Java 8的新特性之一就是流stream,配合同版本出现的 Lambda ,使得操作集合(Collection)提供了极大的便利。
案例引入
在JAVA中,涉及到对数组、Collection等集合类中的元素进行操作的时候,通常会通过循环的方式进行逐个处理,或者使用Stream的方式进行处理。
假设遇到了这么一个需求:从给定句子中返回单词长度大于5的单词列表,按长度倒序输出,最多返回3个。
在未接触Stream流的时候,可能会这样写函数:
public List<String> sortGetTop3LongWords(@NotNull String sentence) {
// 先切割句子,获取具体的单词信息
String[] words = sentence.split(" ");
List<String> wordList = new ArrayList<>();
// 循环判断单词的长度,先过滤出符合长度要求的单词
for (String word : words) {
if (word.length() > 5) {
wordList.add(word);
}
}
// 对符合条件的列表按照长度进行排序
wordList.sort((o1, o2) -> o2.length() - o1.length());
// 判断list结果长度,如果大于3则截取前三个数据的子list返回
if (wordList.size() > 3) {
wordList = wordList.subList(0, 3);
}
return wordList;
}然而,如果用上了Stream流:
public List<String> sortGetTop3LongWordsByStream(@NotNull String sentence) {
return Arrays.stream(sentence.split(" "))
.filter(word -> word.length() > 5)
.sorted((o1, o2) -> o2.length() - o1.length())
.limit(3)
.collect(Collectors.toList());
}就是两个字:优雅
流的三大特点
流) (Stream) 到底是什么呢?是数据渠道,用于操作数据源(集合、数组等)所生成的元素序列。“ 集合讲的是数据 , 流讲的是 计 算 ! ”
- 流并不存储元素。这些元素存储在底层的集合中,或者是按需生成。
- 流的操作不会修改源数据元素,而是生成一个新的流。
- 流的操作是尽可能惰性执行的。这意味着直至需要其结果时,操作才会执行。
操作分类
官方将 Stream 中的操作分为两大类:
中间操作(Intermediate operations),只对操作进行了记录,即只会返回一个流,不会进行计算操作。终结操作(Terminal operations),实现了计算操作。
中间操作又可以分为:
无状态(Stateless)操作,元素的处理不受之前元素的影响。有状态(Stateful)操作,指该操作只有拿到所有元素之后才能继续下去。
终结操作又可以分为:
短路(Short-circuiting)操作,指遇到某些符合条件的元素就可以得到最终结果非短路(Unshort-circuiting)操作,指必须处理完所有元素才能得到最终结果。

如何使用
概括讲,可以将Stream流操作分为3种类型:
- 创建Stream
- Stream中间处理
- 终止Steam

每个Stream管道操作都包含若干方法,先列举一下各个API的方法:
开始管道
主要负责新建一个Stream流,或者基于现有的数组、List、Set、Map等集合类型对象创建出新的Stream流。

由数组创建流
Java8 中的 Arrays 的静态方法 stream() 可以获取数组流:
- static <T> Stream<T> stream(T[] array): 返回一个流
重载形式 , 能够处理对应基本类型的数组 :
public static IntStream stream(int[] array)
public static LongStream stream(long[] array)
public static DoubleStream stream(double[] array)
由值创建流
可以使用静态方法 Stream.of(),通过显示的值创建一个流。它可以接收任意数量的参数。
- public static<T> Stream<T> of(T... values) : 返回一个流
由函数创建流 : 创建无限流
可以使用静态方法 Stream.iterate() 和Stream.generate(),创建无限流。
迭代:public static<T> Stream<T> iterate(final T seed, final UnaryOperator<T> f)
生成:public static<T> Stream<T> generate(Supplier<T> s) :
中间管道
负责对Stream进行处理操作,并返回一个新的Stream对象,中间管道操作可以进行叠加。
| API | 功能说明 |
|---|---|
| filter() | 按照条件过滤符合要求的元素, 返回新的stream流。 |
| map() | 将已有元素转换为另一个对象类型,一对一逻辑,返回新的stream流。 |
| flatMap() | 将已有元素转换为另一个对象类型,一对多逻辑,即原来一个元素对象可能会转换为1个或者多个新类型的元素,返回新的stream流。 |
| limit() | 仅保留集合前面指定个数的元素,返回新的stream流。 |
| skip() | 跳过集合前面指定个数的元素,返回新的stream流。 |
