21是继Java17之后,最新的LTS版本,于2023年9月发布
正式特性
虚拟线程
该版本中虚拟线程成为了正式版,Java 19中是预览版
虚拟线程的实际应用
public class VirtualThreadWebServer {
public static void main(String[] args) throws IOException {
// 创建虚拟线程执行器
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
ServerSocket serverSocket = new ServerSocket(8080);
System.out.println("服务器启动在端口 8080");
while (true) {
Socket clientSocket = serverSocket.accept();
// 为每个客户端连接创建虚拟线程
executor.submit(() -> handleClient(clientSocket));
}
}
}
private static void handleClient(Socket clientSocket) {
try (BufferedReader in = new BufferedReader(new InputStreamReader(clientSocket.getInputStream()));
PrintWriter out = new PrintWriter(clientSocket.getOutputStream(), true)) {
String inputLine;
while ((inputLine = in.readLine()) != null) {
// 模拟处理请求(可能涉及数据库查询等 I/O 操作)
Thread.sleep(100); // 虚拟线程会自动让出
out.println("Echo: " + inputLine);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}虚拟线程与传统线程池的对比
public class ThreadComparisonExample {
public static void main(String[] args) throws InterruptedException {
int taskCount = 100000;
// 传统线程池方式
long start = System.currentTimeMillis();
try (ExecutorService executor = Executors.newFixedThreadPool(200)) {
CountDownLatch latch = new CountDownLatch(taskCount);
for (int i = 0; i < taskCount; i++) {
executor.submit(() -> {
try {
// 模拟 I/O 操作
Thread.sleep(10);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {
latch.countDown();
}
});
}
latch.await();
}
System.out.println("传统线程池耗时: " + (System.currentTimeMillis() - start) + "ms");
// 虚拟线程方式
start = System.currentTimeMillis();
try (ExecutorService executor = Executors.newVirtualThreadPerTaskExecutor()) {
CountDownLatch latch = new CountDownLatch(taskCount);
for (int i = 0; i < taskCount; i++) {
executor.submit(() -> {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {
latch.countDown();
}
});
}
latch.await();
}
System.out.println("虚拟线程耗时: " + (System.currentTimeMillis() - start) + "ms");
}
}switch格式匹配
Java 14 版本推出了 Switch 表达式,能够一行处理多个条件;Java 21 版本进一步优化了 Switch 的能力,新增了模式匹配特性,能够更轻松地根据对象的类型做不同的处理。
之前的写法
public class Test{
public static void main(String[] args) {
Integer i = 10;
String str = getObjInstance(i);
System.out.println(str);
}
public static String getObjInstance(Object obj) {
String objInstance = "";
if(obj == null){
objInstance = "空对象"
} else if (obj instanceof Integer i) {
objInstance = "Integer 对象:" + i;
} else if (obj instanceof Double d) {
objInstance = "Double 对象:" + d;
} else if (obj instanceof String s) {
objInstance = "String 对象:" + s;
}
return objInstance;
}
