在微服务架构中,服务与服务之间通过远程调用的方式进行通信,一旦某个被调用的服务发生了故障,其依赖服务也会发生故障,此时就会发生故障的蔓延,最终导致灾难性雪崩效应。Hystrix实现了断路器模式,当某个服务发生故障时,通过断路器的监控,给调用方返回一个错误响应,而不是长时间的等待,这样就不会使得调用方由于长时间得不到响应而占用线程,从而防止故障的蔓延。Hystrix具备服务降级、服务熔断、线程隔离、请求缓存、请求合并及服务监控等强大功能。
Hystrix介绍
什么是灾难性的雪崩效应
什么是灾难性的雪崩效应?我们通过结构图来说明,如下

正常情况下各个节点相互配置,完成用户请求的处理工作
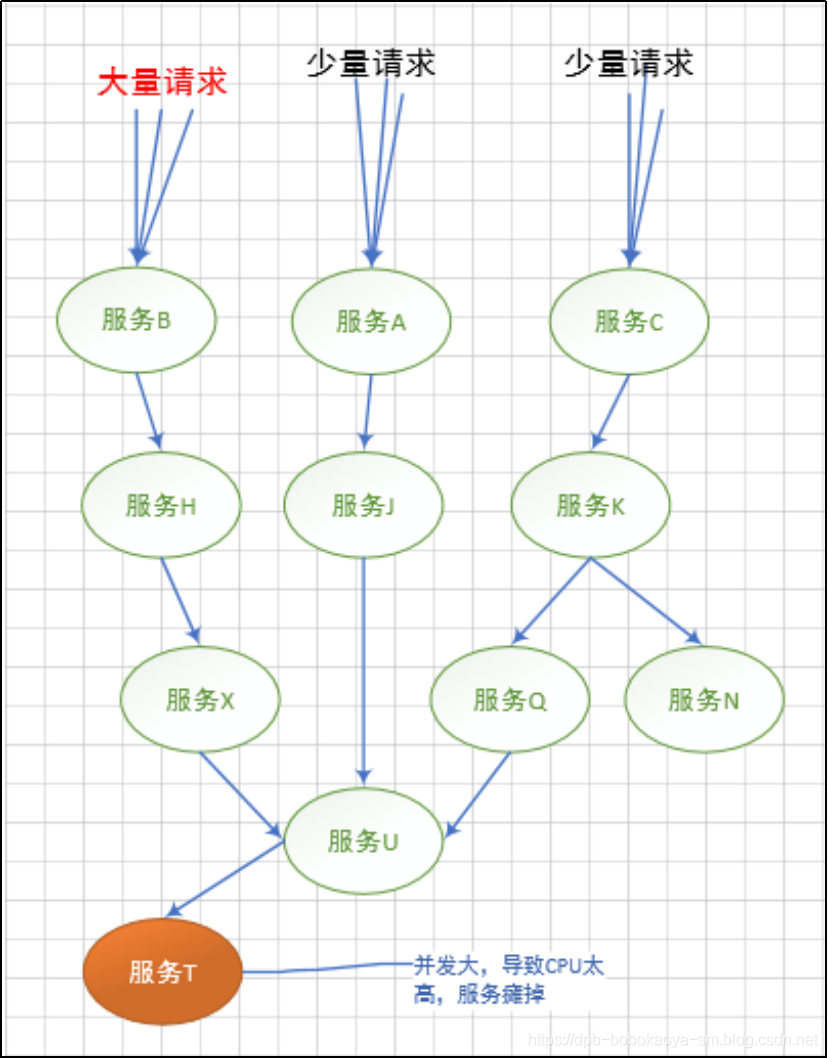
当某种请求增多,造成"服务T"故障的情况时,会延伸的造成"服务U"不可用,及继续扩展,如下
