介绍
巨人肩膀上的产物
回忆下之前创建一个Guava cache对象时的代码逻辑:
public LoadingCache<String, User> createUserCache() {
return CacheBuilder.newBuilder()
.initialCapacity(1000)
.maximumSize(10000L)
.expireAfterWrite(30L, TimeUnit.MINUTES)
.concurrencyLevel(8)
.recordStats()
.build((CacheLoader<String, User>) key -> userDao.getUser(key));
}而使用Caffeine来创建Cache对象的时候,我们可以这么做:
public LoadingCache<String, User> createUserCache() {
return Caffeine.newBuilder()
.initialCapacity(1000)
.maximumSize(10000L)
.expireAfterWrite(30L, TimeUnit.MINUTES)
//.concurrencyLevel(8)
.recordStats()
.build(key -> userDao.getUser(key));
}可以发现,两者的使用思路与方法定义非常相近,对于使用过Guava Cache的小伙伴而言,几乎可以无门槛的直接上手使用。当然,两者也还是有点差异的,比如Caffeine创建对象时不支持使用concurrencyLevel来指定并发量(因为改进了并发控制机制),这些我们在下面章节中具体介绍。
相较于Guava Cache,Caffeine在整体设计理念、实现策略以及接口定义等方面都基本继承了前辈的优秀特性。作为新时代背景下的后来者,Caffeine也做了很多细节层面的优化,比如:
- 基础数据结构层面优化 借助JAVA8对
ConcurrentHashMap底层由链表切换为红黑树、以及废弃分段锁逻辑的优化,提升了Hash冲突时的查询效率以及并发场景下的处理性能。 - 数据驱逐(淘汰)策略的优化 通过使用改良后的
W-TinyLFU算法,提供了更佳的热点数据留存效果,提供了近乎完美的热点数据命中率,以及更低消耗的过程维护 - 异步并行能力的全面支持 完美适配
JAVA8之后的并行编程场景,可以提供更为优雅的并行编码体验与并发效率。
通过各种措施的改良,成就了Caffeine在功能与性能方面不俗的表现。
Caffeine与Guava —— 是传承而非竞争
很多人都知道Caffeine在各方面的表现都优于Guava Cache, 甚至对比之下有些小伙伴觉得Guava Cache简直一无是处。但不可否认的是,在曾经的一段时光里,Guava Cache提供了尽可能高效且轻量级的并发本地缓存工具框架。技术总是在不断的更新与迭代的,纵使优秀如Guava Cache这般,终究是难逃沦为时代眼泪的结局。
纵观Caffeine,其原本就是基于Guava cache基础上孵化而来的改良版本,众多的特性与设计思路都完全沿用了Guava Cache相同的逻辑,且提供的接口与使用风格也与Guava Cache无异。所以,从这个层面而言,本人更愿意将Caffeine看作是Guava Cache的一种优秀基因的传承与发扬光大,而非是竞争与打压关系。
那么Caffeine能够青出于蓝的秘诀在哪呢?下面总结了其最关键的3大要点,一起看下。
贯穿始终的异步策略
Caffeine在请求上的处理流程做了很多的优化,效果比较显著的当属数据淘汰处理执行策略的改进。之前在Guava Cache的介绍中,有提过Guava Cache的策略是在请求的时候同时去执行对应的清理操作,也就是读请求中混杂着写操作,虽然Guava Cache做了一系列的策略来减少其触发的概率,但一旦触发总归是会对读取操作的性能有一定的影响。

Caffeine则采用了异步处理的策略,get请求中虽然也会触发淘汰数据的清理操作,但是将清理任务添加到了独立的线程池中进行异步的不会阻塞 get 请求的执行与返回,这样大大缩短了get请求的执行时长,提升了响应性能。
除了对自身的异步处理优化,Caffeine还提供了全套的Async异步处理机制,可以支持业务在异步并行流水线式处理场景中使用以获得更加丝滑的体验。
Caffeine完美的支持了在异步场景下的流水线处理使用场景,回源操作也支持异步的方式来完成。CompletableFuture并行流水线能力,是JAVA8在异步编程领域的一个重大改进。可以将一系列耗时且无依赖的操作改为并行同步处理,并等待各自处理结果完成后继续进行后续环节的处理,由此来降低阻塞等待时间,进而达到降低请求链路时长的效果。
比如下面这段异步场景使用Caffeine并行处理的代码:
public static void main(String[] args) throws Exception {
AsyncLoadingCache<String, String> asyncLoadingCache = buildAsyncLoadingCache();
// 写入缓存记录(value值为异步获取)
asyncLoadingCache.put("key1", CompletableFuture.supplyAsync(() -> "value1"));
// 异步方式获取缓存值
CompletableFuture<String> completableFuture = asyncLoadingCache.get("key1");
String value = completableFuture.join();
System.out.println(value);
}ConcurrentHashMap优化特性
作为使用JAVA8新特性进行构建的Caffeine,充分享受了JAVA8语言层面优化改进所带来的性能上的增益。我们知道ConcurrentHashMap是JDK原生提供的一个线程安全的HashMap容器类型,而Caffeine底层也是基于ConcurrentHashMap进行构建与数据存储的。
在JAVA7以及更早的版本中,ConcurrentHashMap采用的是分段锁的策略来实现线程安全的(前面文章中我们讲过Guava Cache采用的也是分段锁的策略),分段锁虽然在一定程度上可以降低锁竞争的冲突,但是在一些极高并发场景下,或者并发请求分布较为集中的时候,仍然会出现较大概率的阻塞等待情况。此外,这些版本中ConcurrentHashMap底层采用的是数组+链表的存储形式,这种情况在Hash冲突较为明显的情况下,需要频繁的遍历链表操作,也会影响整体的处理性能。
淘汰算法W-LFU的加持
常规的缓存淘汰算法一般采用FIFO、LRU或者LFU,但是这些算法在实际缓存场景中都会存在一些弊端:
| 算法 | 弊端说明 |
|---|---|
| FIFO | 先进先出策略,属于一种最为简单与原始的策略。如果缓存使用频率较高,会导致缓存数据始终在不停的进进出出,影响性能,且命中率表现也一般。 |
| LRU | 最近最久未使用策略,保留最近被访问到的数据,而淘汰最久没有被访问的数据。如果遇到偶尔的批量刷数据情况,很容易将其他缓存内容都挤出内存,带来缓存击穿的风险。 |
| LFU | 最近少频率策略,这种根据访问次数进行淘汰,相比而言内存中存储的热点数据命中率会更高些,缺点就是需要维护独立字段用来记录每个元素的访问次数,占用内存空间。 |