}新的写法,代码更加简洁
public class Test{
public static void main(String[] args) {
Integer i = 10;
String str = getObjInstance(i);
System.out.println(str);
}
public static String getObjInstance(Object obj) {
return switch(obj){
case null -> "空对象";
case Integer i -> "Integer 对象:" + i;
case Double d -> "Double对象:" + d;
case String s -> "String对象:" + s;
default -> obj.toString();
};
}
}可以在switch中使用when
public class Test{
public static void main(String[] args) {
yesOrNo("yes");
}
public static void yesOrNo(String obj) {
switch(obj){
case null -> {System.out.println("空对象");}
case String s
when s.equalsIgnoreCase("yes") -> {
System.out.println("确定");
}
case String s
when s.equalsIgnoreCase("no") -> {
System.out.println("取消");
}
//最后的case要写,否则编译回报错
case String s -> {
System.out.println("请输入yes或no");
}
};
}
}模式匹配的高级用法
public class AdvancedPatternMatching {
// 定义一些数据类型
public sealed interface Expression permits Constant, BinaryOp {}
public record Constant(int value) implements Expression {}
public record BinaryOp(String operator, Expression left, Expression right) implements Expression {}
// 使用模式匹配计算表达式
public int evaluate(Expression expr) {
return switch (expr) {
case Constant(var value) -> value;
case BinaryOp("+", var left, var right) -> evaluate(left) + evaluate(right);
case BinaryOp("-", var left, var right) -> evaluate(left) - evaluate(right);
case BinaryOp("*", var left, var right) -> evaluate(left) * evaluate(right);
case BinaryOp("/", var left, var right) -> evaluate(left) / evaluate(right);
case BinaryOp(var op, var left, var right) ->
throw new UnsupportedOperationException("不支持的操作符: " + op);
};
}
// 处理复杂的数据结构
public String processData(Object data) {
return switch (data) {
case null -> "空数据";
case String s when s.isEmpty() -> "空字符串";
case String s when s.length() == 1 -> "单字符: " + s;
case String s -> "字符串: " + s;
case Integer i when i == 0 -> "零";
case Integer i when i > 0 -> "正整数: " + i;
case Integer i -> "负整数: " + i;
case List<?> list when list.isEmpty() -> "空列表";
case List<?> list when list.size() == 1 -> "单元素列表: " + list.get(0);
case List<?> list -> "列表,大小: " + list.size();
default -> "未知类型";
};
}
}record pattern
Java14引入的新特性。通过该特性可以解构record类型中的值,例如
public class Test{
public static void main(String[] args) {
Student s = new Student(10, "jordan");
printSum(s);
}
static void printSum(Object obj) {
//这里的Student(int a, String b)就是 record pattern
if (obj instanceof Student(int a, String b)) {
System.out.println("id:" + a);
System.out.println("name:" + b);
}
}
}
record Student(int id, String name) {}或者