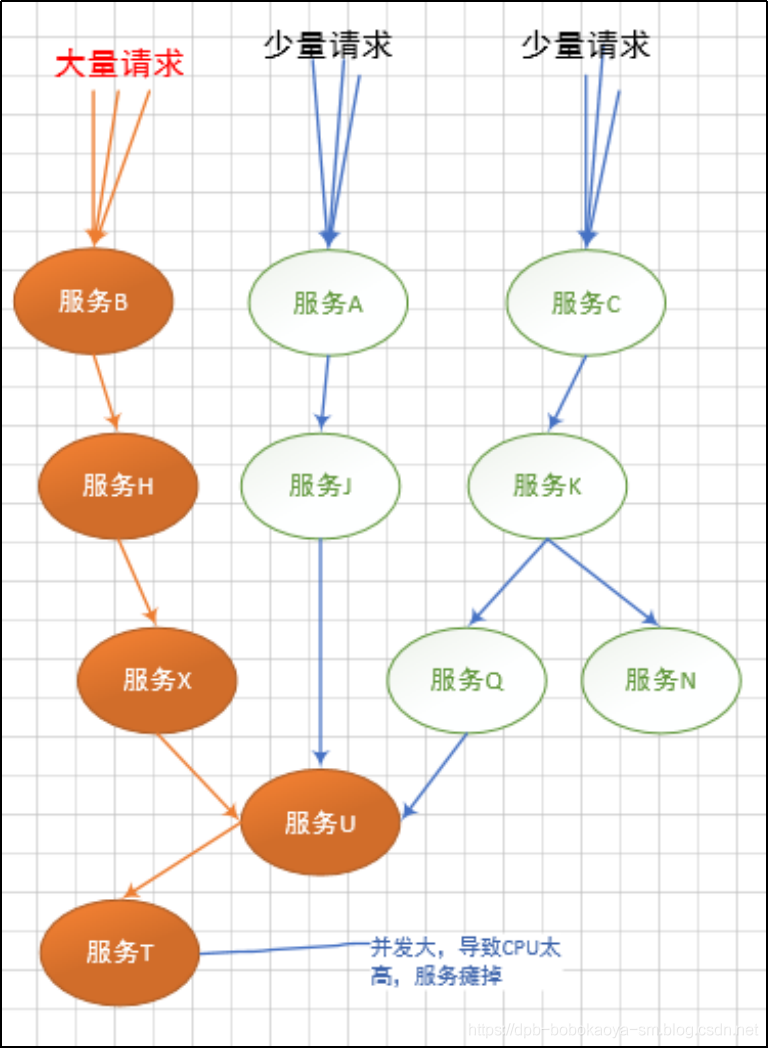
最终造成下面这种所有服务不可用的情况
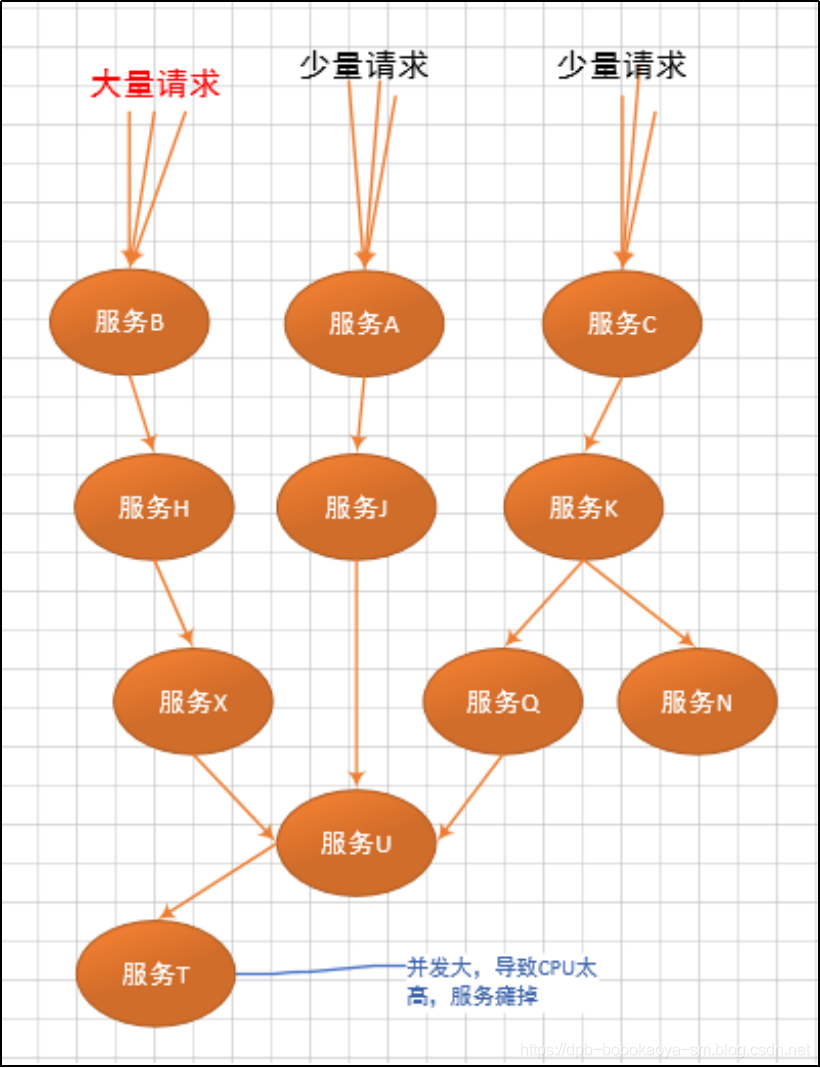
这就是我们讲的灾难性雪崩,造成雪崩的原因可以归纳为以下三个:
- 服务提供者不可用(硬件故障,程序Bug,缓存击穿,用户大量请求)
- 重试加大流量(用户重试,代码逻辑重试)
- 服务调用者不可用(同步等待造成的资源耗尽)
最终的结果就是一个服务不可用,导致一系列服务的不可用,而往往这种后果是无法预料的。
如何解决灾难性雪崩效应
我们可以通过以下5种方式来解决雪崩效应
- 降级:超时降级、资源不足时(线程或信号量)降级,降级后可以配合降级接口返回托底数据。实现一个 fallback 方法, 当请求后端服务出现异常的时候, 可以使用 fallback 方法返回的值.