为了保证命中率,一般缓存框架都会选择使用LRU或者LFU策略,很少会有使用FIFO策略进行数据淘汰的。Caffeine缓存的LFU采用了Count-Min Sketch频率统计算法(参见下图示意,图片来源:点此查看),由于该LFU的计数器只有4bit大小,所以称为TinyLFU。在TinyLFU算法基础上引入一个基于LRU的Window Cache,这个新的算法叫就叫做W-TinyLFU。
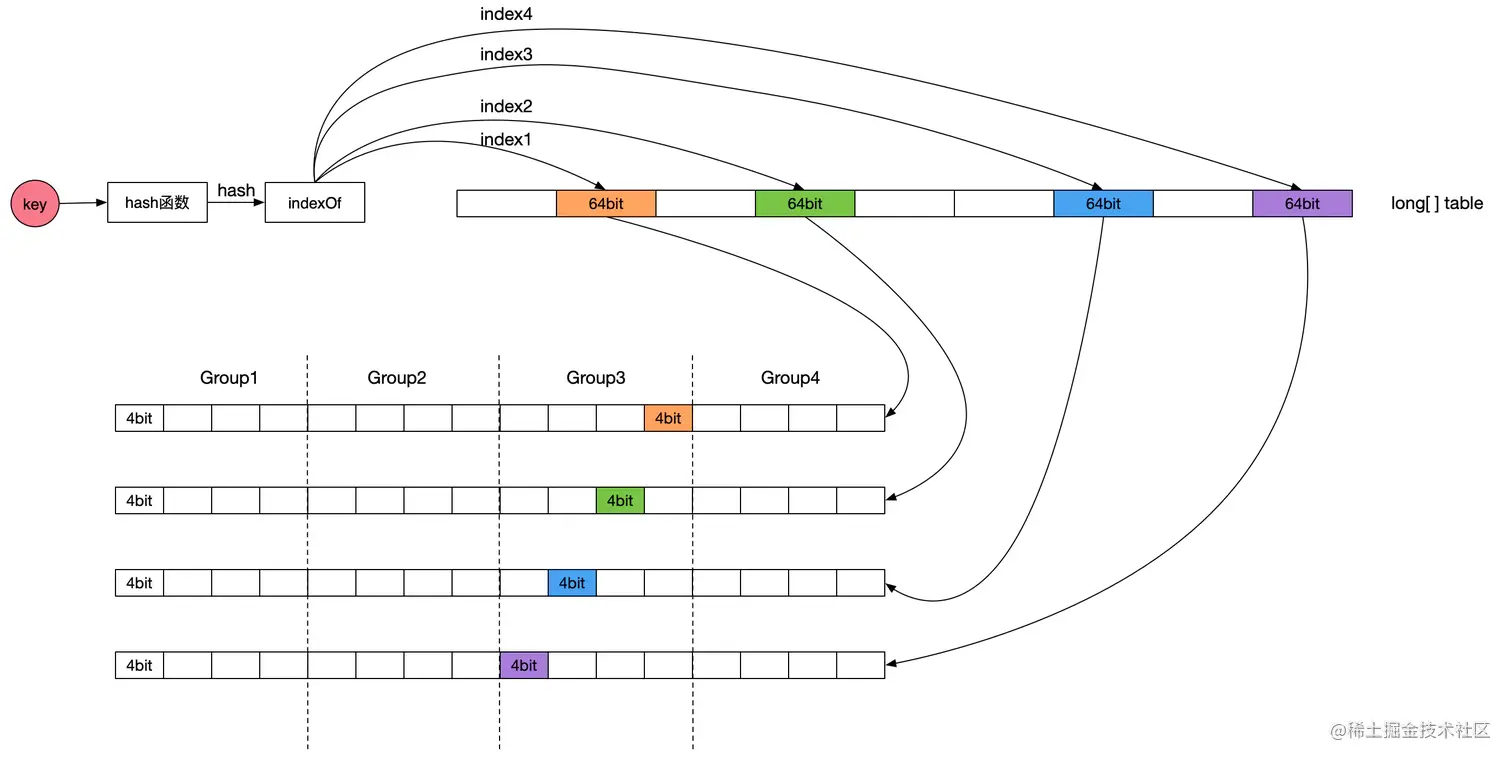
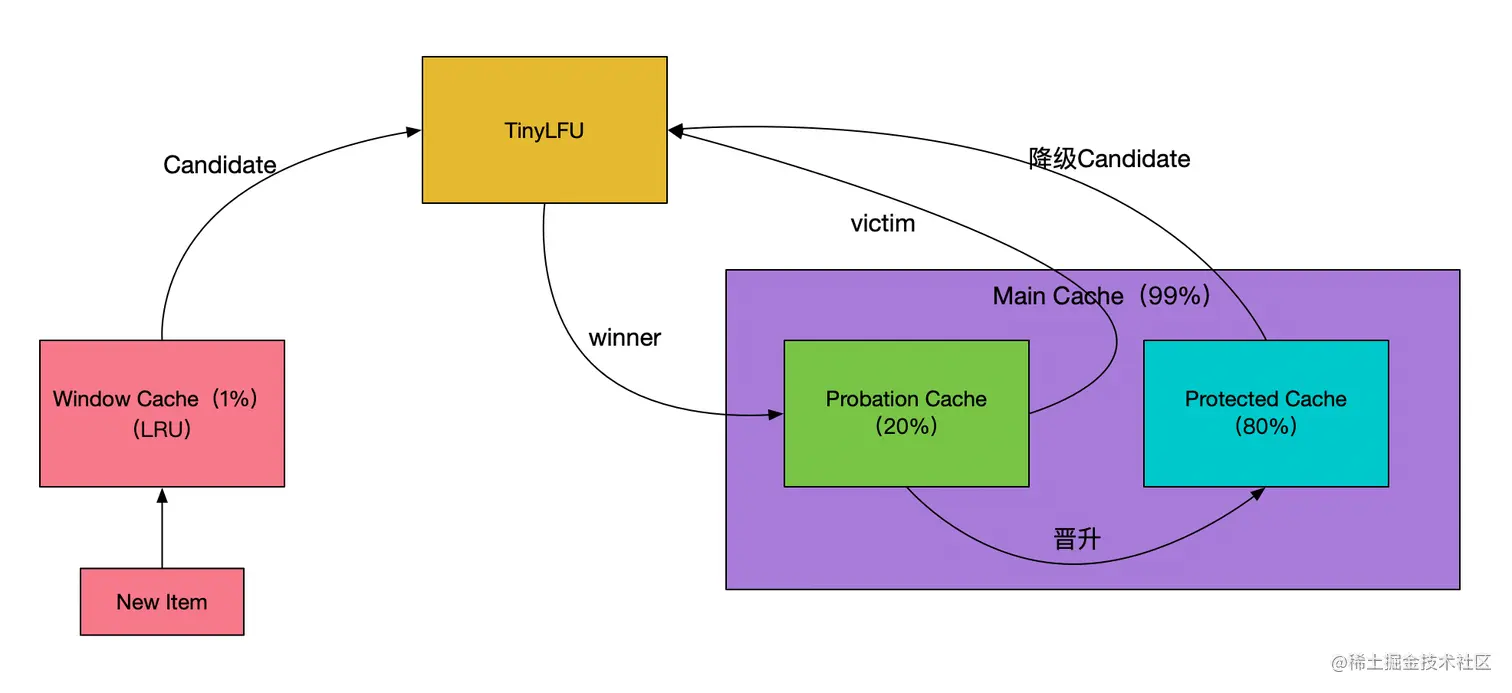
W-TinyLFU算法有效的解决了LRU以及LFU存在的弊端,为Caffeine提供了大部分场景下近乎完美的命中率表现。
关于W-TinyLFU的具体说明,有兴趣的话可以点此了解。
如何选择
在Caffeine与Guava Cache之间如何选择?其实Spring已经给大家做了示范,从Spring5开始,其内置的本地缓存框架由Guava Cache切换到了Caffeine。应用到项目中的缓存选型,可以结合项目实际从多个方面进行抉择。
- 全新项目,闭眼选Caffeine。Java8也已经被广泛的使用多年,现在的新项目基本上都是JAVA8或以上的版本了。如果有新的项目需要做本地缓存选型,闭眼选择Caffeine就可以,错不了。
- 历史低版本JAVA项目:由于Caffeine对JAVA版本有依赖要求,对于一些历史项目的维护而言,如果项目的JDK版本过低则无法使用Caffeine,这种情况下
Guava Cache依旧是一个不错的选择。当然,也可以下定决心将项目的JDK版本升级到JDK1.8+版本,然后使用Caffeine来获得更好的性能体验 —— 但是对于一个历史项目而言,升级基础JDK版本带来的影响可能会比较大,需要提前评估好。 - 有同时使用Guava其它能力 如果你的项目里面已经有引入并使用了Guava提供的相关功能,这种情况下为了避免太多外部组件的引入,也可以直接使用Guava提供的Cache组件能力,毕竟Guava Cache的表现并不算差,应付常规场景的本都缓存诉求完全足够。当然,为了追求更加极致的性能表现,另外引入并使用Caffeine也完全没有问题。
Caffeine使用
依赖引入
使用Caffeine,首先需要引入对应的库文件。如果是Maven项目,则可以在pom.xml中添加依赖声明来完成引入。
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>3.1.1</version>
</dependency>注意,如果你的本地JDK版本比较低,引入上述较新版本的时候可能会编译报错:

遇到这种情况,可以考虑升级本地JDK版本(实际项目中升级可能有难度),或者将Caffeine版本降低一些,比如使用2.9.3版本。具体的版本列表,可以点击此处进行查询。
容器创建
和之前我们聊过的Guava Cache创建缓存对象的操作相似,我们可以通过构造器来方便的创建出一个Caffeine对象。
Cache<Integer, String> cache = Caffeine.newBuilder().build();除了上述这种方式,Caffeine还支持使用不同的构造器方法,构建不同类型的Caffeine对象。对各种构造器方法梳理如下:
| 方法 | 含义说明 |
|---|---|
| build() | 构建一个手动回源的Cache对象 |
| build(CacheLoader) | 构建一个支持使用给定CacheLoader对象进行自动回源操作的LoadingCache对象 |
| buildAsync() | 构建一个支持异步操作的异步缓存对象 |
| buildAsync(CacheLoader) | 使用给定的CacheLoader对象构建一个支持异步操作的缓存对象 |
| buildAsync(AsyncCacheLoader) | 与buildAsync(CacheLoader)相似,区别点仅在于传入的参数类型不一样。 |
手动异步数据加载
为了便于异步场景中处理,可以通过buildAsync()构建一个手动回源数据加载的缓存对象:
public static void main(String[] args) {
AsyncCache<String, User> asyncCache = Caffeine.newBuilder().buildAsync();
User user = asyncCache.get("123", s -> {
System.out.println("异步callable thread:" + Thread.currentThread().getId());
// 查找缓存元素,如果不存在,则异步数据加载
return userDao.getUser(s);
}).join();
}一个AsyncCache是 Cache的一个变体,AsyncCache提供了在 Executor上生成缓存元素并返回 CompletableFuture的能力。这给出了在当前流行的响应式编程模型中利用缓存的能力。
synchronous()方法给 Cache提供了阻塞直到异步缓存生成完毕的能力。
异步缓存默认的线程池实现是 ForkJoinPool.commonPool() ,你也可以通过覆盖并实现 Caffeine.executor(Executor)方法来自定义你的线程池选择。
自动异步数据加载
当然,为了支持异步场景中的自动异步回源,我们可以通过buildAsync(CacheLoader)或者buildAsync(AsyncCacheLoader)来实现:
public static void main(String[] args) throws Exception{
AsyncLoadingCache<String, User> asyncLoadingCache =
Caffeine.newBuilder().maximumSize(1000L).buildAsync(key -> userDao.getUser(key));
// get缓存元素,如果其不存在,将会通过上面方式异步生成
User user = asyncLoadingCache.get("123").join();
}其它常见方法
在创建缓存对象的同时,可以指定此缓存对象的一些处理策略,比如容量限制、比如过期策略等等。作为以替换Guava Cache为己任的后继者,Caffeine在缓存容器对象创建时的相关构建API也沿用了与Guava Cache相同的定义,常见的方法及其含义梳理如下:
| 方法 | 含义说明 |
|---|---|
| initialCapacity | 待创建的缓存容器的初始容量大小(记录条数) |
| maximumSize | 指定此缓存容器的最大容量(最大缓存记录条数) |
| maximumWeight | 指定此缓存容器的最大容量(最大比重值),需结合weighter方可体现出效果 |
| expireAfterWrite | 设定过期策略,按照数据写入时间进行计算 |
| expireAfterAccess | 设定过期策略,按照数据最后访问时间来计算 |
| expireAfter | 基于个性化定制的逻辑来实现过期处理(可以定制基于新增、读取、更新等场景的过期策略,甚至支持为不同记录指定不同过期时间) |
| weighter | 入参为一个函数式接口,用于指定每条存入的缓存数据的权重占比情况。这个需要与maximumWeight结合使用 |
| refreshAfterWrite | 缓存写入到缓存之后 |
