在日常业务开发中经常会涉及到使用正则表达式对数据进行处理,比如String的Split()方法,它根据方法中传入的正则表达式对字符串做分割处理。
抛出问题:在正则表达式匹配过程中,特别是在处理复杂的正则表达式时,Java的Matcher 类可能会执行大量的回溯操作。回溯是正则表达式引擎尝试所有可能的匹配路径,直到找到合适的匹配或确定没有匹配为止,这个过程可能是非常耗时的。
匹配的三种方式
看下面这个例子,给定了一个字符串以及三个功能相同但写法略有区别的正则表达式:
String testStr = "effg";
String regular_1 = "ef{1,3}g";
String regular_2 = "ef{1,3}?g";
String regular_3 = "ef{1,3}+g";用split方法测试每个正则表达式运行的时间:
List<String> regulars = new ArrayList<>();
regulars.add(regular_1);
regulars.add(regular_2);
regulars.add(regular_3);
for(String regular : regulars){
long start,end;
start = System.currentTimeMillis();
testStr.split(regular);
end = System.currentTimeMillis();
System.out.println((end - start) + "(ms)");
}控制台输出(为了体现效率差别,测试的时候我将上面的字符串复制成了足够的长度):
2(ms)
1(ms)
0(ms)可以明显看到,虽然实现了相同的匹配功能,但效率却有所区别,原因在于这三种写法定义了正则表达式的三种匹配逻辑,我们来逐一说明:
贪婪模式(Greedy): ef{1,3}g
贪婪模式是正则表达式的默认匹配方式,在该模式下,对于涉及数量的表达式,正则表达式会尽量匹配更多的内容,用模型图来演示一下匹配逻辑
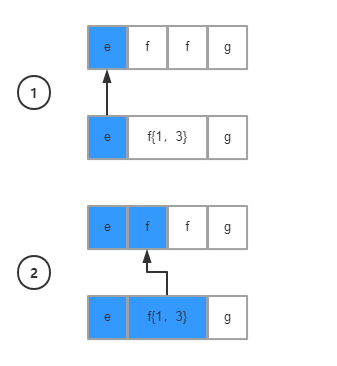
到第二步的时候其实已经满足第二个条件f{1,3},但贪婪模式会尽量匹配更多的内容,所以依然停在第二个条件继续遍历字符串
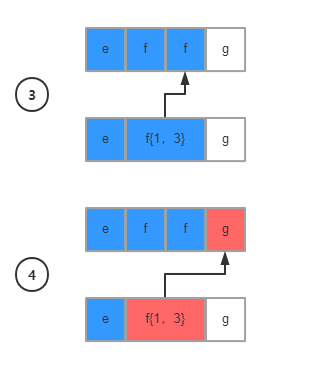
注意看第四步,字符g不满足匹配条件f{1,3},这个时候会触发回溯机制:指针重新回到第三个字符f处
关于回溯机制
回溯是造成正则表达式效率问题的根本原因,每次匹配失败,都需要将之前比对过的数据复位且指针调回到数据的上一位置,想要优化正则表达式的匹配效率,减少回溯是关键。
回溯之后,继续从下一个条件以及下一个字符继续匹配,直到结束
懒惰模式(Reluctant): ef{1,3}?g
字符后面加一个“?”,就可以开启懒惰模式。
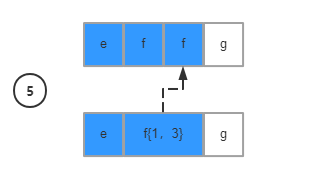
与贪婪模式相反,懒惰模式则会尽量匹配更少的内容:

到第二步的时候,懒惰模式会认为已经满足条件f{1,3},所以会直接判断下一条件

注意,到这步因为不满足匹配条件,所以触发回溯机制,将判断条件回调到上一个

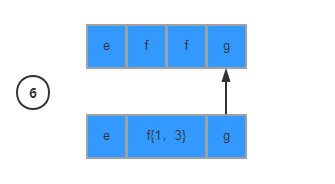
回溯之后,继续从下一个条件以及下一个字符继续匹配,直到结束

独占模式(Possessive): ef{1,3}+g
在字符后面加一个“+”,就可以开启独占模式。
独占模式应该算是贪婪模式的一种变种,它同样会尽量匹配更多的内容,区别在于在匹配失败的情况下不会触发回溯机制,而是继续向后判断,所以该模式效率最佳

在了解了三种匹配方式的匹配逻辑之后,给出第一个优化建议
优化建议
少用贪婪模式
多用贪婪模式会引起回溯问题,可以使用独占模式来避免回溯。
优化正则中的分支选择
通过上面对正则表达式匹配逻辑的了解,不难想到,由于回溯机制的存在,带有分支选择的正则表达式必然会降低匹配效率
String testStr = "abbdfg";
String regular = "(aab|aba|abb)dfg";在这个例子中,"aab"并未匹配,于是回溯到字符串的第一个元素重新匹配第二个分支"aba",以此类推,直到判断完所有分支,效率问题可想而知。
那么应该如何优化呢?这里给出特定情况下的两种优化建议:
考虑选择的顺序
将比较常用的选择项放在前面,使他们可以较快地被匹配;
分支中存在公共前缀可以提取公共部分
String regular = "a(ab|ba|bb)dfg";这样首先减少了公共前缀的判断次数,其次降低了分支造成的回溯频率,相比之下效率有所提升。
分支中的元素比较简单,可以使用indexOf方法匹配
testStr.indexOf("aab");
testStr.indexOf("aba");
testStr.indexOf("abb");注意:虽然上面的建议能够优化匹配效率,但只是相比之下的优化,分支选择的机制就决定了势必要进行多次的回溯判断,所以分支选择建议能不用就不用。
减少捕获嵌套
捕获组在正则表达式中通常用"()"表示,它将其中匹配到的内容保存到一个数组中,以便之后使用。
例如想获取前端input中的内容:
String inputStr = "<input id=\"userName\">userName</input>";定义带有捕获组的正则表达式,并输出捕获组存入数组中的内容
String regular = "(<input.*?>)(.*?)(</input>)";
Pattern pattern = Pattern.compile(regular);
Matcher matcher = pattern.matcher(inputStr);
while(matcher.find()){
System.out.println(matcher.group(0));
System.out.println(matcher.group(1));
System.out.println(matcher.group(2));
System.out.println(matcher.group(3));
}控制台输出:
<input id=\"userName\">userName</input>
<input id=\"userName\">
userName
</input>看到这里大家应该理解了捕获组的用法,第三行就是需要的内容,但需要优化的是,第二行以及第四行的内容并不需要,这会影响效率以及内存损耗。
对于这种情况可以使用"(?:)"来代替"()",区别在于前者不会将匹配的内容存入数组:
String regular = "(?:<input.*?>)(.*?)(?:</input>)";
Pattern pattern = Pattern.compile(regular);
Matcher matcher = pattern.matcher(inputStr);
while(matcher.find()){
System.out.println(matcher.group(0));
System.out.println(matcher.group(1));
}控制台输出:
<input id=\"userName\">userName</input>
userName也就是说:存在捕获组的正则表达式,如果信息不需要保存,则使用"(?😃"来替代"()"
总结
对于正则表达式存在的性能问题:
推荐在使用正则表达式的时候,采用懒惰模式和独占模式效率最佳,因为触发回溯的概率最小。
分支选择建议尽量避免使用,特定条件下可以采用提取公共前缀、indexOf方法优化
对于存在捕获组的正则表达式,如果信息不需要保存,则使用"(?😃"来替代"()"