public record Person(String name, int age) {}
public record Address(String city, String street) {}
public record Employee(Person person, Address address, double salary) {}
//使用 Record 模式可以直接解构这些数据,不用一层一层取了
public String analyzeEmployee(Employee emp) {
return switch (emp) {
// 一次性提取所有需要的信息
case Employee(Person(var name, var age), Address(var city, var street), var salary)
when salary > 50000 ->
String.format("%s(%d岁)是高薪员工,住在%s%s,月薪%.0f",
name, age, city, street, salary);
case Employee(Person(var name, var age), var address, var salary) ->
String.format("%s(%d岁)月薪%.0f,住在%s",
name, age, salary, address.city());
};
}这种写法适合追求极致简洁代码的程序员,可以在一行代码中同时完成 类型检查、数据提取 和 条件判断。
Record 模式的实际应用
public class RecordPatternExample {
// 定义 HTTP 响应的数据结构
public sealed interface HttpResponse permits Success, Error, Redirect {}
public record Success(int code, String body, Map<String, String> headers) implements HttpResponse {}
public record Error(int code, String message) implements HttpResponse {}
public record Redirect(int code, String location) implements HttpResponse {}
// 处理 HTTP 响应
public void handleResponse(HttpResponse response) {
switch (response) {
case Success(var code, var body, var headers) when code == 200 -> {
System.out.println("成功响应: " + body);
if (headers.containsKey("Content-Type")) {
System.out.println("内容类型: " + headers.get("Content-Type"));
}
}
case Success(var code, var body, var headers) -> {
System.out.println("成功响应 " + code + ": " + body);
}
case Error(var code, var message) when code >= 500 -> {
System.err.println("服务器错误 " + code + ": " + message);
}
case Error(var code, var message) -> {
System.err.println("客户端错误 " + code + ": " + message);
}
case Redirect(var code, var location) -> {
System.out.println("重定向 " + code + " -> " + location);
}
}
}
// 解析嵌套的数据结构
public void processOrder(Object order) {
record Item(String name, double price, int quantity) {}
record Customer(String name, String email) {}
record Order(Customer customer, List<Item> items, double total) {}
switch (order) {
case Order(Customer(var customerName, var email), var items, var total)
when total > 1000 -> {
System.out.println("大订单:客户 " + customerName + " (" + email + ")");
System.out.println("订单总额:" + total);
items.forEach(item -> System.out.println("- " + item.name() + " x" + item.quantity()));
}
case Order(Customer(var customerName, var email), var items, var total) -> {
System.out.println("普通订单:客户 " + customerName);
System.out.println("商品数量:" + items.size() + ",总额:" + total);
}
default -> System.out.println("无效订单");