| recordStats | 设定开启此容器的数据加载与缓存命中情况统计 |
综合上述方法,我们可以创建出更加符合自己业务场景的缓存对象。
public static void main(String[] args) {
AsyncLoadingCache<String, User> asyncLoadingCache = CaffeinenewBuilder()
.initialCapacity(1000) // 指定初始容量
.maximumSize(10000L) // 指定最大容量
.expireAfterWrite(30L, TimeUnit.MINUTES) // 指定写入30分钟后过期
.refreshAfterWrite(1L, TimeUnit.MINUTES) // 指定每隔1分钟刷新下数据内容
.removalListener((key, value, cause) ->
System.out.println(key + "移除,原因:" + cause)) // 监听记录移除事件
.recordStats() // 开启缓存操作数据统计
.buildAsync(key -> userDao.getUser(key)); // 构建异步CacheLoader加载类型的缓存对象
}业务使用
Caffeine支持创建出同步缓存与异步缓存,也即Cache与AsyncCache两种不同类型。而如果指定了CacheLoader的时候,又可以细分出LoadingCache子类型与AsyncLoadingCache子类型。对于常规业务使用而言,知道这四种类型的缓存类型基本就可以满足大部分场景的正常使用了。但是Caffeine的整体缓存类型其实是细分成了很多不同的具体类型的,从下面的UML图上可以看出一二。
- 同步缓存

- 异步缓存

业务层面对缓存的使用,无外乎往缓存里面写入数据、从缓存里面读取数据。不管是同步还是异步,常见的用于操作缓存的方法梳理如下:
| 方法 | 含义说明 |
|---|---|
| get | 根据key获取指定的缓存值,如果没有则执行回源操作获取 |
| getAll | 根据给定的key列表批量获取对应的缓存值,返回一个map格式的结果,没有命中缓存的部分会执行回源操作获取 |
| getIfPresent | 不执行回源操作,直接从缓存中尝试获取key对应的缓存值 |
| getAllPresent | 不执行回源操作,直接从缓存中尝试获取给定的key列表对应的值,返回查询到的map格式结果, 异步场景不支持此方法 |
| put | 向缓存中写入指定的key与value记录 |
| putAll | 批量向缓存中写入指定的key-value记录集,异步场景不支持此方法 |
| asMap | 将缓存中的数据转换为map格式返回 |
针对同步缓存,业务代码中操作使用举例如下:
public static void main(String[] args) throws Exception {
LoadingCache<String, String> loadingCache = buildLoadingCache();
loadingCache.put("key1", "value1");
String value = loadingCache.get("key1");
System.out.println(value);
}同样地,异步缓存的时候,业务代码中操作示意如下:
public static void main(String[] args) throws Exception {
AsyncLoadingCache<String, String> asyncLoadingCache = buildAsyncLoadingCache();
// 写入缓存记录(value值为异步获取)
asyncLoadingCache.put("key1", CompletableFuture.supplyAsync(() -> "value1"));
// 异步方式获取缓存值
CompletableFuture<String> completableFuture = asyncLoadingCache.get("key1");
String value = completableFuture.join();
System.out.println(value);
}同步&异步回源方式
作为一种对外提供黑盒缓存能力的专门组件,Caffeine基于穿透型缓存模式进行构建。也即对外提供数据查询接口,会优先在缓存中进行查询,若命中缓存则返回结果,未命中则尝试去真正的源端(如:数据库)去获取数据并回填到缓存中,返回给调用方。

与Guava Cache相似,Caffeine的回源填充主要有两种手段:
Callable方式CacheLoader方式
根据执行调用方式不同,又可以细分为同步阻塞方式与异步非阻塞方式。
本文我们就一起探寻下Caffeine的多种不同的数据回源方式,以及对应的实际使用。
同步方式
同步方式是最常被使用的一种形式。查询缓存、数据回源、数据回填缓存、返回执行结果等一系列操作都是在一个调用线程中同步阻塞完成的。

Callable
在每次get请求的时候,传入一个Callable函数式接口具体实现,当没有命中缓存的时候,Caffeine框架会执行给定的Callable实现逻辑,去获取真实的数据并且回填到缓存中,然后返回给调用方。
public static void main(String[] args) {
Cache<String, User> cache = Caffeine.newBuilder().build();
User user = cache.get("123", s -> userDao.getUser(s));
System.out.println(user);
}Callable方式的回源填充,有个明显的优势就是调用方可以根据自己的场景,灵活的给定不同的回源执行逻辑。但是这样也会带来一个问题,就是如果需要获取缓存的地方太多,会导致每个调用的地方都得指定下对应Callable回源方法,调用起来比较麻烦,且对于需要保证回源逻辑统一的场景管控能力不够强势,无法约束所有的调用方使用相同的回源逻辑。
这种时候,便需要CacheLoader登场了。
CacheLoader
在创建缓存对象的时候,可以通在build()方法中传入指定的CacheLoader对象的方式来指定回源时默认使用的回源数据加载器,这样当使用方调用get方法获取不到数据的时候,框架就会自动使用给定的CacheLoader对象执行对应的数据加载逻辑。
比如下面的代码中,便在创建缓存对象时指定了当缓存未命中时通过userDao.getUser()方法去DB中执行数据查询操作:
public LoadingCache<String, User> createUserCache() {
return Caffeine.newBuilder()
.maximumSize(10000L)
.build(key -> userDao.getUser(key));
}相比于Callable方式,CacheLoader更适用于所有回源场景使用的回源策略都固定且统一的情况。对具体业务使用的时候更加的友好,调用get方法也更加简单,只需要传入带查询的key值即可。
上面的示例代码中还有个需要关注的点,即创建缓存对象的时候指定了CacheLoader,最终创建出来的缓存对象是LoadingCache类型,这个类型是Cache的一个子类,扩展提供了无需传入Callable参数的get方法。进一步地,我们打印出对应的详细类名,会发现得到的缓存对象具体类型为:
com.github.benmanes.caffeine.cache.BoundedLocalCache.BoundedLocalLoadingCache当然,如果创建缓存对象的时候没有指定最大容量限制,则创建出来的缓存对象还可能会是下面这个:
com.github.benmanes.caffeine.cache.UnboundedLocalCache.UnboundedLocalManualCache通过UML图,可以清晰的看出其与Cache之间的继承与实现链路情况:

因为LoadingCache是Cache对象的子类,根据JAVA中类继承的特性,LoadingCache也完全具备Cache所有的接口能力。所以,对于大部分场景都需要固定且统一的回源方式,但是某些特殊场景需要自定义回源逻辑的情况,也可以通过组合使用Callable的方式来实现。
比如下面这段代码:
public static void main(String[] args) {
LoadingCache<String, User> cache = Caffeine.newBuilder().build(userId -> userDao.getUser(userId));
// 使用CacheLoader回源
User user = cache.get("123");
System.out.println(user);
// 使用自定义Callable回源
User techUser = cache.get("J234", userId -> {
// 仅J开头的用户ID才会去回源
if (!StringUtils.isEmpty(userId) && userId.startsWith("J")) {
return userDao.getUser(userId);
} else {
return null;
}
});
System.out.println(techUser);
}上述代码中,构造的是一个指定了CacheLoader的LoadingCache缓存类型,这样对于大众场景可以直接使用get方法由CacheLoader提供统一的回源能力,而特殊场景中也可以在get方法中传入需要的定制化回源Callable逻辑。
不回源
在实际的缓存应用场景中,并非是所有的场景都要求缓存没有命中的时候要去执行回源查询。对于一些业务规划上无需执行回源操作的请求,也可以要求Caffeine不要执行回源操作(比如黑名单列表,只要用户在黑名单就禁止操作,不在黑名单则允许继续往后操作,因为大部分请求都不会命中到黑名单中,所以不需要执行回源操作)。为了实现这一点,在查询操作的时候,可以使用Caffeine提供的免回源查询方法来实现。
具体梳理如下:
| 接口 | 功能说明 |
|---|---|
| getIfPresent | 从内存中查询,如果存在则返回对应值,不存在则返回null |
| getAllPresent | 批量从内存中查询,如果存在则返回存在的键值对,不存在的key则不出现在结果集里 |
代码使用演示如下:
public static void main(String[] args) {
LoadingCache<String, User> cache = Caffeine.newBuilder().build(userId -> userDao.getUser(userId));
cache.put("124", new User("124", "张三"));
User userInfo = cache.getIfPresent("123");
System.out.println(userInfo);
Map<String, User> presentUsers =
cache.getAllPresent(Stream.of("123", "124", "125").collect(Collectors.toList()));
System.out.println(presentUsers);
}执行结果如下,可以发现执行的过程中并没有触发自动回源与回填操作:
null
{124=User(userName=张三, userId=124)}异步方式
CompletableFuture并行流水线能力,是JAVA8在异步编程领域的一个重大改进。可以将一系列耗时且无依赖的操作改为并行同步处理,并等待各自处理结果完成后继续进行后续环节的处理,由此来降低阻塞等待时间,进而达到降低请求链路时长的效果。
Caffeine完美的支持了在异步场景下的流水线处理使用场景,回源操作也支持异步的方式来完成。
异步Callable
要想支持异步场景下使用缓存,则创建的时候必须要创建一个异步缓存类型,可以通过buildAsync()方法来构建一个AsyncCache类型缓存对象,进而可以在异步场景下进行使用。
看下面这段代码:
public static void main(String[] args) {
AsyncCache<String, User> asyncCache = Caffeine.newBuilder().buildAsyn();
CompletableFuture<User> userCompletableFuture = asyncCache.get("123", s -> userDao.getUser(s));
System.out.println(userCompletableFuture.join());
}上述代码中,get方法传入了Callable回源逻辑,然后会开始异步的加载处理操作,并返回了个CompletableFuture类型结果,最后如果需要获取其实际结果的时候,需要等待其异步执行完成然后获取到最终结果(通过上述代码中的join()方法等待并获取结果)。
我们可以比对下同步和异步两种方式下Callable逻辑执行线程情况。看下面的代码:
public static void main(String[] args) {
System.out.println("main thread:" + Thread.currentThread().getId());
// 同步方式
Cache<String, User> cache = Caffeine.newBuilder().build();
cache.get("123", s -> {
System.out.println("同步callable thread:" + Thread.currentThread().getId());
return userDao.getUser(s);
});
// 异步方式
AsyncCache<String, User> asyncCache = Caffeine.newBuilder().buildAsync();
asyncCache.get("123", s -> {
System.out.println("异步callable thread:" + Thread.currentThread().getId());
return userDao.getUser(s);
});
}执行结果如下:
main thread:1
同步callable thread:1
异步callable thread:15结果很明显的可以看出,同步处理逻辑中,回源操作直接占用的调用线程进行操作,而异步处理时则是单独线程负责回源处理、不会阻塞调用线程的执行 —— 这也是异步处理的优势所在。
看到这里,也许会有小伙伴有疑问,虽然是异步执行的回源操作,但是最后还是要在调用线程里面阻塞等待异步执行结果的完成,似乎没有看出异步有啥优势?