- 缓存:Hystrix 为了降低访问服务的频率,支持将一个请求与返回结果做缓存处理。如果再次请求的 URL 没有变化,那么 Hystrix 不会请求服务,而是直接从缓存中将结果返回。这样可以大大降低访问服务的压力。
- 请求合并:在微服务架构中,我们将一个项目拆分成很多个独立的模块,这些独立的模块通过远程调用来互相配合工作,但是,在高并发情况下,通信次数的增加会导致总的通信时间增加,同时,线程池的资源也是有限的,高并发环境会导致有大量的线程处于等待状态,进而导致响应延迟,为了解决这些问题,我们需要来了解 Hystrix 的请求合并。
- 熔断:当失败率(如因网络故障/超时造成的失败率高)达到阀值自动触发降级,熔断器触发的快速失败会进行快速恢复。
- 隔离(线程池隔离和信号量隔离)
限制调用分布式服务的资源使用,某一个调用的服务出现问题不会影响其他服务调用。
降级
场景介绍
先来看下正常服务调用的情况

当consumer调用provider服务出现问题的情况下:

此时我们对consumer的服务调用做降级处理

实现案例
创建一个基于Ribbon的Consumer服务,并添加对应的依赖
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
</dependency>
<!-- 添加Hystrix的依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-hystrix</artifactId>
<version>1.3.2.RELEASE</version>
</dependency>配置文件
spring.application.name=eureka-consumer-hystrix
server.port=9091
# 设置服务注册中心地址 执行Eureka服务端 如果有多个注册地址 那么用逗号连接
eureka.client.service-url.defaultZone=http://seven:123456@192.168.100.120:8761/eureka/,http://seven:123456@192.168.100.121:8761/eureka/修改启动类
在启动类中添加 开启熔断
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.circuitbreaker.EnableCircuitBreaker;
@EnableCircuitBreaker // 开启Hystrix的熔断
@SpringBootApplication
public class SpringcloudEurekaConsumerApplication {
public static void main(String[] args) {
SpringApplication.run(SpringcloudEurekaConsumerApplication.class, args);
}
}业务层修改
业务层代码中的方法是通过Ribbon来获取负载均衡的服务器地址的,通过RestTemplate来调用服务,在方法的头部添加@HystrixCommand注解,通过fallbackMethod属性指定当调用Provider方法异常的时候fallback方法请求返回托底数据
import com.seven.pojo.User;
import com.netflix.hystrix.contrib.javanica.annotation.HystrixCommand;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cloud.client.ServiceInstance;
import org.springframework.cloud.client.loadbalancer.LoadBalancerClient;
import org.springframework.core.ParameterizedTypeReference;
import org.springframework.http.HttpMethod;
import org.springframework.http.ResponseEntity;
import org.springframework.stereotype.Service;
import org.springframework.web.client.RestTemplate;
import java.util.ArrayList;
import java.util.List;
@Service
public class UserService {
/**
* Ribbon 实现的负载均衡
* LocadBalancerClient 通过服务名称可以获取对应服务的相关信息
* ip 端口 等
*/
@Autowired
private LoadBalancerClient loadBalancerClient;
/**
* 远程调用 服务提供者获取用户信息的方法
* 1.发现服务
* 2.调用服务
*/
@HystrixCommand(fallbackMethod = "fallBack")
public List<User> getUsers(){
// 1. 服务发现
// 获取服务提供者的信息 ServiceInstance封装的有相关的信息
ServiceInstance instance = loadBalancerClient.choose("eureka-provider");
StringBuilder sb = new StringBuilder();