}
}
}有序集合
在Java.util包下新增了3个接口
- SequencedCollection
- SequencedSet
- SequencedMap
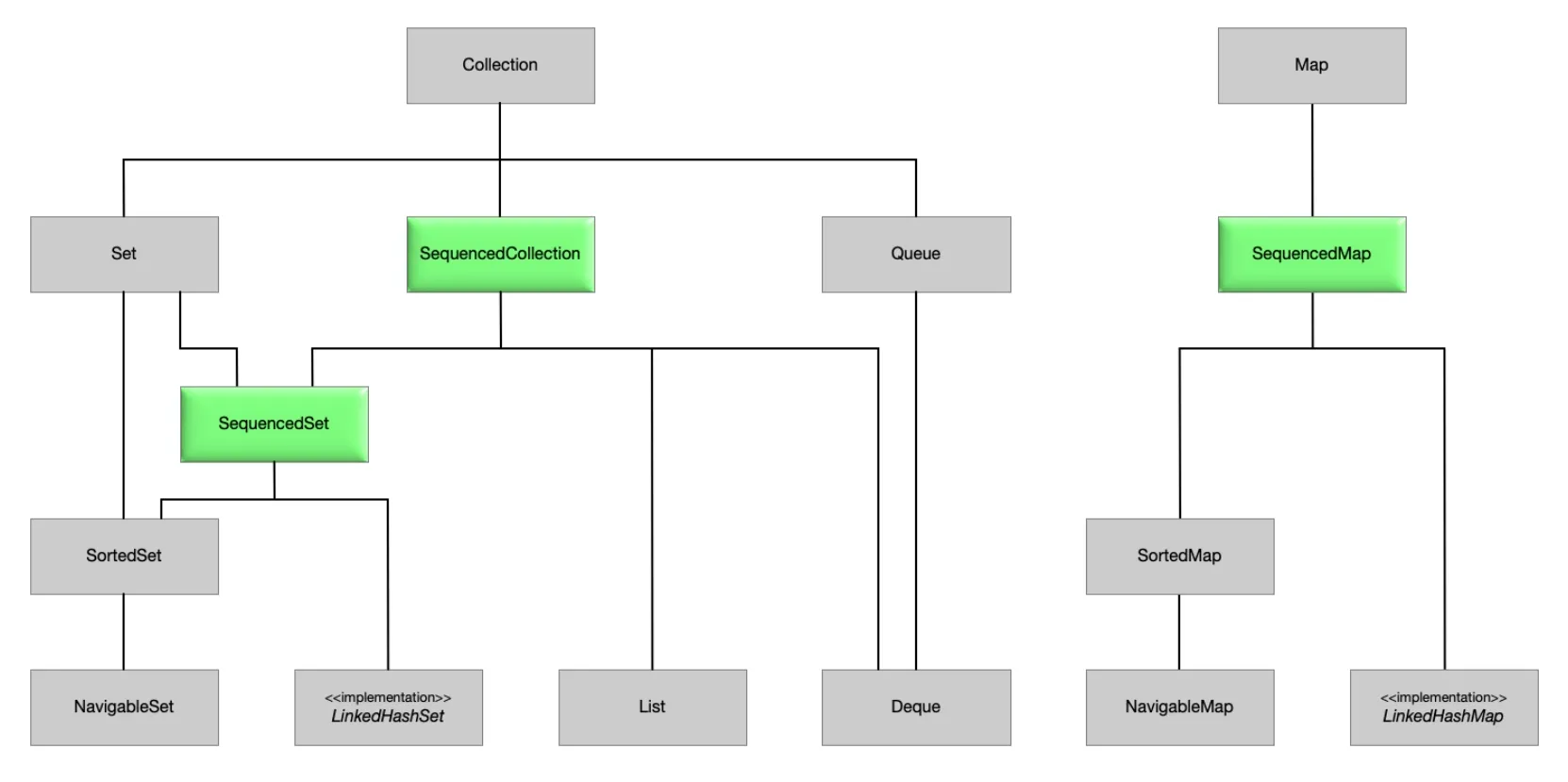
为我们提供了更直观的方式来操作集合的头尾元素,说白了就是补了几个方法
List<String> tasks = new ArrayList<>();
tasks.addFirst("Seve的任务"); // 添加到开头
tasks.addLast("小阿巴的任务"); // 添加到结尾
String firstStr = tasks.getFirst(); // 获取第一个
String lastStr = tasks.getLast(); // 获取最后一个
String removedFirst = tasks.removeFirst(); // 删除并返回第一个
String removedLast = tasks.removeLast(); // 删除并返回最后一个
List<String> reversed = tasks.reversed(); // 反转列表除了 List 之外,SequencedMap 接囗(比如 LinkedHashMap) 和 SequencedSet 接口(比如 LinkedHashset)也新增了类似的方法。本质上都是实现了有序集合接口
示例:
public class SequencedCollectionExample {
public static void main(String[] args) {
// List 的有序操作
List<String> list = new ArrayList<>();
list.addFirst("开始");
list.addLast("结束");
list.addFirst("真正的开始");
System.out.println("列表: " + list); // [真正的开始, 开始, 结束]
System.out.println("第一个: " + list.getFirst());
System.out.println("最后一个: " + list.getLast());
// Set 的有序操作
SequencedSet<Integer> set = new LinkedHashSet<>();
set.addFirst(1);
set.addLast(3);
set.addFirst(0);
set.addLast(4);
System.out.println("有序集合: " + set); // [0, 1, 3, 4]
System.out.println("反转后: " + set.reversed()); // [4, 3, 1, 0]
// Map 的有序操作
SequencedMap<String, String> map = new LinkedHashMap<>();
map.putFirst("first", "第一个");
map.putLast("last", "最后一个");
map.putFirst("zero", "第零个");
System.out.println("有序映射: " + map);
System.out.println("第一个键值对: " + map.firstEntry());
System.out.println("最后一个键值对: " + map.lastEntry());
}
}分代 ZGC
Java 21 中的分代 ZGC 可以说是垃圾收集器领域的一个重大突破。ZGC 从 Java 11 开始就以其超低延迟而闻名,但是它并没有采用分代的设计思路
在这之前,ZGC对所有对象一视同仁,无论是刚创建的新对象还是存活了很久的老对象,都使用同样的收集策略。这虽然保证了一致的低延迟,但在内存分配密集的应用中,效率并不是最优的。
分代 ZGC 的核心思想是基于一个现象 —— 大部分对象都是"朝生夕死"的。它将堆内存划分为年轻代和老年代两个区域,年轻代的垃圾收集可以更加频繁和高效,因为大部分年轻对象很快就会死亡,收集器可以快速清理掉这些垃圾;而老年代的收集频率相对较低,减少了对长期存活对象的不必要扫描。

使用
# 启用分代 ZGC
java -XX:+UseZGC -XX:+UnlockExperimentalVMOptions -XX:+UseGenerationalZGC MyApp
# 监控 GC 性能
java -XX:+UseZGC -XX:+UnlockExperimentalVMOptions -XX:+UseGenerationalZGC \
-Xlog:gc:gc.log MyApp
# 调整年轻代大小(可选)
java -XX:+UseZGC -XX:+UnlockExperimentalVMOptions -XX:+UseGenerationalZGC \
-XX:NewRatio=2 MyApp分代 ZGC 的优势
- 更低的分配开销:年轻代分配更高效
- 更少的 GC 工作:大部分对象在年轻代就被回收
- 更好的缓存局部性:年轻对象聚集在一起
- 保持低延迟:继承了 ZGC的低延迟特性
弃用 Windows 32 位 x86 端囗
Java 21 将 Windows 32 位支持标记为弃用
# 32 位 Windows 系统将不再被官方支持
# 建议迁移到 64 位系统准备禁止代理的动态加载
Java 21 为禁止运行时动态加载 Java 代理做准备
# 未来版本将不允许运行时加载代理
# java -javaagent:agent.jar MyApp # 启动时加载仍然支持
# 如果需要运行时加载(不推荐)
java -XX:+EnableDynamicAgentLoading MyApp密钥封装机制 API