异步处理的魅力,在于当一个耗时操作执行的同时,主线程可以继续去处理其它的事情,然后其余事务处理完成后,直接去取异步执行的结果然后继续往后处理。如果主线程无需执行其余处理逻辑,完全是阻塞等待异步线程加载完成,这种情况确实没有必要使用异步处理。
想象一个生活中的场景:
周末休息的你出去逛街,去咖啡店点了一杯咖啡,然后服务员会给你一个订单小票。 当服务员在后台制作咖啡的时候,你并没有在店里等待,而是出门到隔壁甜品店又买了个面包。 当面包买好之后,你回到咖啡店,拿着订单小票去取咖啡。 取到咖啡后,你边喝咖啡边把面包吃了……嗝~

这种情况应该比较好理解了吧?如果是同步处理,你买咖啡的时候,需要在咖啡店一直等到咖啡做好然后才能再去甜品店买面包,这样耗时就比较长了。而采用异步处理的策略,你在等待咖啡制作的时候,继续去甜品店将面包买了,然后回来等待咖啡完成,这样整体的时间就缩短了。当然,如果你只想买个咖啡,也不需要买甜品面包,即你等待咖啡制作期间没有别的事情需要处理,那这时候你在不在咖啡店一直等到咖啡完成,都没有区别。
回到代码层面,下面代码演示了异步场景下AsyncCache的使用。
public boolean isDevUser(String userId) {
// 获取用户信息
CompletableFuture<User> userFuture = asyncCache.get(userId, s -> userDao.getUser(s));
// 获取公司研发体系部门列表
CompletableFuture<List<String>> devDeptFuture =
CompletableFuture.supplyAsync(() -> departmentDao.getDevDepartments());
// 等用户信息、研发部门列表都拉取完成后,判断用户是否属于研发体系
CompletableFuture<Boolean> combineResult =
userFuture.thenCombine(devDeptFuture,
(user, devDepts) -> devDepts.contains(user.getDepartmentId()));
// 等待执行完成,调用线程获取最终结果
return combineResult.join();
}在上述代码中,需要获取到用户详情与研发部门列表信息,然后判断用户对应的部门是否属于研发部门,从而判断员工是否为研发人员。整体采用异步编程的思路,并使用了Caffeine异步缓存的操作方式,实现了用户获取与研发部门列表获取这两个耗时操作并行的处理,提升整体处理效率。

异步CacheLoader
异步处理的时候,Caffeine也支持直接在创建的时候指定CacheLoader对象,然后生成支持异步回源操作的AsyncLoadingCache缓存对象,然后在使用get方法获取结果的时候,也是返回的CompletableFuture异步封装类型,满足在异步编程场景下的使用。
public static void main(String[] args) {
try {
AsyncLoadingCache<String, User> asyncLoadingCache =
Caffeine.newBuilder().maximumSize(1000L).buildAsync(key -> userDao.getUser(key));
CompletableFuture<User> userCompletableFuture = asyncLoadingCache.get("123");
System.out.println(userCompletableFuture.join());
} catch (Exception e) {
e.printStackTrace();
}
}异步AsyncCacheLoader
除了上述这种方式,在创建的时候给定一个用于回源处理的CacheLoader之外,Caffeine还有一个buildAsync的重载版本,允许传入一个同样是支持异步并行处理的AsyncCacheLoader对象。使用方式如下:
public static void main(String[] args) {
try {
AsyncLoadingCache<String, User> asyncLoadingCache =
Caffeine.newBuilder().maximumSize(1000L).buildAsync(
(key, executor) -> CompletableFuture.supplyAsync(() -> userDao.getUser(key), executor)
);
CompletableFuture<User> userCompletableFuture = asyncLoadingCache.get("123");
System.out.println(userCompletableFuture.join());
} catch (Exception e) {
e.printStackTrace();
}
}与上一章节中的代码比对可以发现,不管是使用CacheLoader还是AsyncCacheLoader对象,最终生成的缓存类型都是AsyncLoadingCache类型,使用的时候也并没有实质性的差异,两种方式的差异点仅在于传入buildAsync方法中的对象类型不同而已,使用的时候可以根据喜好自行选择。
进一步地,如果我们尝试将上面代码中的asyncLoadingCache缓存对象的具体类型打印出来,我们会发现其具体类型可能是:
com.github.benmanes.caffeine.cache.BoundedLocalCache.BoundedLocalAsyncLoadingCache而如果我们在构造缓存对象的时候没有限制其最大容量信息,其构建出来的缓存对象类型还可能会是下面这个:
com.github.benmanes.caffeine.cache.UnboundedLocalCache.UnboundedLocalAsyncLoadingCache与前面同步方式一样,我们也可以看下这两个具体的缓存类型对应的UML类图关系:

可以看出,异步缓存不同类型最终都实现了同一个AsyncCache顶层接口类,而AsyncLoadingCache作为继承自AsyncCache的子类,除具备了AsyncCache的所有接口外,还额外扩展了部分的接口,以支持未命中目标时自动使用指定的CacheLoader或者AysncCacheLoader对象去执行回源逻辑。
数据驱逐淘汰机制与用法
Caffeine的异步淘汰清理机制
在惰性删除实现机制这边,Caffeine做了一些改进优化以提升在并发场景下的性能表现。我们可以和Guava Cache的基于容量大小的淘汰处理做个对比。
当限制了Guava Cache最大容量之后,有新的记录写入超过了总大小,会立即触发数据淘汰策略,然后腾出空间给新的记录写入。比如下面这段逻辑:
public static void main(String[] args) {
Cache<String, String> cache = CacheBuilder.newBuilder()
.maximumSize(1)
.removalListener(notification -> System.out.println(notification.getKey() + "被移除,原因:" + notification.getCause()))
.build();
cache.put("key1", "value1");
System.out.println("key1写入后,当前缓存内的keys:" + cache.asMap().keySet());
cache.put("key2", "value1");
System.out.println("key2写入后,当前缓存内的keys:" + cache.asMap().keySet());
}其运行后的结果显示如下,可以很明显的看出,超出容量之后继续写入,会在写入前先执行缓存移除操作。
key1写入后,当前缓存内的keys:[key1]
key1被移除,原因:SIZE
key2写入后,当前缓存内的keys:[key2]同样地,我们看下使用Caffeine实现一个限制容量大小的缓存对象的处理表现,代码如下:
public static void main(String[] args) {
Cache<String, String> cache = Caffeine.newBuilder()
.maximumSize(1)
.removalListener((key, value, cause) -> System.out.println(key + "被移除,原因:" + cause))
.build();
cache.put("key1", "value1");
System.out.println("key1写入后,当前缓存内的keys:" + cache.asMap().keySet());
cache.put("key2", "value1");
System.out.println("key2写入后,当前缓存内的keys:" + cache.asMap().keySet());
}运行这段代码,会发现Caffeine的容量限制功能似乎“失灵”了!从输出结果看并没有限制住:
key1写入后,当前缓存内的keys:[key1]
key2写入后,当前缓存内的keys:[key1, key2]什么原因呢?