| concat() | 将两个流的数据合并起来为1个新的流,返回新的stream流。 |
| distinct() | 对Stream中所有元素进行去重,返回新的stream流。 |
| sorted() | 对stream中所有的元素按照指定规则进行排序,返回新的stream流。 |
| peek() | 对stream流中的每个元素进行逐个遍历处理,返回处理后的stream流。 |
map与flatMap
在项目中,经常看到也经常使用到map与flatMap,比如代码:

map与flatMap都是用于转换已有的元素为其它元素,区别点在于:
- map 必须是一对一的,即每个元素都只能转换为1个新的元素;
- flatMap 可以是一对多的,即每个元素都可以转换为1个或者多个新的元素;
下面两张图形象地说明了两者之间的区别:
map图:

flatMap图:

map用例
有一个字符串ID列表,现在需要将其转为别的对象列表。
/**
* map的用途:一换一
*/
List<String> ids = Arrays.asList("205", "105", "308", "469", "627", "193", "111");
// 使用流操作
List<NormalOfferModel> results = ids.stream()
.map(id -> {
NormalOfferModel model = new NormalOfferModel();
model.setCate1LevelId(id);
return model;
})
.collect(Collectors.toList());
System.out.println(results);flatMap用例
现有一个句子列表,需要将句子中每个单词都提取出来得到一个所有单词列表:
List<String> sentences = Arrays.asList("hello world","Hello Price Info The First Version");
// 使用流操作
List<String> results2 = sentences.stream()
.flatMap(sentence -> Arrays.stream(sentence.split(" ")))
.collect(Collectors.toList());
System.out.println(results2);//[hello, world, Hello, Price, Info, The, First, Version]这里需要补充一句,flatMap操作的时候其实是先每个元素处理并返回一个新的Stream,然后将多个Stream展开合并为了一个完整的新的Stream,如下:
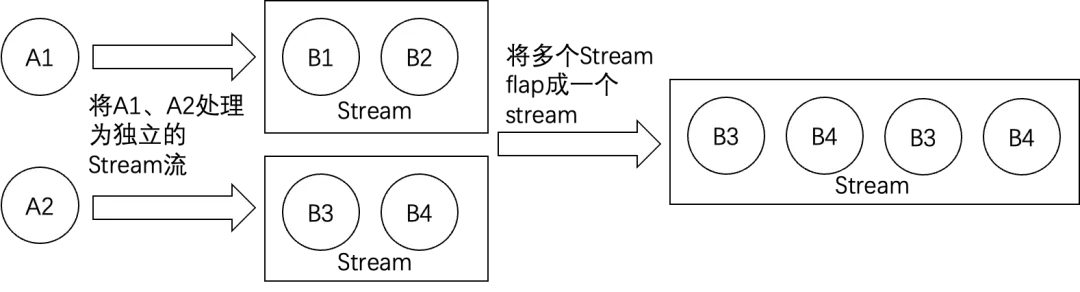
peek方法
peek可以用于对元素进行遍历然后逐个处理。
peek属于中间方法,这也就意味着peek只能作为管道中途的一个处理步骤,而没法直接执行得到结果,其后面必须还要有其它终止操作的时候才会被执行
filter、sorted、distinct、limit
这几个都是常用的Stream的中间操作方法,具体的方法的含义在上面的表格里面有说明。具体使用的时候,可以根据需要选择一个或者多个进行组合使用,或者同时使用多个相同方法的组合:
public void testGetTargetUsers() {
List<String> ids = Arrays.asList("205","10","308","49","627","193","111", "193");
// 使用流操作
List<OfferModel> results = ids.stream()
.filter(s -> s.length() > 2)//使用filter过滤掉不符合条件的数据
.distinct()//通过distinct对存量元素进行去重操作
.map(Integer::valueOf)//通过map操作将字符串转成整数类型
.sorted(Comparator.comparingInt(o -> o))//借助sorted指定按照数字大小正序排列
.limit(3)//使用limit截取排在前3位的元素
.map(id -> new OfferModel(id))//又一次使用map将id转为OfferModel对象类型
.collect(Collectors.toList());//使用collect终止操作将最终处理后的数据收集到list中
System.out.println(results);//[OfferModel{id=111}, OfferModel{id=193}, OfferModel{id=205}]
}终止管道
顾名思义,通过终止管道操作之后,Stream流将会结束,最后可能会执行某些逻辑处理,或者是按照要求返回某些执行后的结果数据。
| API | 功能说明 |
|---|---|
| count() | 返回stream处理后最终的元素个数。 |
| max() | 返回stream处理后的元素最大值。 |
| min() | 返回stream处理后的元素最小值。 |
| findFirst() | 找到第一个符合条件的元素时则终止流处理。 |
| findAny() | 找到任何一个符合条件的元素时则退出流处理,这个对于串行流时与findFirst相同,对于并行流时比较高效,任何分片中找到都会终止后续计算逻辑。 |
| anyMatch() | 返回一个boolean值,类似于isContains(),用于判断是否有符合条件的元素。 |
| allMatch() | 返回一个boolean值,用于判断是否所有元素都符合条件。 |