// http://localhost:9090/user
sb.append("http://")
.append(instance.getHost())
.append(":")
.append(instance.getPort())
.append("/user");
System.out.println(sb.toString());
// 2. 服务调用 SpringMVC中提供的有 调用组件 RestTemplate
RestTemplate rt = new RestTemplate();
ParameterizedTypeReference<List<User>> type = new ParameterizedTypeReference<List<User>>() {};
ResponseEntity<List<User>> response = rt.exchange(sb.toString(), HttpMethod.GET, null, type);
List<User> list = response.getBody();
return list;
}
/**
* 托底方法
* @return
*/
public List<User> fallBack(){
List<User> list = new ArrayList<>();
list.add(new User(333,"我是托底数据",28));
return list;
}
}缓存
Hystrix 为了降低访问服务的频率,支持将一个请求与返回结果做缓存处理。如果再次请求的 URL 没有变化,那么 Hystrix 不会请求服务,而是直接从缓存中将结果返回。这样可以大大降低访问服务的压力。
Hystrix 自带缓存。有两个缺点:
- 是一个本地缓存。在集群情况下缓存是不能同步的。
- 不支持第三方缓存容器。Redis,memcache 不支持的。
所以我们使用Spring的cache。
启动Redis服务
使用Redis作为缓存服务器
添加相关的依赖
因为需要用到SpringDataRedis的支持,需要添加对应的依赖
<!-- 添加Hystrix的依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-hystrix</artifactId>
<version>1.3.2.RELEASE</version>
</dependency>
<!-- 添加SpringDataRedis的依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>修改属性文件
需要在属性文件中添加Redis的配置信息
spring.application.name=eureka-consumer-hystrix
server.port=9091
# 设置服务注册中心地址 执行Eureka服务端 如果有多个注册地址 那么用逗号连接
eureka.client.service-url.defaultZone=http://seven:123456@192.168.100.120:8761/eureka/,http://seven:123456@192.168.100.121:8761/eureka/
# Redis
spring.redis.database=0
#Redis 服务器地址
spring.redis.host=192.168.100.120
#Redis 服务器连接端口
spring.redis.port=6379
#Redis 服务器连接密码(默认为空)
spring.redis.password=
#连接池最大连接数(负值表示没有限制)
spring.redis.pool.max-active=100
#连接池最大阻塞等待时间(负值表示没有限制)
spring.redis.pool.max-wait=3000
#连接池最大空闭连接数
spring.redis.pool.max-idle=200
#连接汉最小空闲连接数
spring.redis.pool.min-idle=50
#连接超时时间(毫秒)
spring.redis.pool.timeout=600修改启动类
需要在启动类中开启缓存的使用
@EnableCaching // 开启缓存
@EnableCircuitBreaker // 开启Hystrix的熔断
@SpringBootApplication
public class SpringcloudEurekaConsumerApplication {
public static void main(String[] args) {
SpringApplication.run(SpringcloudEurekaConsumerApplication.class, args);
}
}业务处理
import com.seven.pojo.User;
import com.netflix.hystrix.contrib.javanica.annotation.HystrixCommand;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cache.annotation.CacheConfig;
import org.springframework.cache.annotation.Cacheable;
import org.springframework.cloud.client.ServiceInstance;
import org.springframework.cloud.client.loadbalancer.LoadBalancerClient;