Caffeine为了提升读写操作的并发效率而将数据淘汰清理操作改为了异步处理,而异步处理时会有微小的延时,由此导致了上述看到的容量控制“失灵”现象。为了证实这一点,我们对上述的测试代码稍作修改,打印下调用线程与数据淘汰清理线程的线程ID,并且最后添加一个sleep等待操作:
public static void main(String[] args) throws Exception {
System.out.println("当前主线程:" + Thread.currentThread().getId());
Cache<String, String> cache = Caffeine.newBuilder()
.maximumSize(1)
.removalListener((key, value, cause) ->
System.out.println("数据淘汰执行线程:" + Thread.currentThread().getId()
+ "," + key + "被移除,原因:" + cause))
.build();
cache.put("key1", "value1");
System.out.println("key1写入后,当前缓存内的keys:" + cache.asMap().keySe());
cache.put("key2", "value1");
Thread.sleep(1000L); // 等待一段时间时间,等待异步清理操作完成
System.out.println("key2写入后,当前缓存内的keys:" + cache.asMap().keySet());
}再次执行上述测试代码,发现结果变的符合预期了,也可以看出Caffeine的确是另起了独立线程去执行数据淘汰操作的。
当前主线程:1
key1写入后,当前缓存内的keys:[key1]
数据淘汰执行线程:13,key1被移除,原因:SIZE
key2写入后,当前缓存内的keys:[key2]深扒一下源码的实现,可以发现Caffeine在读写操作时会使用独立线程池执行对应的清理任务,如下图中的调用链执行链路 —— 这也证实了上面我们的分析。
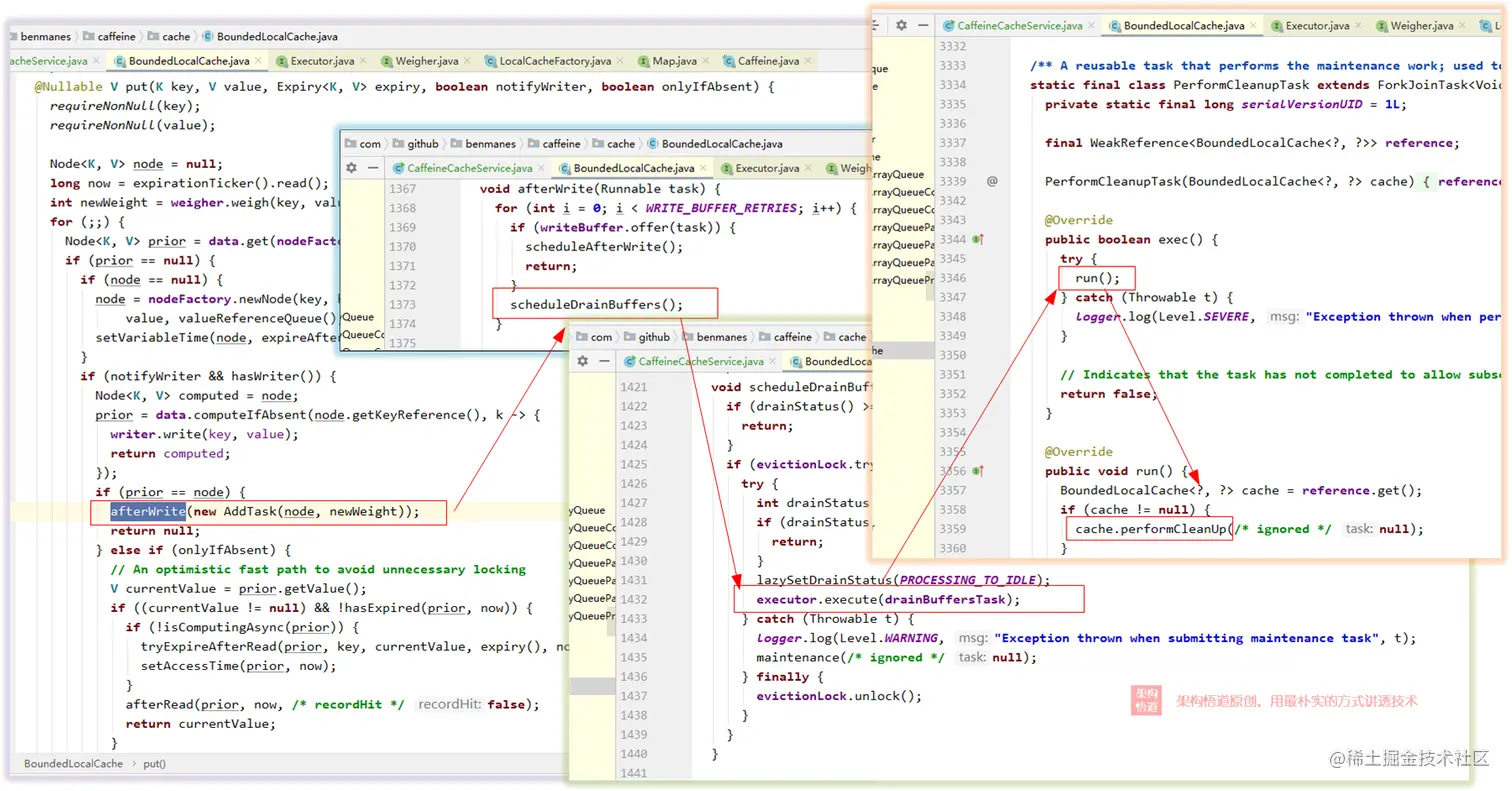
所以,严格意义来说,Caffeine的大小容量限制并不能够保证完全精准的小于设定的值,会存在短暂的误差,但是作为一个以高并发吞吐量为优先考量点的组件而言,这一点点的误差也是可以接受的。关于这一点,如果阅读源码仔细点的小伙伴其实也可以发现在很多场景的注释中,Caffeine也都会有明确的说明。比如看下面这段从源码中摘抄的描述,就清晰的写着“如果有同步执行的插入或者移除操作,实际的元素数量可能会出现差异”。
public interface Cache<K, V> {
/**
* Returns the approximate number of entries in this cache. The value returned is an estimate; the
* actual count may differ if there are concurrent insertions or removals, or if some entries are
* pending removal due to expiration or weak/soft reference collection. In the case of stale
* entries this inaccuracy can be mitigated by performing a {@link #cleanUp()} first.
*
* @return the estimated number of mappings
*/
@NonNegative
long estimatedSize();
// 省略其余内容...