| noneMatch() | 返回一个boolean值, 用于判断是否所有元素都不符合条件。 |
| collect() | 将流转换为指定的类型,通过Collectors进行指定。 |
| toArray() | 将流转换为数组。 |
| iterator() | 将流转换为Iterator对象。 |
| foreach() | 无返回值,对元素进行逐个遍历,然后执行给定的处理逻辑。 |
foreach
foreach和peek一样,都可以用于对元素进行遍历然后逐个处理。但foreach属于终止方法,也就是说foreach可以直接执行相关操作。
collect
可以支持生成如下类型的结果数据:
一个集合类,比如List、Set或者HashMap等;
List<NormalOfferModel> normalOfferModelList = Arrays.asList(new NormalOfferModel("11"), new NormalOfferModel("22"), new NormalOfferModel("33")); // collect成list List<NormalOfferModel> collectList = normalOfferModelList .stream() .filter(offer -> offer.getCate1LevelId().equals("11")) .collect(Collectors.toList()); System.out.println("collectList:" + collectList); // collect成Set Set<NormalOfferModel> collectSet = normalOfferModelList .stream() .filter(offer -> offer.getCate1LevelId().equals("22")) .collect(Collectors.toSet()); System.out.println("collectSet:" + collectSet); // collect成HashMap,key为id,value为Dept对象 Map<String, NormalOfferModel> collectMap = normalOfferModelList .stream() .filter(offer -> offer.getCate1LevelId().equals("33")) .collect(Collectors.toMap(NormalOfferModel::getCate1LevelId, Function.identity(), (k1, k2) -> k2)); System.out.println("collectMap:" + collectMap);StringBuilder对象,支持将多个字符串进行拼接处理并输出拼接后结果;
public void testCollectJoinStrings() { List<String> ids = Arrays.asList("205", "10", "308", "49", "627", "193", "111", "193"); String joinResult = ids.stream().collect(Collectors.joining(",")); System.out.println("拼接后:" + joinResult); }一个可以记录个数或者计算总和的对象(数据批量运算统计);
public void testNumberCalculate() { List<Integer> ids = Arrays.asList(10, 20, 30, 40, 50); // 计算平均值 Double average = ids.stream().collect(Collectors.averagingInt(value -> value)); System.out.println("平均值:" + average); // 数据统计信息 IntSummaryStatistics summary = ids.stream().collect(Collectors.summarizingInt(value -> value)); System.out.println("数据统计信息:" + summary); }
对 Stream 流操作认知不完善导致的空指针异常
findFirst()方法需要可能会存在的空指针问题!
例如,如果第一个元素恰好为 null,findFirst() 将抛出 NullPointerException。这是因为 findFirst() 返回一个 Optional,而 Optional 不能包含空值。
Arrays.asList(null, 1, 2).stream().findFirst();//发生 NullPointerExceptionmax()、min() 和 reduce(),也表现出类似的行为。如果 null 是最终结果,则会抛出异常。
List<Integer> list = Arrays.asList(null, 1, 2);
var comparator = Comparator.<Integer>nullsLast(Comparator.naturalOrder());
System.out.println(list.stream().max(comparator));//发生 NullPointerException再例如:我们在使用 Stream 流式编程时,如果流包含 null,可以转换为 toList() 或 toSet();