Java 21 引入了密钥封装机制(KEM)API
import javax.crypto.KEM;
import javax.crypto.KeyGenerator;
import java.security.KeyPair;
import java.security.KeyPairGenerator;
public class KEMExample {
public static void main(String[] args) throws Exception {
// 生成密钥对
KeyPairGenerator kpg = KeyPairGenerator.getInstance("RSA");
kpg.initialize(2048);
KeyPair keyPair = kpg.generateKeyPair();
// 创建 KEM 实例
KEM kem = KEM.getInstance("RSA-KEM");
// 发送方:封装密钥
KEM.Encapsulator encapsulator = kem.newEncapsulator(keyPair.getPublic());
KEM.Encapsulated encapsulated = encapsulator.encapsulate();
byte[] encapsulatedKey = encapsulated.encapsulation();
byte[] sharedSecret = encapsulated.key();
// 接收方:解封装密钥
KEM.Decapsulator decapsulator = kem.newDecapsulator(keyPair.getPrivate());
byte[] recoveredSecret = decapsulator.decapsulate(encapsulatedKey);
// 验证密钥一致性
System.out.println("密钥封装成功: " +
java.util.Arrays.equals(sharedSecret, recoveredSecret));
}
}预览特性
字符串模板
字符串模板可以让开发者更简洁的进行字符串拼接(例如拼接sql,xml,json等)。该特性并不是为字符串拼接运算符+提供的语法糖,也并非为了替换SpringBuffer和StringBuilder。
利用STR模板进行字符串与变量的拼接:
String sport = "basketball";
String msg = STR."i like \{sport}";
System.out.println(msg);//i like basketball这个特性目前是预览版,编译和运行需要添加额外的参数:
Javac --enable-preview -source 21 Test.Java
Java --enable-preview Test在js中字符串进行拼接时会采用下面的字符串插值写法
let sport = "basketball"
let msg = `i like ${sport}`看起来字符串插值写法更简洁移动,不过若在Java中使用这种字符串插值的写法拼接sql,可能会出现sql注入的问题,为了防止该问题,Java提供了字符串模板表达式的方式。
上面使用的STR是Java中定义的模板处理器,它可以将变量的值取出,完成字符串的拼接。在每个Java源文件中都引入了一个public static final修饰的STR属性,因此我们可以直接使用STR,STR通过打印STR可以知道它是Java.lang.StringTemplate,是一个接口。
在StringTemplate中是通过调用interpolate方法来执行的,该方法分别传入了两个参数:
fragements:包含字符串模板中所有的字面量,是一个List
values:包含字符串模板中所有的变量,是一个List
而该方法又调用了JavaTemplateAccess中的interpolate方法,经过分析可以得知,它最终是通过String中的join方法将字面量和变量进行的拼接
其他使用示例,在STR中可以进行基本的运算(支持三元运算)
int x = 10, y = 20;
String result = STR."\{x} + \{y} = \{x + y}";
System.out.println(result);//10 + 20 = 30调用方法:
String result = STR."获取一个随机数: \{Math.random()}";
System.out.println(result);获取属性:
String result = STR."int最大值是: \{Integer.MAX_VALUE}";
System.out.println(result);查看时间:
String result = STR."现在时间: \{new SimpleDateFormat("yyyy-MM-dd").format(new Date())}";
System.out.println(result);计数操作:
int index = 0;
String result = STR."\{index++},\{index++},\{index++}";
System.out.println(result);获取数组数据:
String[] cars = {"bmw","benz","audi"};
String result = STR."\{cars[0]},\{cars[1]},\{cars[2]}";
System.out.println(result);拼接多行数据:
String name = "jordan";
String phone = "13388888888";
String address = "北京";
String json = STR."""