}同样道理,不管是基于大小、还是基于过期时间或基于引用的数据淘汰策略,由于数据淘汰处理是异步进行的,都会存在短暂的不够精确的情况。
Caffeine多种数据驱逐机制
上面提到并演示了Caffeine基于整体容量进行的数据驱逐策略。Caffeine 除了提供了基于容量,基于时间和基于引用三种类型的三种驱逐策略;还提供了手动移除方法和监听器。
基于时间
Caffine支持基于时间进行数据的淘汰驱逐处理。这部分的能力与Guava Cache相同,支持根据记录创建时间以及访问时间两个维度进行处理。
数据的过期时间在创建缓存对象的时候进行指定,Caffeine在创建缓存对象的时候提供了3种设定过期策略的方法。
| 方式 | 具体说明 |
|---|---|
| expireAfterWrite | 基于创建时间进行过期处理 |
| expireAfterAccess | 基于最后访问时间进行过期处理 |
| expireAfter | 基于个性化定制的逻辑来实现过期处理(可以定制基于新增、读取、更新等场景的过期策略,甚至支持为不同记录指定不同过期时间) |
下面逐个看下。
expireAfterWrite
expireAfterWrite用于指定数据创建之后多久会过期,使用方式举例如下:
Cache<String, User> userCache =
Caffeine.newBuilder()
.expireAfterWrite(1, TimeUnit.SECONDS)
.build();
userCache.put("123", new User("123", "张三"));当记录被写入缓存之后达到指定的时间之后,就会被过期淘汰(惰性删除,并不会立即从内存中移除,而是在下一次操作的时候触发清理操作)。
expireAfterAccess
expireAfterAccess用于指定缓存记录多久没有被访问之后就会过期。使用方式与expireAfterWrite类似:
Cache<String, User> userCache =
Caffeine.newBuilder()
.expireAfterAccess(1, TimeUnit.SECONDS)
.build();
userCache.get("123", s -> userDao.getUser(s));这种是基于最后一次访问时间来计算数据是否过期,如果一个数据一直被访问,则其就不会过期。比较适用于热点数据的存储场景,可以保证较高的缓存命中率。同样地,数据过期时也不会被立即从内存中移除,而是基于惰性删除机制进行处理。
expireAfter
上面两种设定过期时间的策略与Guava Cache是相似的。为了提供更为灵活的过期时间设定能力,Caffeine提供了一种全新的的过期时间设定方式,也即这里要介绍的expireAfter方法。其支持传入一个自定义的Expiry对象,自行实现数据的过期策略,甚至是针对不同的记录来定制不同的过期时间。
先看下Expiry接口中需要实现的三个方法:
| 方法名称 | 含义说明 |
|---|---|
| expireAfterCreate | 指定一个过期时间,从记录创建的时候开始计时,超过指定的时间之后就过期淘汰,效果类似expireAfterWrite,但是支持更灵活的定制逻辑。 |
| expireAfterUpdate | 指定一个过期时间,从记录最后一次被更新的时候开始计时,超过指定的时间之后就过期。每次执行更新操作之后,都会重新计算过期时间。 |
| expireAfterRead | 指定一个过期时间,从记录最后一次被访问的时候开始计时,超过指定时间之后就过期。效果类似expireAfterAccess,但是支持更高级的定制逻辑。 |
比如下面的代码中,定制了expireAfterCreate方法的逻辑,根据缓存key来决定过期时间,如果key以字母A开头则设定1s过期,否则设定2s过期:
public static void main(String[] args) {
try {
LoadingCache<String, User> userCache = Caffeine.newBuilder()
.removalListener((key, value, cause) -> {
System.out.println(key + "移除,原因:" + cause);
})
.expireAfter(new Expiry<String, User>() {
@Override
public long expireAfterCreate(@NonNull String key, @NonNullUser value, long currentTime) {
if (key.startsWith("A")) {
return TimeUnit.SECONDS.toNanos(1);
} else {
return TimeUnit.SECONDS.toNanos(2);
}
}
@Override
public long expireAfterUpdate(@NonNull String key, @NonNullUser value, long currentTime,
@NonNegative longcurrentDuration) {
return Long.MAX_VALUE;
}
@Override
public long expireAfterRead(@NonNull String key, @NonNull Uservalue, long currentTime,
@NonNegative long currentDuration){
return Long.MAX_VALUE;
}
})
.build(key -> userDao.getUser(key));
userCache.put("123", new User("123", "123"));
userCache.put("A123", new User("A123", "A123"));
Thread.sleep(1100L);
System.out.println(userCache.get("123"));
System.out.println(userCache.get("A123"));
} catch (Exception e) {
e.printStackTrace();
}
}执行代码进行测试,可以发现,不同的key拥有了不同的过期时间:
User(userName=123, userId=123, departmentId=null)
A123移除,原因:EXPIRED
User(userName=A123, userId=A123, departmentId=null)除了根据key来定制不同的过期时间,也可以根据value的内容来指定不同的过期时间策略。也可以同时定制上述三个方法,搭配来实现更复杂的过期策略。
按照这种方式来定时过期时间的时候需要注意一点,如果不需要设定某一维度的过期策略的时候,需要将对应实现方法的返回值设置为一个非常大的数值,比如可以像上述示例代码中一样,指定为Long.MAX_VALUE值。
基于大小
除了前面提到的基于访问时间或者创建时间来执行数据过期淘汰的方式之外,Caffeine还支持针对缓存总体容量大小进行限制,如果容量满的时候,基于W-TinyLFU算法,淘汰最不常被使用的数据,腾出空间给新的记录写入。
Caffeine支持按照Size(记录条数)或者按照Weighter(记录权重)值进行总体容量的限制。
maximumSize
在创建Caffeine缓存对象的时候,可以通过maximumSize来指定允许缓存的最大条数。
比如下面这段代码:
Cache<Integer, String> cache = Caffeine.newBuilder()
.maximumSize(1000L) // 限制最大缓存条数
.build();maximumWeight
在创建Caffeine缓存对象的时候,可以通过maximumWeight与weighter组合的方式,指定按照权重进行限制缓存总容量。比如一个字符串value值的缓存场景下,我们可以根据字符串的长度来计算权重值,最后根据总权重大小来限制容量。
代码示意如下:
Cache<Integer, String> cache = Caffeine.newBuilder()
.maximumWeight(1000L) // 限制最大权重值
.weigher((key, value) -> (String.valueOf(value).length() / 1000) + 1)
.build();使用注意点
需要注意一点:如果创建的时候指定了weighter,则必须同时指定maximumWeight值,如果不指定、或者指定了maximumSize,会报错(这一点与Guava Cache一致):
java.lang.IllegalStateException: weigher requires maximumWeight
at com.github.benmanes.caffeine.cache.Caffeine.requireState(Caffeine.java:201)
at com.github.benmanes.caffeine.cache.Caffeine.requireWeightWithWeigher(Caffeine.java:1215)
at com.github.benmanes.caffeine.cache.Caffeine.build(Caffeine.java:1099)
at com.veezean.skills.cache.caffeine.CaffeineCacheService.main(CaffeineCacheService.java:254)基于引用
基于引用回收的策略,核心是利用JVM虚拟机的GC机制来达到数据清理的目的。当一个对象不再被引用的时候,JVM会选择在适当的时候将其回收。Caffeine支持三种不同的基于引用的回收方法:
| 方法 | 具体说明 |
|---|---|
| weakKeys | 采用弱引用方式存储key值内容,当key对象不再被引用的时候,由GC进行回收 |
| weakValues | 采用弱引用方式存储value值内容,当value对象不再被引用的时候,由GC进行回收 |
| softValues | 采用软引用方式存储value值内容,当内存容量满时基于LRU策略进行回收 |
关于JVM不同引用的介绍看这篇文章GC - 理论基础
weakKeys
默认情况下,我们创建出一个Caffeine缓存对象并写入key-value映射数据时,key和value都是以强引用的方式存储的。而使用weakKeys可以指定将缓存中的key值以弱引用(WeakReference)的方式进行存储,这样一来,如果程序运行时没有其它地方使用或者依赖此缓存值的时候,该条记录就可能会被GC回收掉。
LoadingCache<String, User> loadingCache = Caffeine.newBuilder()
.weakKeys()
.build(key -> userDao.getUser(key));小伙伴们应该都有个基本的认知,就是两个对象进行比较是否相等的时候,要使用equals方法而非==。而且很多时候我们会主动去覆写hashCode方法与equals方法来指定两个对象的相等判断逻辑。但是基于引用的数据淘汰策略,关注的是引用地址值而非实际内容值,也即一旦使用weakKeys指定了基于引用方式回收,那么查询的时候将只能是使用同一个key对象(内存地址相同)才能够查询到数据,因为这种情况下查询的时候,使用的是==判断是否为同一个key。
看下面的例子:
public static void main(String[] args) {
Cache<String, String> cache = Caffeine.newBuilder()
.weakKeys()
.build();
String key1 = "123";
cache.put(key1, "value1");
System.out.println(cache.getIfPresent(key1));
String key2 = new String("123");
System.out.println("key1.equals(key2) : " + key1.equals(key2));
System.out.println("key1==key2 : " + (key1==key2));
System.out.println(cache.getIfPresent(key2));
}执行之后,会发现使用存入时的key1进行查询的时候是可以查询到数据的,而使用key2去查询的时候并没有查询到记录,虽然key1与key2的值都是字符串123!
