中。比如A和B都是通过构造器依赖注入,A在调用构造器进行实例化的时候,发现自己依赖B,B没有被实例化,就会对B进行实例化,此时A未实例化完成,不会被添加到singtonFactories。而B依赖于A,B会去三级缓存寻找A对象,发现不存在,于是又会实例化A,A实例化了两次,从而导致抛异常。
总结:1、利用缓存识别已经遍历过的节点; 2、利用Java引用,先提前设置对象地址,后完善对象。
Spring有没有解决多例Bean的循环依赖?
- 多例不会使用缓存进行存储(多例Bean每次使用都需要重新创建)
- 不缓存早期对象就无法解决循环
Spring有没有解决构造函数参数Bean的循环依赖?
- 构造函数的循环依赖会报错
- 可以通过人工进行解决:@Lazy
- 就不会立即创建依赖的bean了
- 而是等到用到才通过动态代理进行创建
为什么必须都是单例
如果从源码来看的话,循环依赖的 Bean 是原型模式,会直接抛错:

所以 Spring 只支持单例的循环依赖,但是为什么呢?
按照理解,如果两个Bean都是原型模式的话,那么创建A1需要创建一个B1,创建B1的时候要创建一个A2,创建 A2又要创建一个B2,创建 B2又要创建一个A3,创建 A3 又要创建一个 B3.就又卡 BUG 了,是吧,因为原型模式都需要创建新的对象,不能跟用以前的对象。
如果是单例的话,创建 A 需要创建 B,而创建的 B 需要的是之前的个 A,不然就不叫单例了,对吧?
也是基于这点, Spring 就能操作操作了。
具体做法就是:先创建A,此时的A是不完整的(没有注入B),用个 map 保存这个不完整的A,再创建B,B需要A,所以从那个map 得到“不完整”的A,此时的B就完整了,然后A就可以注入B,然后A就完整了,B也完整了,且它们是相互依赖的。
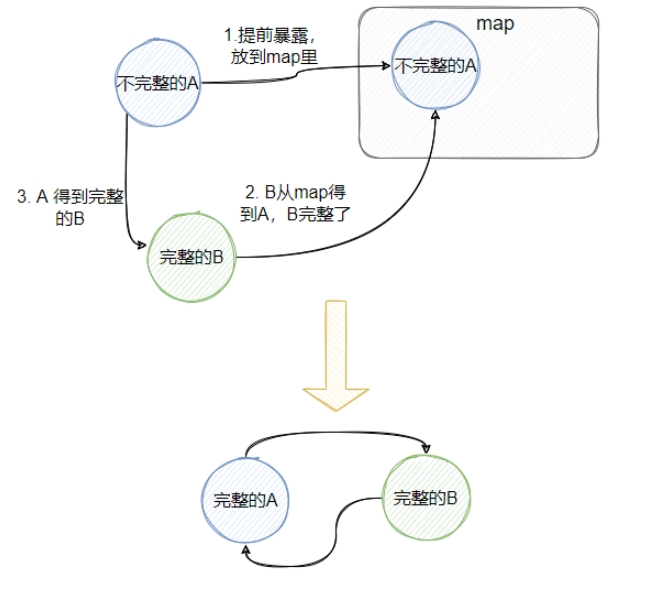
为什么不能全是构造器注入?一个set注入,一个构造器注入一定能成功?
为什么不能全是构造器注入?
在 Spring 中创建 Bean 分三步:
- 实例化,createBeanlnstance,就是 new 了个对象
- 属性注入,populateBean, 就是 set 一些属性值
- 初始化,initializeBean,执行一些 aware 接口中的方法,initMethod,AOP代理等
明确了上面这三点,再结合上面说的“不完整的”,我们来理一下。
如果全是构造器注入,比如A(B b),那表明在 new的时候,就需要得到B,此时需要 new B,但是B也是要在构造的时候注入A,即B(A a),这时候B需要在一个 map 中找到不完整的A,发现找不到。
为什么找不到?因为A 还没 new 完呢,所以找不到完整的 A,因此如果全是构造器注入的话,那么 Spring 无法处理循环依赖。
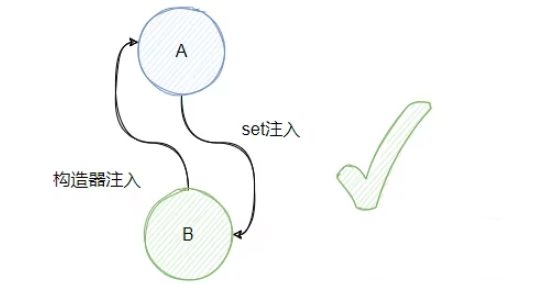
一个set注入,一个构造器注入一定能成功?
假设我们 A 是通过 set 注入 B,B 通过构造函数注入 A,此时是成功的。
我们来分析下:实例化A之后,此时可以在 map中存入A,开始为A进行属性注入,发现需要B,此时 new B,发现构造器需要A,此时从 map中得到A,B构造完毕,B进行属性注入,初始化,然后A注入B完成属性注入,然后初始化 A。
整个过程很顺利,没毛病。
假设 A 是通过构造器注入 B,B 通过 set 注入 A,此时是失败的。
我们来分析下:实例化A,发现构造函数需要B,此时去实例化B,然后进行B 的属性注入,从 map 里面找不到A,因为 A 还没 new 成功,所以B也卡住了,然后就 循环了。
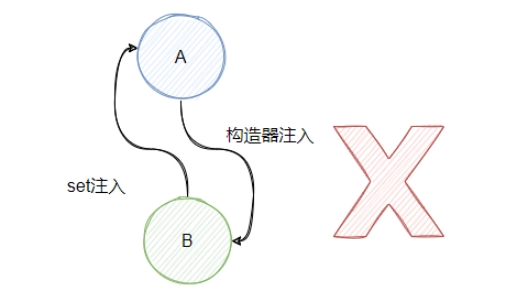
看到这里,仔细思考的小伙伴可能会说,可以先实例化 B,往 map 里面塞入不完整的 B,这样就能成功实例化 A 了。确实,思路没错但是 Spring 容器是按照字母序创建 Bean 的,A 的创建永远排在 B 前面。
现在我们总结一下:
- 如果循环依赖都是构造器注入,则失败
- 如果循环依赖不完全是构造器注入,则可能成功,可能失败,具体跟BeanName的字母序有关系,
二级缓存能不能解决循环依赖?
Spring 之所以需要三级缓存而不是简单的二级缓存,主要原因在于AOP代理和Bean的早期引用问题。
- 如果只是循环依赖导致的死循环的问题: 一级缓存就可以解决 ,但是无法解决在并发下获取不完整的Bean。
- 二级缓存虽然可以解决循环依赖的问题,但在涉及到动态代理(OP)时,直接使用二级缓存不做任问处理会导致我们拿到的 Bean 是未代理的原始对象。如果二级缓存内存放的都是代理对象,则违反了 Bean 的生命周期
Spring一二级缓存和MyBatis一、二级缓存有什么关系?
没有关系!
- MyBatis一、二级缓存是用来存储查询结果的, 一级缓存会在同一个SqlSession中的重复查询结果进行缓存, 二级缓存则是全局应用下的重复查询结果进行缓存。
- 而Spring的一、二级缓存是用来存储Bean的! 一级缓存用来存储完整最终使用的Bean,二级缓存用来存储早期临时bean。 当然还有个三级缓存用来解决循环依赖的。