然而,toMap() 要注意, 不允许空值(允许空Key):
Employee employee1 = new Employee("Jack", 10000);
Employee employee2 = new Employee(null, 10000);
//toMap的Value不能为空,此处异常
Map<Integer, String> salaryMap = Arrays.asList(employee1, employee2)
.stream()
.collect(Collectors.toMap(Employee::getSalary, Employee::getName));以及:groupingBy() 不允许空 Key:
Employee employee1 = new Employee("Jack", 10000);
Employee employee2 = new Employee(null, 10000);
//groupingBy的Key不能为空,此处抛异常
Map<String, List<Employee>> result = Stream.of(employee1, employee2)
.collect(Collectors.groupingBy(Employee::getName));可见在流中使用了空对象存在许多陷阱;所以,要重点关注 Stream 流的数据来源,避免在流中存在 null,不确定的话建议用 filter(Objects::nonNull) 将它们过滤掉。
并行Stream
parallelStream的机制说明
使用并行流,可以有效利用计算机的多CPU硬件,提升逻辑的执行速度。并行流通过将一整个stream划分为多个片段,然后对各个分片流并行执行处理逻辑,最后将各个分片流的执行结果汇总为一个整体流。

可以通过parallelStream的源码发现parallel Stream底层是将任务进行了切分,最终将任务传递给了jdk8自带的“全局”ForkJoinPool线程池。 在Fork-Join中,比如一个拥有4个线程的ForkJoinPool线程池,有一个任务队列,一个大的任务切分出的子任务会提交到线程池的任务队列中,4个线程从任务队列中获取任务执行,哪个线程执行的任务快,哪个线程执行的任务就多,只有队列中没有任务线程才是空闲的,这就是工作窃取。
可以通过下图更好的理解这种“分而治之”的思想:

约束与限制
parallelStream()中foreach()操作必须保证是线程安全的;
很多人在用惯了流式处理之后,很多for循环都会直接使用流式foreach(),实际上这样不一定是合理的,如果只是简单的for循环,确实没有必要使用流式处理,因为流式底层封装了很多流式处理的复杂逻辑,从性能上来讲不占优。parallelStream()中foreach()不要直接使用默认的线程池;
ForkJoinPool customerPool = new ForkJoinPool(n); customerPool.submit( () -> customerList.parallelStream().具体操作parallelStream()使用的时候尽量避免耗时操作;
注意
parallelStream和整个java进程共用ForkJoinPool:如果直接使用parallelStream().foreach会默认使用全局的ForkJoinPool,而这样就会导致当前程序很多地方共用同一个线程池,包括gc相关操作在内,所以一旦任务队列中满了之后,就会出现阻塞的情况,导致整个程序的只要当前使用ForkJoinPool的地方都会出现问题。
parallelStream使用后ThreadLocal数据为空:parallelStream创建的并行流在真正执行时是由ForkJoin框架创建多个线程并行执行,由于ThreadLocal本身不具有可继承性,新生成的线程自然无法获取父线程中的ThreadLocal数据。
流的运行流程
下面是一段比较简单常见的stream操作代码,经过映射与过滤操作后,最后得到的endList=["vb"],下文讲解都会以此代码为例。
List<String> startlist = Lists.newArrayList("s", "e", "v", "e", "n");
List<String> endList = startlist.stream().map(r -> r + "b").filter(r -> r.startsWith("v")).collect(Collectors.toList());一段Stream代码的运行包括以下三部分:
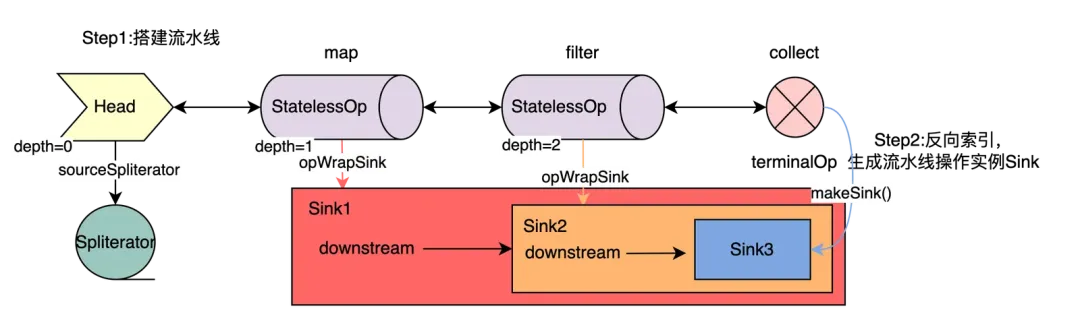
- 搭建流水线,定义各阶段功能。即创建stream
- 从终结点反向索引,生成操作实例Sink。
- 数据源送入流水线,经过各阶段处理后,生成结果。
类图介绍
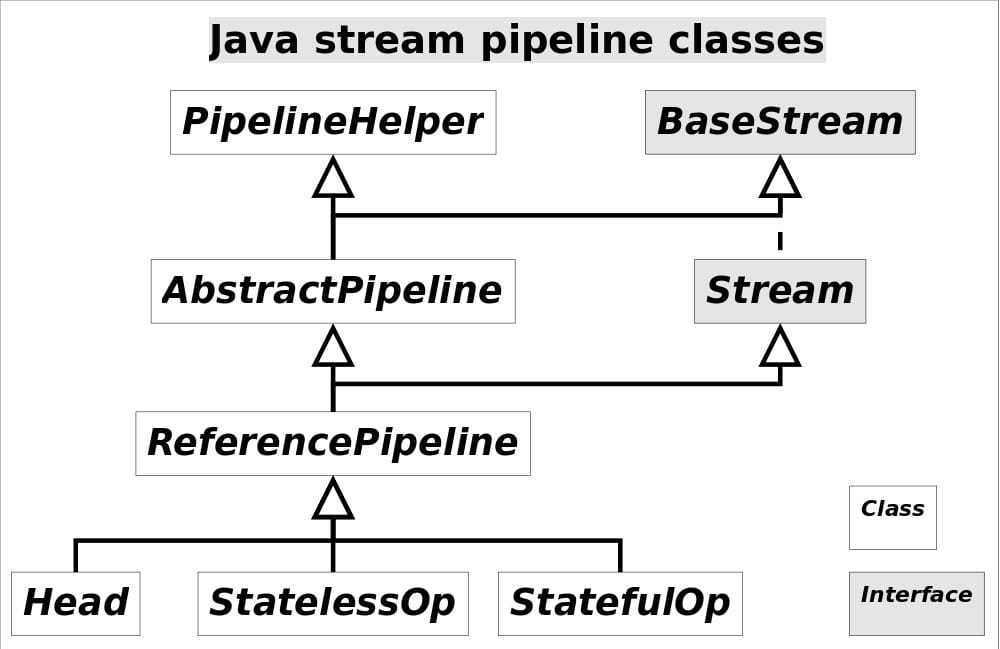
Stream是一个接口,它定义了对Stream的操作,它继承自BaseStream,BaseStream是最顶端的接口类,定义了流的基本接口方法,最主要的方法为 spliterator、isParallel。
Stream主要可分为中间操作与终结操作,中间操作对流进行转化,定义了 映射(map)、过滤(filter)、排序(sorted)等行为。终结操作启动流水线,获取结果数据(collect)。
AbstractPipline是一个抽象类,定义了流水线节点的常用属性:
- sourceStage:指向流水线首节点
- previousStage :指向本节点上层节点
- nextStage :指向本节点下层节点
- depth:代表本节点处于流水线第几层(从0开始计数)