import org.springframework.core.ParameterizedTypeReference;
import org.springframework.http.HttpMethod;
import org.springframework.http.ResponseEntity;
import org.springframework.stereotype.Service;
import org.springframework.web.client.RestTemplate;
import java.util.ArrayList;
import java.util.List;
@Service
// cacheNames 当前类中的方法在Redis中添加的Key的前缀
@CacheConfig(cacheNames = {"com.seven.cache"})
public class UserService {
/**
* Ribbon 实现的负载均衡
* LocadBalancerClient 通过服务名称可以获取对应服务的相关信息
* ip 端口 等
*/
@Autowired
private LoadBalancerClient loadBalancerClient;
/**
* 远程调用 服务提供者获取用户信息的方法
* 1.发现服务
* 2.调用服务
*/
@HystrixCommand(fallbackMethod = "fallBack")
public List<User> getUsers(){
// 1. 服务发现
// 获取服务提供者的信息 ServiceInstance封装的有相关的信息
ServiceInstance instance = loadBalancerClient.choose("eureka-provider");
StringBuilder sb = new StringBuilder();
// http://localhost:9090/user
sb.append("http://")
.append(instance.getHost())
.append(":")
.append(instance.getPort())
.append("/user");
System.out.println(sb.toString());
// 2. 服务调用 SpringMVC中提供的有 调用组件 RestTemplate
RestTemplate rt = new RestTemplate();
ParameterizedTypeReference<List<User>> type = new ParameterizedTypeReference<List<User>>() {};
ResponseEntity<List<User>> response = rt.exchange(sb.toString(), HttpMethod.GET, null, type);
List<User> list = response.getBody();
return list;
}
/**
* 托底方法
* @return
*/
public List<User> fallBack(){
List<User> list = new ArrayList<>();
list.add(new User(333,"我是托底数据",28));
return list;
}
@Cacheable(key="'user'+#id")
public User getUserById(Integer id){
System.out.println("*************查询操作*************"+ id);
return new User(id,"缓存测试数据",22);
}
}使用到了缓存,所以会对POJO对象做持久化处理,所以需要实现序列化接口,否则会抛异常
请求合并
没有合并请求的场景
没有合并的场景中,对于provider的调用会非常的频繁,容易造成处理不过来的情况

合并请求的场景

什么情况下使用请求合并
在微服务架构中,我们将一个项目拆分成很多个独立的模块,这些独立的模块通过远程调用来互相配合工作,但是,在高并发情况下,通信次数的增加会导致总的通信时间增加,同时,线程池的资源也是有限的,高并发环境会导致有大量的线程处于等待状态,进而导致响应延迟,为了解决这些问题,我们需要来了解 Hystrix 的请求合并。
请求合并的缺点
设置请求合并之后,本来一个请求可能 5ms 就搞定了,但是现在必须再等 10ms 看看还有没有其他的请求一起的,这样一个请求的耗时就从 5ms 增加到 15ms 了,不过,如果我们要发起的命令本身就是一个高延迟的命令,那么这个时候就可以使用请求合并了,因为这个时候时间窗的时间消耗就显得微不足道了,另外高并发也是请求合并的一个非常重要的场景。
案例实现
业务处理代码
import com.seven.pojo.User;
import com.netflix.hystrix.contrib.javanica.annotation.HystrixCollapser;
import com.netflix.hystrix.contrib.javanica.annotation.HystrixCommand;
import com.netflix.hystrix.contrib.javanica.annotation.HystrixProperty;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cache.annotation.CacheConfig;