key1.equals(key2) : true
key1==key2 : false
null在实际使用的时候,这一点务必需要注意,对于新手而言,很容易踩进坑里。
weakValues
与weakKeys类似,我们可以在创建缓存对象的时候使用weakValues指定将value值以弱引用的方式存储到缓存中。这样当这条缓存记录的对象不再被引用依赖的时候,就会被JVM在适当的时候回收释放掉。
LoadingCache<String, User> loadingCache = Caffeine.newBuilder()
.weakValues()
.build(key -> userDao.getUser(key));实际使用的时候需要注意weakValues不支持在AsyncLoadingCache中使用。比如下面的代码:
public static void main(String[] args) {
AsyncLoadingCache<String, User> cache = Caffeine.newBuilder()
.weakValues()
.buildAsync(key -> userDao.getUser(key));
}启动运行的时候,就会报错:
Exception in thread "main" java.lang.IllegalStateException: Weak or soft values cannot be combined with AsyncLoadingCache
at com.github.benmanes.caffeine.cache.Caffeine.requireState(Caffeine.java:201)
at com.github.benmanes.caffeine.cache.Caffeine.buildAsync(Caffeine.java:1192)
at com.github.benmanes.caffeine.cache.Caffeine.buildAsync(Caffeine.java:1167)
at com.veezean.skills.cache.caffeine.CaffeineCacheService.main(CaffeineCacheService.java:297)当然,很多时候也可以将weakKeys与weakValues组合起来使用,这样可以获得到两种能力的综合加成。
LoadingCache<String, User> loadingCache = Caffeine.newBuilder()
.weakKeys()
.weakValues()
.build(key -> userDao.getUser(key));softValues
softValues是指将缓存内容值以软引用的方式存储在缓存容器中,当内存容量满的时候Caffeine会以LRU(least-recently-used,最近最少使用)顺序进行数据淘汰回收。对比下其与weakValues的差异:
| 方式 | 具体描述 |
|---|---|
| weakValues | 弱引用方式存储,一旦不再被引用,则会被GC回收 |
| softValues | 软引用方式存储,不会被GC回收,但是在内存容量满的时候,会基于LRU策略数据回收 |
具体使用的时候,可以在创建缓存对象的时候进行指定基于软引用方式数据淘汰:
LoadingCache<String, User> loadingCache = Caffeine.newBuilder()
.softValues()
.build(key -> userDao.getUser(key));与weakValues一样,需要注意softValues也不支持在AsyncLoadingCache中使用。此外,还需要注意softValues与weakValues两者也不可以一起使用。
public static void main(String[] args) {
LoadingCache<String, User> cache = Caffeine.newBuilder()
.weakKeys()
.weakValues()
.softValues()
.build(key -> userDao.getUser(key));
}启动运行的时候,也会报错:
Exception in thread "main" java.lang.IllegalStateException: Value strength was already set to WEAK
at com.github.benmanes.caffeine.cache.Caffeine.requireState(Caffeine.java:201)
at com.github.benmanes.caffeine.cache.Caffeine.softValues(Caffeine.java:572)
at com.veezean.skills.cache.caffeine.CaffeineCacheService.main(CaffeineCacheService.java:297)手动移除
Cache<Object, Object> cache =
Caffeine.newBuilder()
.expireAfterWrite(Duration.ofMinutes(1))
.recordStats()
.build();
// 单个删除
cache.invalidate("a");
// 批量删除
Set<String> keys = new HashSet<>();
keys.add("a");
keys.add("b");
cache.invalidateAll(keys);
// 失效所有key
cache.invalidateAll();任何时候都可以手动删除,不用等到驱逐策略生效。
移除监听器
Cache<Object, Object> cache =
Caffeine.newBuilder()
.expireAfterWrite(Duration.ofMinutes(1))
.recordStats()
.evictionListener(new RemovalListener<Object, Object>() {
@Override
public void onRemoval(@Nullable Object key, @Nullable Object value, @NonNull RemovalCause cause) {
System.out.println("element evict cause" + cause.name());
}
})
.removalListener(new RemovalListener<Object, Object>() {
@Override
public void onRemoval(@Nullable Object key, @Nullable Object value, @NonNull RemovalCause cause) {
System.out.println("element removed cause" + cause.name());
}
}).build();你可以为你的缓存通过Caffeine.removalListener(RemovalListener)方法定义一个移除监听器在一个元素被移除的时候进行相应的操作。这些操作是使用Executor异步执行的,其中默认的Executor实现是 ForkJoinPool.commonPool()并且可以通过覆盖Caffeine.executor(Executor)方法自定义线程池的实现。
驱逐原因汇总
- EXPLICIT:如果原因是这个,那么意味着数据被我们手动的remove掉了
- REPLACED:就是替换了,也就是put数据的时候旧的数据被覆盖导致的移除
- COLLECTED:这个有歧义点,其实就是收集,也就是垃圾回收导致的,一般是用弱引用或者软引用会导致这个情况
- EXPIRED:数据过期,无需解释的原因。
- SIZE:个数超过限制导致的移除
缓存统计
Caffeine通过使用Caffeine.recordStats()方法可以打开数据收集功能,可以帮助优化缓存使用。
// 缓存访问统计
CacheStats stats = cache.stats();
System.out.println("stats.hitCount():"+stats.hitCount());//命中次数
System.out.println("stats.hitRate():"+stats.hitRate());//缓存命中率
System.out.println("stats.missCount():"+stats.missCount());//未命中次数
System.out.println("stats.missRate():"+stats.missRate());//未命中率
System.out.println("stats.loadSuccessCount():"+stats.loadSuccessCount());//加载成功的次数
System.out.println("stats.loadFailureCount():"+stats.loadFailureCount());//加载失败的次数,返回null
System.out.println("stats.loadFailureRate():"+stats.loadFailureRate());//加载失败的百分比
System.out.println("stats.totalLoadTime():"+stats.totalLoadTime());//总加载时间,单位ns
System.out.println("stats.evictionCount():"+stats.evictionCount());//驱逐次数
System.out.println("stats.evictionWeight():"+stats.evictionWeight());//驱逐的weight值总和
System.out.println("stats.requestCount():"+stats.requestCount());//请求次数
System.out.println("stats.averageLoadPenalty():"+stats.averageLoadPenalty());//单次load平均耗时参考链接