- sourceSpliterator:指向数据源
ReferencePipline 实现Stream接口,继承AbstractPipline类,它主要对Stream中的各个操作进行实现。此外,它还定义了Head、StatelessOp、StatefulOp三个内部类。
- Head为流水线首节点,在集合转为流后,生成Head节点。
- StatelessOp为无状态操作:无状态操作只对当前元素进行作用,比如filter操作只需判断“v”元素符不符合“startWith("v")”这个要求,无需在对“v”进行判断时关注数据源其他元素(“s”,“e”,“n”)的状态
- StatefulOp为有状态操作:有状态操作需要关注数据源中其他元素的状态,比如sorted操作要保留数据源其他元素,然后进行排序,生成新流。
Sink 接口定义了 Stream 之间的操作行为,包含 begin()、end()、cancellationRequested()、accpt()四个方法。ReferencePipeline最终会将整个 Stream 流操作组装成一个调用链,而这条调用链上的各个 Stream 操作的上下关系就是通过 Sink 接口协议来定义实现的。
搭建流水线
首先需要区分一个概念,Stream(流)并不是一个容器,不存储数据,它更像是一个个具有不同功能的流水线节点,可相互串联,容许数据源挨个通过,最后随着终结操作生成结果。Stream流水线搭建包括三个阶段:
- 创建一个流,如通过stream()产生Head,Head就是初始流,数据存储在Spliterator。
- 将初始流转换成其他流的中间操作,可能包含多个步骤,比如上面map与filter操作。
- 终止操作,用于产生结果,终结操作后,流也就走到了终点。
定义输入源HEAD
只有实现了Collection接口的类才能创建流,所以Map并不能创建流,List与Set这种单列集合才可创建流。上述代码使用stream()方法创建流,也可使用Stream.of()创建任何数量引元的流,或是 Array.stream(array,from,to) 从数组中from到to的位置创建输入源。
stream()运行结果
示例代码中使用stream()方法生成流,看看生成的流中有哪些内容:
Stream<String> headStream = startlist.stream();
从运行结果来看,stream()方法生成了ReferencPipeline$Head类,ReferencPipeline是Stream的实现类,Head是ReferencePipline的内部类。其中:
- sourceStage指向实例本身
- depth=0代表Head是流水线首层
- sourceSpliterator 指向底层存储数据的集合,其中list即初始数据源。
stream()源码分析
// java.util.Collection#stream
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
// java.util.Collection#spliterator
@Override
default Spliterator<E> spliterator() {
return Spliterators.spliterator(this, 0);
}spliterator()将 “调用stream()方法的对象本身startlist” 传入构造函数,生成Spliterator类,传入StreamSupport.stream()方法。
// java.util.stream.StreamSupport#stream(java.util.Spliterator<T>, boolean)
public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {
Objects.requireNonNull(spliterator);
return new ReferencePipeline.Head<>(spliterator,
StreamOpFlag.fromCharacteristics(spliterator),
parallel);
}StreamSupport.stream()返回了ReferencPipeline$Head类。
点击构造函数,一路追溯至 AbstractPipline 中,可看到使用sourceSpliterator指向数据源,sourceStage为Head实例本身,深度depth=0。
// java.util.stream.AbstractPipeline#AbstractPipeline(java.util.Spliterator<?>, int, boolean)
AbstractPipeline(Spliterator<?> source, int sourceFlags, boolean parallel) {
this.previousStage = null;
this.sourceSpliterator = source;//指向传入的spliterator,也就是调用stream()方法的list,即数据源
this.sourceStage = this; //Head实例本身
this.sourceOrOpFlags = sourceFlags & StreamOpFlag.STREAM_MASK;
// The following is an optimization of:
// StreamOpFlag.combineOpFlags(sourceOrOpFlags, StreamOpFlag.INITIAL_OPS_VALUE);