import org.springframework.cache.annotation.Cacheable;
import org.springframework.cloud.client.ServiceInstance;
import org.springframework.cloud.client.loadbalancer.LoadBalancerClient;
import org.springframework.core.ParameterizedTypeReference;
import org.springframework.http.HttpMethod;
import org.springframework.http.ResponseEntity;
import org.springframework.stereotype.Service;
import org.springframework.web.client.RestTemplate;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.Future;
@Service
// cacheNames 当前类中的方法在Redis中添加的Key的前缀
@CacheConfig(cacheNames = {"com.seven.cache"})
public class UserService {
/**
* Ribbon 实现的负载均衡
* LocadBalancerClient 通过服务名称可以获取对应服务的相关信息
* ip 端口 等
*/
@Autowired
private LoadBalancerClient loadBalancerClient;
/**
* 远程调用 服务提供者获取用户信息的方法
* 1.发现服务
* 2.调用服务
* @return
*/
@HystrixCommand(fallbackMethod = "fallBack")
public List<User> getUsers(){
// 1. 服务发现
// 获取服务提供者的信息 ServiceInstance封装的有相关的信息
ServiceInstance instance = loadBalancerClient.choose("eureka-provider");
StringBuilder sb = new StringBuilder();
// http://localhost:9090/user
sb.append("http://")
.append(instance.getHost())
.append(":")
.append(instance.getPort())
.append("/user");
System.out.println(sb.toString());
// 2. 服务调用 SpringMVC中提供的有 调用组件 RestTemplate
RestTemplate rt = new RestTemplate();
ParameterizedTypeReference<List<User>> type = new ParameterizedTypeReference<List<User>>() {};
ResponseEntity<List<User>> response = rt.exchange(sb.toString(), HttpMethod.GET, null, type);
List<User> list = response.getBody();
return list;
}
/**
* 托底方法
* @return
*/
public List<User> fallBack(){
List<User> list = new ArrayList<>();
list.add(new User(333,"我是托底数据",28));
return list;
}
@Cacheable(key="'user'+#id")
public User getUserById(Integer id){
System.out.println("*************查询操作*************"+ id);
return new User(id,"缓存测试数据",22);
}
/**
* Consumer中的Controller要调用的方法
* 这个方法的返回值必须是 Future 类型
* 利用Hystrix 合并请求
*/
@HystrixCollapser(
batchMethod = "batchUser"
,scope = com.netflix.hystrix.HystrixCollapser.Scope.GLOBAL
,collapserProperties = {
// 请求时间间隔在20ms以内的请求会被合并,默认值是10ms
@HystrixProperty(name = "timerDelayInMilliseconds",value = "20")
// 设置触发批处理执行之前 在批处理中允许的最大请求数
,@HystrixProperty(name = "maxRequestsInBatch",value = "200")
}
)
public Future<User> getUserId(Integer id){
System.out.println("*****id*****");
return null;
}
@HystrixCommand
public List<User> batchUser(List<Integer> ids){
for (Integer id : ids) {
System.out.println(id);
}