{
"name": "\{name}",
"phone": "\{phone}",
"address": "\{address}"
}
""";
System.out.println(json);自己定义字符串模板,通过StringTemplate来自定义模板
var INTER = StringTemplate.Processor.of((StringTemplate st) -> {
StringBuilder sb = new StringBuilder();
Iterator<String> fragIter = st.fragments().iterator();
for (Object value : st.values()) {
sb.append(fragIter.next());//字符串中的字面量
sb.append(value);
}
sb.append(fragIter.next());
return sb.toString();
});
int x = 10, y = 20;
String s = INTER."\{x} plus \{y} equals \{x + y}";
System.out.println(s);未命名模式和变量(预览)
Java 21 引入了未命名模式和变量
// 未命名变量
for (int i = 0, _ = sideEffect(); i < 10; i++) {
// _ 表示不关心的变量
}
// 在 switch 中使用未命名模式
switch (obj) {
case Point(var x, _) -> System.out.println("X坐标: " + x);
case String _ -> System.out.println("某个字符串");
default -> System.out.println("其他");
}
// 在 catch 中使用
try {
riskyOperation();
} catch (IOException _) {
// 不关心异常对象
System.out.println("IO 异常发生");
}未命名类和实例主方法(预览)
Java 21 简化了简单程序的编写
// 传统写法
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello World");
}
}
// Java 21 简化写法(预览)
void main() {
System.out.println("Hello World");
}
// 或者
public static void main() {
System.out.println("Hello World");
}scoped values(第一次预览)
ThreadLocal的问题
在 Web 应用中,一个请求通常会被多个线程处理,每个线程需要访问自己的数据,使用 ThreadLocal 可以确保数据在每个线程中的独立性。但由于ThreadLocal在设计上的瑕疵,导致下面问题:
- 内存泄漏:在用完ThreadLocal之后若没有调用remove,这样就会出现内存泄漏。
- 增加开销:在具有继承关系的线程中,子线程需要为父线程中ThreadLocal里面的数据分配内存。
- 权限问题:任何可以调用ThreadLocal中get方法的代码都可以随时调用set方法,这样就不易辨别哪些方法是按照什么顺序来更新的共享数据,并且这些方法也都有权限给
ThreadLocal赋值。
随着虚拟线程的到来,内存泄漏问题就不用担心了,由于虚拟线程会很快的终止,此时会自动删除ThreadLocal中的数据,这样就不用调用remove方法了。但虚拟线程的数量通常是多的,试想下上百万个虚拟线程都要拷贝一份ThreadLocal中的变量,这会使内存承受更大的压力。为了解决这些问题,scoped values就出现了。scoped values 是一个隐藏的方法参数,只有方法可以访问scoped values,它可以让两个方法之间传递参数时无需声明形参。
ScopeValue初体验
基本用法
ScopedValue对象用jdk.incubator.concurrent包中的ScopedValue类来表示。使用ScopedValue的第一步是创建ScopedValue对象,通过静态方法newInstance来完成,ScopedValue对象一般声明为static final,每个线程都能访问自己的scope value,与ThreadLocal不同的是,它只会被write 1次且仅在线程绑定的期间内有效。
下一步是指定ScopedValue对象的值和作用域,通过静态方法where来完成。where方法有 3 个参数:
ScopedValue对象ScopedValue对象所绑定的值Runnable或Callable对象,表示ScopedValue对象的作用域
在Runnable或Callable对象执行过程中,其中的代码可以用ScopedValue对象的get方法获取到where方法调用时绑定的值。这个作用域是动态的,取决于Runnable或Callable对象所调用的方法,以及这些方法所调用的其他方法。当Runnable或Callable对象执行完成之后,ScopedValue对象会失去绑定,不能再通过get方法获取值。在当前作用域中,ScopedValue对象的值是不可变的,除非再次调用where方法绑定新的值。这个时候会创建一个嵌套的作用域,新的值仅在嵌套的作用域中有效。使用作用域值有以下几个优势:
- 提高数据安全性:由于作用域值只能在当前范围内访问,因此可以避免数据泄露或被恶意修改。
- 提高数据效率:由于作用域值是不可变的,并且可以在线程之间共享,因此可以减少数据复制或同步的开销。
- 提高代码清晰度:由于作用域值只能在当前范围内访问,因此可以减少参数传递或全局变量的使用。
下面代码模拟了送礼和收礼的场景
public class Test{
private static final ScopedValue<String> GIFT = ScopedValue.newInstance();
public static void main(String[] args) {
Test t = new Test();
t.giveGift();
}
//送礼
public void giveGift() {
/*
* 在对象GIFT中增加字符串手机,当run方法执行时,
* 会拷贝一份副本与当前线程绑定,当run方法结束时解绑。
* 由此可见,这里GIFT中的字符串仅在收礼方法中可以取得。
*/
ScopedValue.where(GIFT, "手机").run(() -> receiveGift());
}
//收礼
public void receiveGift() {
System.out.println(GIFT.get()); // 手机
}
}多线程操作相同的ScopeValue
不同的线程在操作同一个ScopeValue时,相互间不会影响,其本质是利用了Thread类中scopedValueBindings属性进行的线程绑定。