this.combinedFlags = (~(sourceOrOpFlags << 1)) & StreamOpFlag.INITIAL_OPS_VALUE;
this.depth = 0;//深度为0
this.parallel = parallel;
}定义流水线中间节点
Map
map()运行结果
对数据进行映射,对每个元素后接"b"。
Stream<String> mapStream =startlist.stream().map(r->r+"b");
此时:(由于是多次dubug,因此对象的地址值与上面不一致,但不影响案例分析,下同)
- sourceStage与previousStage 皆指向Head节点
- depth变为1,表示为流水线第二节点
- 由于代码后续没接其他操作,所以nextStage为null
- mapper代表函数式接口,指向lambda代码块,即 “r->r+"b"” 这个操作。
map()源码分析
//java.util.stream.ReferencePipeline#map
@Override
@SuppressWarnings("unchecked")
public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper) {
Objects.requireNonNull(mapper);
return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<R> sink) {
return new Sink.ChainedReference<P_OUT, R>(sink) {
@Override
public void accept(P_OUT u) {
downstream.accept(mapper.apply(u));
}
};
}
};
}可以看到,map()方法是在ReferencePipline中被实现的,返回了一个无状态操作StatelessOp,定义opWrapSink方法,运行时会将lambda代码块的内容替换apply方法,对数据元素u进行操作。opWrapSink方法将返回Sink对象,其用处将在下文讲解。downstream为opWrapSink的入参sink。
Filter
filter()运行结果
filter对元素进行过滤,只留存以“v”开头的数据元素。
Stream<String> filterStream = startlist.stream().map(r -> r + "b").filter(r -> r.startsWith("v"));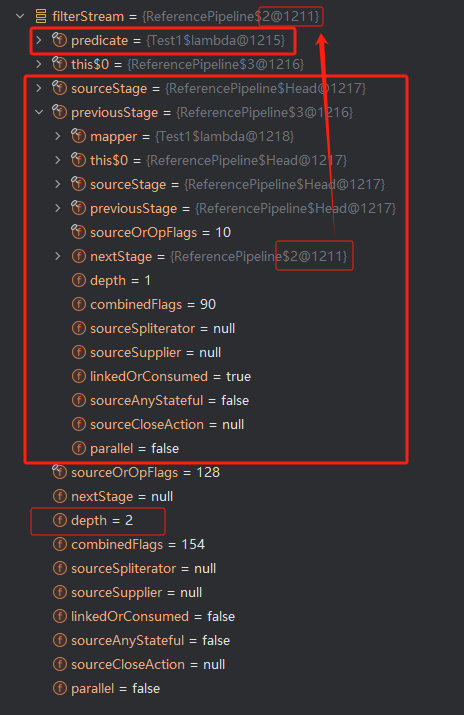
Filter阶段:
- depth再次+1,变为2
- sourceStage指向Head
- predict指向lamda表达式的代码块:“r->r.startsWith("a")”
- previousStage指向前序Map节点
- Map节点中的nextStage 开始指向Filter,形成了双向链表。
filter()源码分析
// java.util.stream.ReferencePipeline#filter
@Override
public final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) {
Objects.requireNonNull(predicate);
return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SIZED) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {
return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {
@Override
public void begin(long size) {
downstream.begin(-1);
}
@Override
public void accept(P_OUT u) {
if (predicate.test(u)) // "r->r.startsWith("v")"
downstream.accept(u);
}
};
}
};
}filter()也是在ReferencePipline中被实现,返回一个无状态操作StatelessOp,实现opWrapSink方法,也是返回一个Sink,其中accept方法中的predicate.test="r->r.startsWith("v")",用以过滤符合要求的元素。downstream等于opWrapSink入参Sink。
new StatelessOp 最终会调用父类 AbstractPipeline 的构造函数,这个构造函数将前后的 Stage 联系起来,生成一个 Stage 双向链表:
// java.util.stream.AbstractPipeline#AbstractPipeline(java.util.stream.AbstractPipeline<?,E_IN,?>, int)
AbstractPipeline(AbstractPipeline <? , E_IN, ?> previousStage, int opFlags) {
if (previousStage.linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
previousStage.linkedOrConsumed = true;
previousStage.nextStage = this;
this.previousStage = previousStage;