List<User> list = new ArrayList<>();
list.add(new User(1,"张三1",18));
list.add(new User(2,"张三2",18));
list.add(new User(3,"张三3",18));
list.add(new User(4,"张三4",18));
return list;
}
}控制器处理
@RequestMapping("/getUserId")
public void getUserId() throws Exception{
Future<User> f1 = service.getUserId(1);
Future<User> f2 = service.getUserId(1);
Future<User> f3 = service.getUserId(1);
System.out.println("*************************");
System.out.println(f1.get().toString());
System.out.println(f2.get().toString());
System.out.println(f3.get().toString());
}
熔断
熔断其实是在降级的基础上引入了重试的机制。当某个时间内失败的次数达到了多少次就会触发熔断机制,具体的流程如下
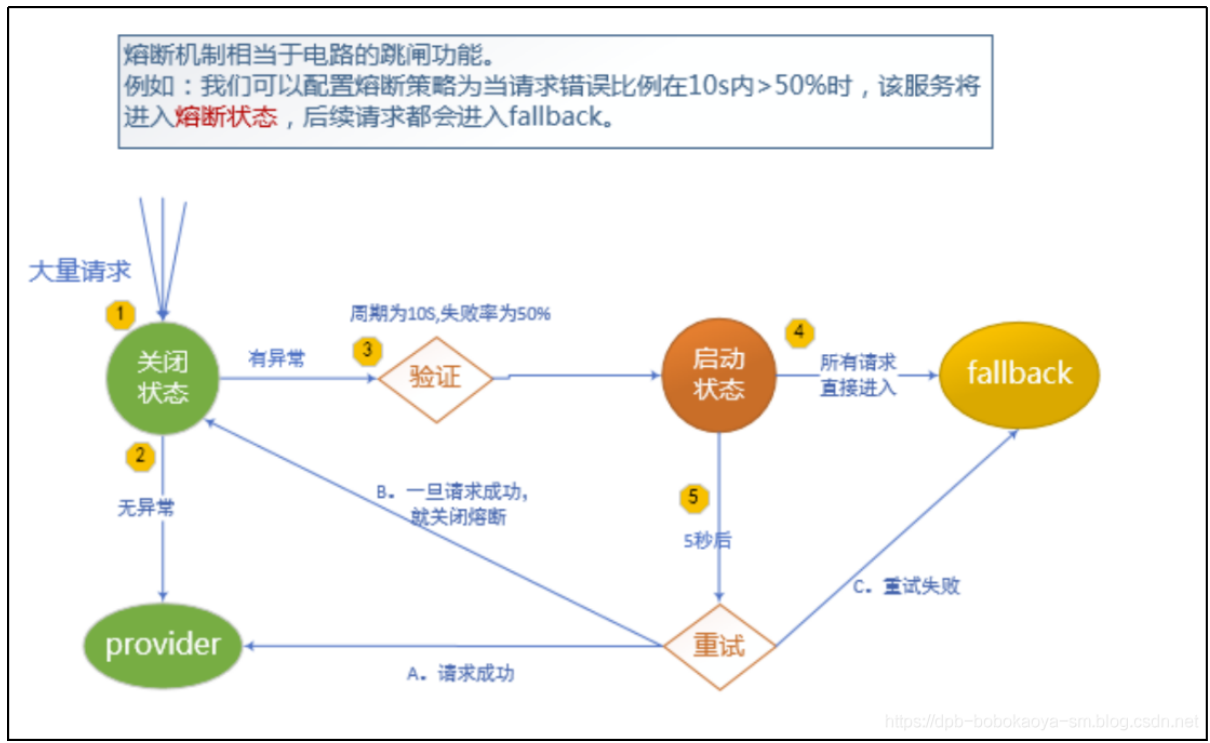
案例核心代码
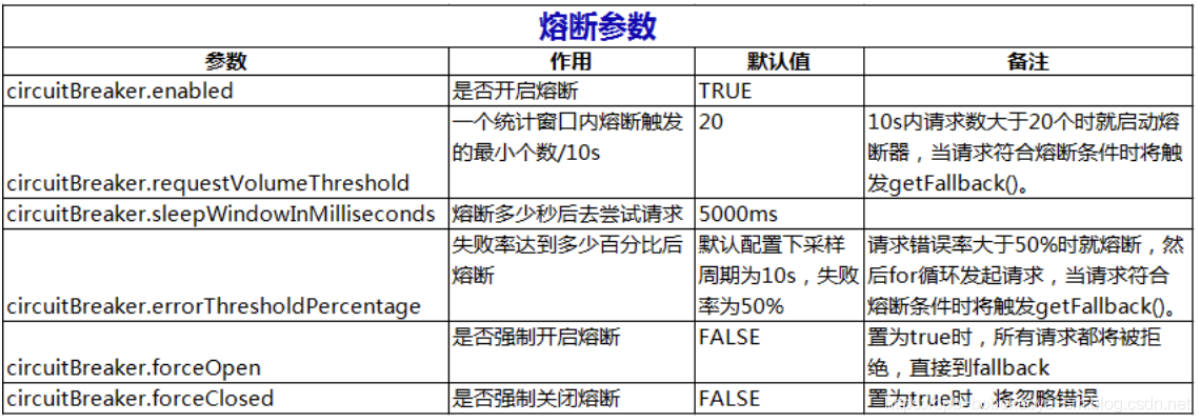
@HystrixCommand(fallbackMethod = "fallback",
commandProperties = {
//默认 20 个;10s 内请求数大于 20 个时就启动熔断器,当请求符合熔断条件时将触发 getFallback()。
@HystrixProperty(name= HystrixPropertiesManager.CIRCUIT_BREAKER_REQUEST_VOLUME_THRESHOLD,
value="10"),
//请求错误率大于 50%时就熔断,然后 for 循环发起请求,当请求符合熔断条件时将触发 getFallback()。
@HystrixProperty(name=HystrixPropertiesManager.CIRCUIT_BREAKER_ERROR_THRESHOLD_PERCENTAGE,
value="50"),
//默认 5 秒;熔断多少秒后去尝试请求
@HystrixProperty(name=HystrixPropertiesManager.CIRCUIT_BREAKER_SLEEP_WINDOW_IN_MILLISECONDS,
value="5000"),
})
public List<User> getUsers(){
// 1. 服务发现
// 获取服务提供者的信息 ServiceInstance封装的有相关的信息
ServiceInstance instance = loadBalancerClient.choose("eureka-provider");
StringBuilder sb = new StringBuilder();
// http://localhost:9090/user
sb.append("http://")
.append(instance.getHost())
.append(":")
.append(instance.getPort())
.append("/user");
System.out.println("---->"+sb.toString());
// 2. 服务调用 SpringMVC中提供的有 调用组件 RestTemplate
RestTemplate rt = new RestTemplate();
ParameterizedTypeReference<List<User>> type = new ParameterizedTypeReference<List<User>>() {};
ResponseEntity<List<User>> response = rt.exchange(sb.toString(), HttpMethod.GET, null, type);
List<User> list = response.getBody();
return list;
}
隔离
在应对服务雪崩效应时,除了前面介绍的降级,缓存,请求合并及熔断外还有一种方式就是隔离,隔离又分为线程池隔离和信号量隔离。接下来我们分别来介绍。
线程池隔离
概念介绍
我们通过以下几个图片来解释线程池隔离到底是怎么回事
在没有使用线程池隔离时:

当接口A压力增大,接口C同时也会受到影响
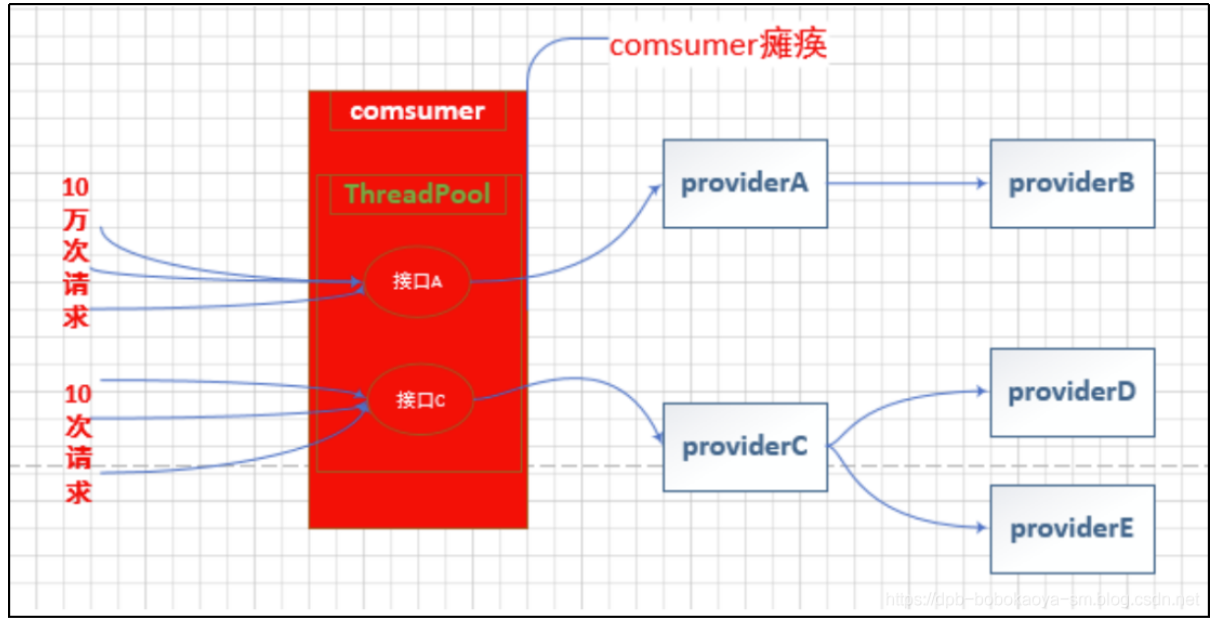
使用线程池的场景

当服务接口A访问量增大时,因为接口C在不同的线程池中所以不会受到影响

通过上面的图片来看,线程池隔离的作用还是蛮明显的。但线程池隔离的使用也不是在任何场景下都适用的,线程池隔离的优缺点如下:
优点
- 使用线程池隔离可以完全隔离依赖的服务(例如图中的A,B,C服务),请求线程可以快速放回
- 当线程池出现问题时,线程池隔离是独立的不会影响其他服务和接口
- 当失败的服务再次变得可用时,线程池将清理并可立即恢复,而不需要一个长时间的恢复
- 独立的线程池提高了并发性
缺点:线程池隔离的主要缺点是它们增加计算开销(CPU),每个命令的执行涉及到排队,调度和上下文切换都是在一个单独的线程上运行的。
案例实现
@HystrixCommand(
groupKey = "eureka-provider"