public class Test{
private static final ScopedValue<String> GIFT = ScopedValue.newInstance();
public static void main(String[] args) {
Test t = new Test();
ExecutorService pool = Executors.newCachedThreadPool();
for (int i = 0; i < 10; i++) {
pool.submit(()->{
t.giveGift();
});
}
pool.shutdown();
}
//向ScopedValue中添加当前线程的名字
public void giveGift() {
ScopedValue.where(GIFT, Thread.currentThread().getName()).run(() -> receiveGift());
}
public void receiveGift() {
System.out.println(GIFT.get());
}
}ScopeValue的修改
通过上面的示例可以看到,ScopeValue的值是在第一次使用where的时候就设置好了,该值在当前线程使用的期间是不会被修改的,这样就提高了性能。当然,我们也可以修改ScopeValue中的值,但需要注意,这里的修改会不影响本次方法中读取的值,而是会导致where后run中调用的方法里面的值发生变化。
public class Test{
private static final ScopedValue<String> GIFT = ScopedValue.newInstance();
public static void main(String[] args) {
Test t = new Test();
t.giveGift();
}
public void giveGift() {
ScopedValue.where(GIFT, "500元购物卡").run(() -> receiveMiddleMan());
}
//中间人
public void receiveMiddleMan(){
System.out.println(GIFT.get());//500
//修改GIFT中的值,仅对run中调用的receiveGift方法生效
ScopedValue.where(GIFT, "200元购物卡").run(() -> receiveGift());
System.out.println(GIFT.get());//500
}
public void receiveGift() {
System.out.println(GIFT.get()); //200
}
}所以,从以上分析可以看到,ScopedValue有一定的权限控制:就算在同一个线程中也不能任意修改ScopedValue的值,就算修改了对当前作用域(方法)也是无效的。另外ScopedValue也不需要手动remove,关于这块就需要分析它的实现原理了。这块内容待更新~
Structured Concurrency
该特性主要作用是在使用虚拟线程时,可以使任务和子任务的代码编写起来可读性更强,维护性更高,更加可靠。
import Java.util.concurrent.ExecutionException;
import Java.util.concurrent.StructuredTaskScope;
import Java.util.function.Supplier;
public class Test {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Food f = new Test().handle();
System.out.println(f);
}
Food handle() throws ExecutionException, InterruptedException {
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
Supplier<String> yaoZi = scope.fork(() -> "新鲜大腰子烤好了");// 烤腰子的任务
Supplier<String> drink = scope.fork(() -> "奶茶做好了");// 买饮料的任务
scope.join() // 将2个子任务都加入
.throwIfFailed(); // 失败传播
// 当两个子任务都成功后,最终才能吃上饭
return new Food(yaoZi.get(), drink.get());
}
}
}
record Food(String yaoZi, String drink) {
}孵化器特性
向量 API(第六次孵化器)
Java 21 继续完善向量 API
import jdk.incubator.vector.*;
public class VectorExample {
private static final VectorSpecies<Float> SPECIES = FloatVector.SPECIES_PREFERRED;
// 向量化的矩阵乘法
public static void matrixMultiply(float[][] a, float[][] b, float[][] result) {
int n = a.length;
int m = b[0].length;
int p = a[0].length;
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j += SPECIES.length()) {
FloatVector sum = FloatVector.zero(SPECIES);
for (int k = 0; k < p; k++) {
FloatVector aVec = FloatVector.broadcast(SPECIES, a[i][k]);
FloatVector bVec = FloatVector.fromArray(SPECIES, b[k], j);
sum = aVec.fma(bVec, sum);
}
sum.intoArray(result[i], j);
}
}
}
public static void main(String[] args) {
float[][] a = {{1, 2}, {3, 4}};
float[][] b = {{5, 6}, {7, 8}};
float[][] result = new float[2][2];
matrixMultiply(a, b, result);
System.out.println("矩阵乘法结果:");
for (float[] row : result) {
System.out.println(Arrays.toString(row));
}
}
}