this.sourceOrOpFlags = opFlags & StreamOpFlag.OP_MASK;
this.combinedFlags = StreamOpFlag.combineOpFlags(opFlags, previousStage.combinedFlags);
this.sourceStage = previousStage.sourceStage;
if (opIsStateful())
sourceStage.sourceAnyStateful = true;
this.depth = previousStage.depth + 1;
}定义终结操作
collect()运行结果

经过终结操作后,生成最终结果[“vb”]。
collect()源码分析
// java.util.stream.ReferencePipeline#collect(java.util.stream.Collector<? super P_OUT,A,R>)
@Override
@SuppressWarnings("unchecked")
public final < R, A > R collect(Collector <? super P_OUT, A, R > collector) {
A container;
if (isParallel() //是并行操作
&& (collector.characteristics().contains(Collector.Characteristics.CONCURRENT))
&& (!isOrdered() || collector.characteristics().contains(Collector.Characteristics.UNORDERED))) {
container = collector.supplier().get();
BiConsumer < A, ? super P_OUT > accumulator = collector.accumulator();
forEach(u - > accumulator.accept(container, u));
}
else { // 不是并行操作
container = evaluate(ReduceOps.makeRef(collector));
}
return collector.characteristics().contains(Collector.Characteristics.IDENTITY_FINISH)
? (R) container
: collector.finisher().apply(container);
}同样的,collect终结操作也在ReferencePipline中被实现。由于不是并行操作,只要关注evaluate()方法即可,而evaluate()方法中有一个makeRef()方法
// java.util.stream.ReduceOps#makeRef(java.util.stream.Collector<? super T,I,?>)
public static < T, I > TerminalOp < T, I > makeRef(Collector <? super T, I, ?> collector) {
Supplier < I > supplier = Objects.requireNonNull(collector).supplier();
BiConsumer < I, ? super T > accumulator = collector.accumulator();
BinaryOperator < I > combiner = collector.combiner();
class ReducingSink extends Box < I > implements AccumulatingSink < T, I, ReducingSink > {
@Override
public void begin(long size) {
state = supplier.get();
}
@Override
public void accept(T t) {
accumulator.accept(state, t);
}
@Override
public void combine(ReducingSink other) {
state = combiner.apply(state, other.state);
}
}
return new ReduceOp < T, I, ReducingSink > (StreamShape.REFERENCE) {
@Override
public ReducingSink makeSink() {
return new ReducingSink();//new一个ReducingSInk对象
}
@Override
public int getOpFlags() {
return collector.characteristics().contains(Collector.Characteristics.UNORDERED) ? StreamOpFlag.NOT_ORDERED : 0;
}
};
}makeRef()方法中也有个类似opWrapSink一样返回Sink的方法,不过没有以其他Sink为输入,而是直接new一个ReducingSInk对象。
至此,可以根据源码绘出下图,使用双向链表连接各个流水线节点,并将每个阶段的lambda代码块存入Sink类中。数据源使用sourceSpliterator引用。
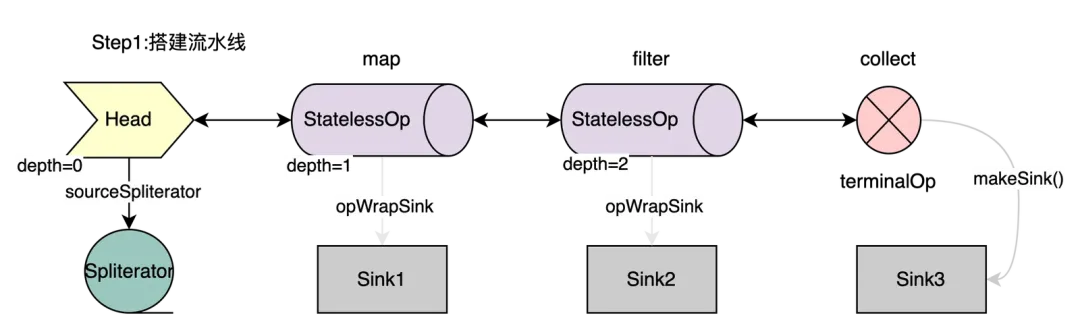
反向回溯生成操作实例