,threadPoolKey = "getUsers"
,threadPoolProperties = {
@HystrixProperty(name = "coreSize",value = "30") // 线程池大小
,@HystrixProperty(name = "maxQueueSize",value = "100") // 最大队列长度
,@HystrixProperty(name = "keepAliveTimeMinutes",value = "2") // 线程存活时间
,@HystrixProperty(name = "queueSizeRejectionThreshold",value = "15") // 拒绝请求
},fallbackMethod = "fallBack"
)
public List<User> getUsersThreadPool(Integer id){
System.out.println("--------》" + Thread.currentThread().getName());
// 1. 服务发现
// 获取服务提供者的信息 ServiceInstance封装的有相关的信息
ServiceInstance instance = loadBalancerClient.choose("eureka-provider");
StringBuilder sb = new StringBuilder();
// http://localhost:9090/user
sb.append("http://")
.append(instance.getHost())
.append(":")
.append(instance.getPort())
.append("/user");
System.out.println("---->"+sb.toString());
// 2. 服务调用 SpringMVC中提供的有 调用组件 RestTemplate
RestTemplate rt = new RestTemplate();
ParameterizedTypeReference<List<User>> type = new ParameterizedTypeReference<List<User>>() {};
ResponseEntity<List<User>> response = rt.exchange(sb.toString(), HttpMethod.GET, null, type);
List<User> list = response.getBody();
return list;
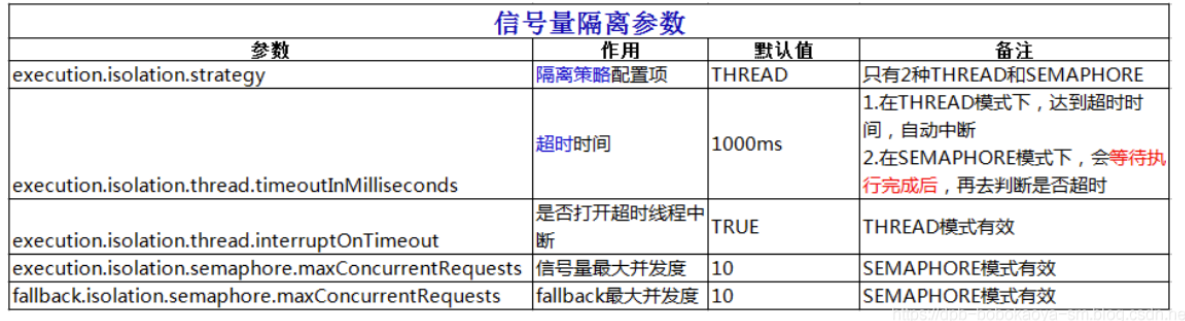
}相关参数的描述

信号量隔离
信号量隔离其实就是我们定义的队列并发时最多支持多大的访问,其他的访问通过托底数据来响应,如下结构图
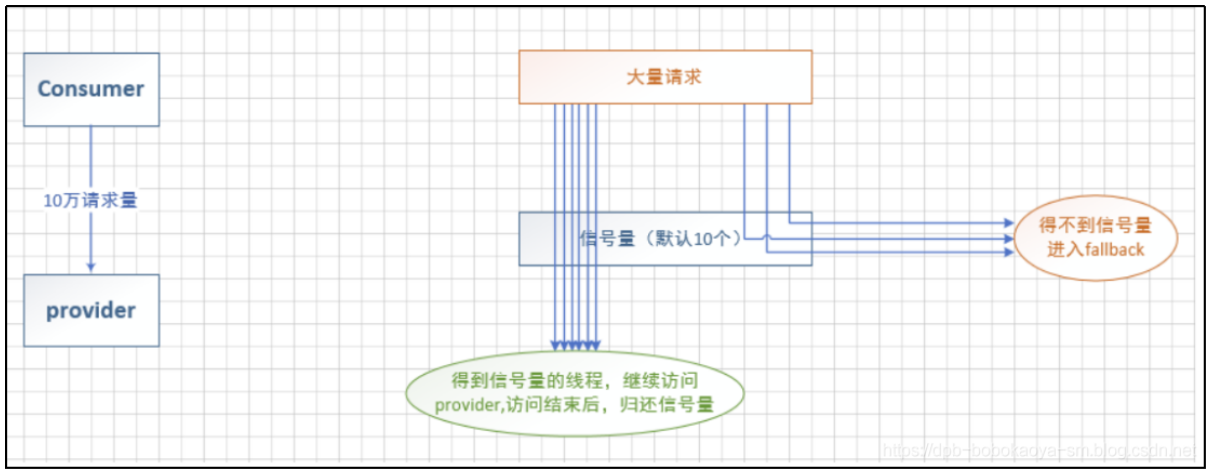
@HystrixCommand(
fallbackMethod = "fallBack"
,commandProperties = {
@HystrixProperty(name=HystrixPropertiesManager.EXECUTION_ISOLATION_STRATEGY
,value = "SEMAPHORE") // 信号量隔离
,@HystrixProperty(name=HystrixPropertiesManager.EXECUTION_ISOLATION_SEMAPHORE_MAX_CONCURRENT_REQUESTS
,value="100" // 信号量最大并发度
)
}
)
public List<User> getUsersSignal(Integer id){
System.out.println("--------》" + Thread.currentThread().getName());
// 1. 服务发现
// 获取服务提供者的信息 ServiceInstance封装的有相关的信息
ServiceInstance instance = loadBalancerClient.choose("eureka-provider");
StringBuilder sb = new StringBuilder();
// http://localhost:9090/user
sb.append("http://")
.append(instance.getHost())
.append(":")
.append(instance.getPort())
.append("/user");
System.out.println("---->"+sb.toString());
// 2. 服务调用 SpringMVC中提供的有 调用组件 RestTemplate
RestTemplate rt = new RestTemplate();
ParameterizedTypeReference<List<User>> type = new ParameterizedTypeReference<List<User>>() {};
ResponseEntity<List<User>> response = rt.exchange(sb.toString(), HttpMethod.GET, null, type);
List<User> list = response.getBody();
return list;
}
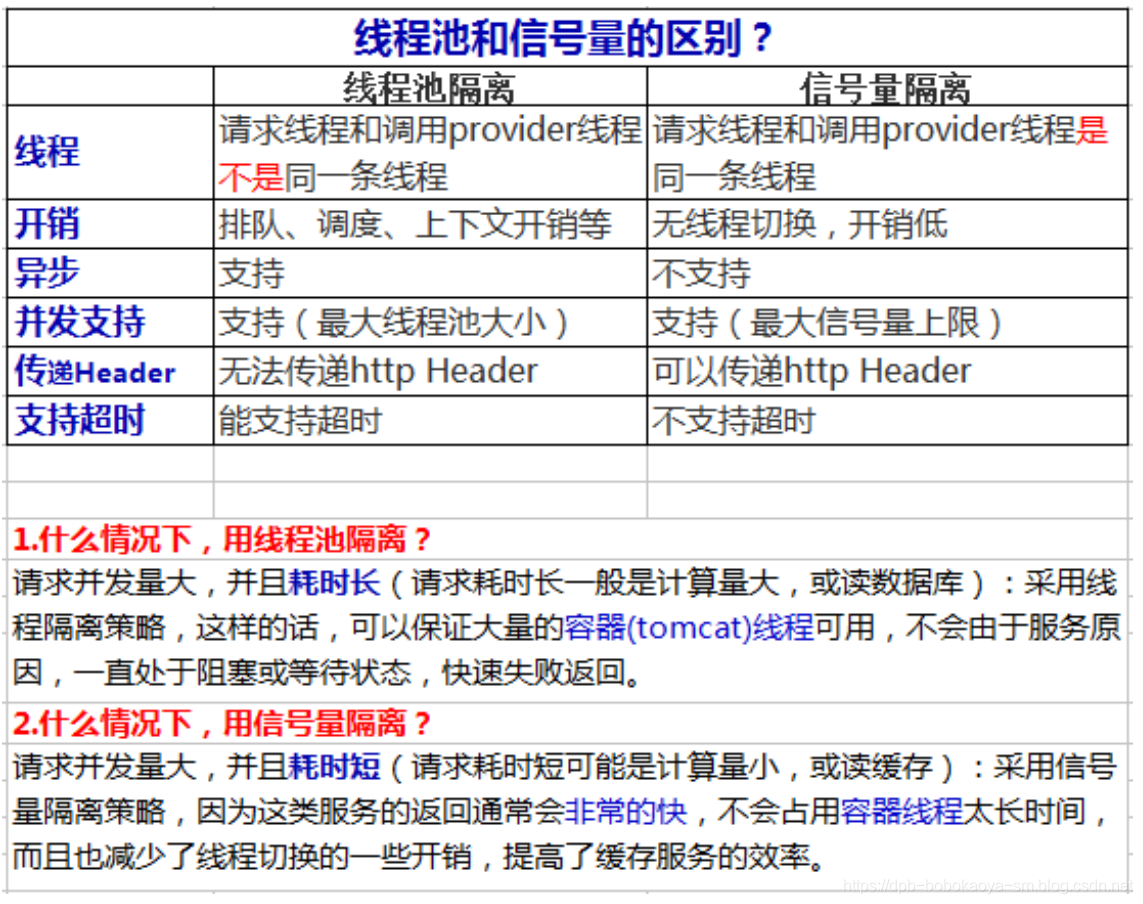
两者的区别
线程池隔离和信号量隔离的区别