Stream是“惰性执行”的,在一层一层搭建中间节点时,并未有任何结果产生,而在终结操作collect之后,才会生成最终结果endList,接下来具体探究一下collect()方法中的evaluate方法。
// java.util.stream.AbstractPipeline#evaluate(java.util.stream.TerminalOp<E_OUT,R>)
final < R > R evaluate(TerminalOp < E_OUT, R > terminalOp) {
assert getOutputShape() == terminalOp.inputShape();
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
}这里调用了Collect中定义的makeSink()方法,输入终结节点生成的sink与数据源spliterator。
// java.util.stream.ReduceOps.ReduceOp#evaluateSequential
@Override
public < P_IN > R evaluateSequential(PipelineHelper < T > helper,
Spliterator < P_IN > spliterator) {
return helper.wrapAndCopyInto(makeSink(), spliterator).get();
}
// java.util.stream.AbstractPipeline#wrapAndCopyInto
@Override
final < P_IN, S extends Sink < E_OUT >> S wrapAndCopyInto(S sink, Spliterator < P_IN > spliterator) {
copyInto(wrapSink(Objects.requireNonNull(sink)), spliterator);
return sink;
}先来看wrapSink方法,在这个方法里,中间节点的opWrapSink方法利用previousStage反向索引,后一个节点的sink送入前序节点的opWrapSink方法中做入参,也就是downstream,生成当前sink,再索引向前,生成套娃Sink。
// java.util.stream.AbstractPipeline#wrapSink
final < P_IN > Sink < P_IN > wrapSink(Sink < E_OUT > sink) {
Objects.requireNonNull(sink);
for (@SuppressWarnings("rawtypes") AbstractPipeline p = AbstractPipeline.this; p.depth > 0; p = p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink < P_IN > ) sink;
}最后索引到 depth=1 的Map节点,生成的结果Sink包含了depth2节点Filter与终结节点Collect的Sink。

红色框图表示Map节点的Sink,包含当前Stream与downstream(Filter节点Sink),黄色代表Filter节点Sink,downstream指向Collect节点。
Sink被反向套娃实例化,一步步索引到Map节点。
启动流水线
一切准备就绪后,就是把数据源冲入流水线,在wrapSink方法套娃生成Sink之后,copyInto方法将数据源送入了流水线。
// java.util.stream.AbstractPipeline#wrapAndCopyInto
@Override
final < P_IN, S extends Sink < E_OUT >> S wrapAndCopyInto(S sink, Spliterator < P_IN > spliterator) {
copyInto(wrapSink(Objects.requireNonNull(sink)), spliterator);
return sink;
}
@Override
final < P_IN > void copyInto(Sink < P_IN > wrappedSink, Spliterator < P_IN > spliterator) {
Objects.requireNonNull(wrappedSink);
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
wrappedSink.begin(spliterator.getExactSizeIfKnown());
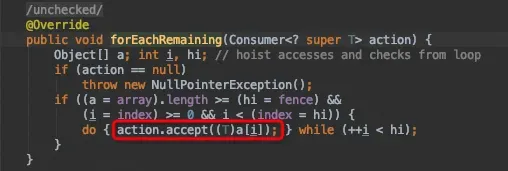
spliterator.forEachRemaining(wrappedSink);
wrappedSink.end();
} else {
copyIntoWithCancel(wrappedSink, spliterator);
}
}先是调用Sink中已定义好的begin方法,做些前序处理,Sink中的begin方法会不断调用下一个Sink的begin方法。
随后对数据源中各个元素进行遍历,调用Sink中定义好的accept方法处理数据元素。accept执行的就是咱在每一节点定义的lambda代码块。
随后调用end方法做后序扫尾工作。
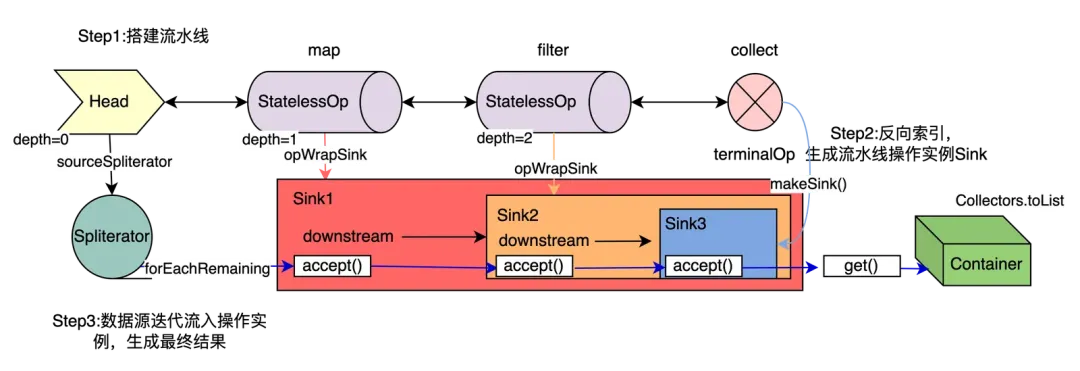
一个简单Stream整体关联图如上所示,最后调用get()方法生成结果。
