升级JDK11概述
梳理为何JDK 11会是一个极为重要的版本以及如何去理解它。
JDK 10后版本发布规则?
Java 11 已于 2018 年 9 月 25 日正式发布,为了加快的版本迭代、跟进社区反馈,Java 的版本发布周期调整为每六个月一次——即每半年发布一个大版本,每个季度发布一个中间特性版本,并且做出不会跳票的承诺。通过这样的方式,Java 开发团队能够将一些重要特性尽早的合并到 Java Release 版本中,以便快速得到开发者的反馈,避免出现类似 Java 9 发布时的两次延期的情况。
按照官方介绍,新的版本发布周期将会严格按照时间节点,于每年的 3 月和 9 月发布,Java 11 发布的时间节点也正好处于 Java 8 免费更新到期的前夕。与 Java 9 和 Java 10 这两个被称为”功能性的版本”不同,Java 11 仅将提供长期支持服务(LTS, Long-Term-Support),还将作为 Java 平台的默认支持版本,并且会提供技术支持直至 2023 年 9 月,对应的补丁和安全警告等支持将持续至 2026 年。
JDK 8 升级到JDK 11 性能提升多少?
从规划调度引擎 OptaPlanner 项目对 JDK 8和 JDK 11 的性能基准测试进行了对比来看:
如何更好的理解从JDK 8 到 JDK 11 升级中带来的重要特性?
主要从如下三个方面理解,后续的章节主要围绕这三个方面进行:
- 语言新特性
- 新工具和库更新
- JVM优化
语言新特性
JDK9 - 允许在接口中使用私有方法
在如下代码中,buildMessage 是接口 SayHi 中的私有方法,在默认方法 sayHi 中被使用。
public interface SayHi {
private String buildMessage() {
return "Hello";
}
void sayHi(final String message);
default void sayHi() {
sayHi(buildMessage());
}
}JDK10 - 局部变量类型推断
局部变量类型推断是 Java 10 中最值得开发人员注意的新特性,这是 Java 语言开发人员为了简化 Java 应用程序的编写而进行的又一重要改进。
这一新功能将为 Java 增加一些新语法,允许开发人员省略通常不必要的局部变量类型初始化声明。新的语法将减少 Java 代码的冗长度,同时保持对静态类型安全性的承诺。局部变量类型推断主要是向 Java 语法中引入在其他语言(比如 C#、JavaScript)中很常见的保留类型名称 var 。但需要特别注意的是: var 不是一个关键字,而是一个保留字。只要编译器可以推断此种类型,开发人员不再需要专门声明一个局部变量的类型,也就是可以随意定义变量而不必指定变量的类型。这种改进对于链式表达式来说,也会很方便。以下是一个简单的例子:
var list = new ArrayList<String>(); // ArrayList<String>
var stream = list.stream(); // Stream<String>看着是不是有点 JS 的感觉?有没有感觉越来越像 JS 了?虽然变量类型的推断在 Java 中不是一个崭新的概念,但在局部变量中确是很大的一个改进。说到变量类型推断,从 Java 5 中引进泛型,到 Java 7 的 <> 操作符允许不绑定类型而初始化 List,再到 Java 8 中的 Lambda 表达式,再到现在 Java 10 中引入的局部变量类型推断,Java 类型推断正大刀阔斧地向前进步、发展。
而上面这段例子,在以前版本的 Java 语法中初始化列表的写法为:
List<String> list = new ArrayList<String>();
Stream<String> stream = getStream();在运算符允许在没有绑定 ArrayList <> 的类型的情况下初始化列表的写法为:
List<String> list = new LinkedList<>();
Stream<String> stream = getStream();但这种 var 变量类型推断的使用也有局限性,仅局限于具有初始化器的局部变量、增强型 for 循环中的索引变量以及在传统 for 循环中声明的局部变量,而不能用于推断方法的参数类型,不能用于构造函数参数类型推断,不能用于推断方法返回类型,也不能用于字段类型推断,同时还不能用于捕获表达式(或任何其他类型的变量声明)。
不过对于开发者而言,变量类型显式声明会提供更加全面的程序语言信息,对于理解和维护代码有很大的帮助。Java 10 中新引入的局部变量类型推断能够帮助我们快速编写更加简洁的代码,但是局部变量类型推断的保留字 var 的使用势必会引起变量类型可视化缺失,并不是任何时候使用 var 都能容易、清晰的分辨出变量的类型。一旦 var 被广泛运用,开发者在没有 IDE 的支持下阅读代码,势必会对理解程序的执行流程带来一定的困难。所以还是建议尽量显式定义变量类型,在保持代码简洁的同时,也需要兼顾程序的易读性、可维护性。
JDK11 - 用于 Lambda 参数的局部变量语法
在 Lambda 表达式中使用局部变量类型推断是 Java 11 引入的唯一与语言相关的特性
从 Java 10 开始,便引入了局部变量类型推断这一关键特性。类型推断允许使用关键字 var 作为局部变量的类型而不是实际类型,编译器根据分配给变量的值推断出类型。这一改进简化了代码编写、节省了开发者的工作时间,因为不再需要显式声明局部变量的类型,而是可以使用关键字 var,且不会使源代码过于复杂。
可以使用关键字 var 声明局部变量,如下所示:
var s = "Hello Java 11";
System.out.println(s);但是在 Java 10 中,还有下面几个限制:
只能用于局部变量上
声明时必须初始化
不能用作方法参数
不能在 Lambda 表达式中使用
Java 11 与 Java 10 的不同之处在于允许开发者在 Lambda 表达式中使用 var 进行参数声明。乍一看,这一举措似乎有点多余,因为在写代码过程中可以省略 Lambda 参数的类型,并通过类型推断确定它们。但是,添加上类型定义同时使用 @Nonnull 和 @Nullable 等类型注释还是很有用的,既能保持与局部变量的一致写法,也不丢失代码简洁。
Lambda 表达式使用隐式类型定义,它形参的所有类型全部靠推断出来的。隐式类型 Lambda 表达式如下:
(x, y) -> x.process(y)Java 10 为局部变量提供隐式定义写法如下:
var x = new Foo();
for (var x : xs) { ... }
try (var x = ...) { ... } catch ...为了 Lambda 类型表达式中正式参数定义的语法与局部变量定义语法的不一致,且为了保持与其他局部变量用法上的一致性,希望能够使用关键字 var 隐式定义 Lambda 表达式的形参:
(var x, var y) -> x.process(y)于是在 Java 11 中将局部变量和 Lambda 表达式的用法进行了统一,并且可以将注释应用于局部变量和 Lambda 表达式:
@Nonnull var x = new Foo();
(@Nonnull var x, @Nullable var y) -> x.process(y)新工具和库更新
JDK9 - 集合、Stream 和 Optional更新方法
在集合上,Java 9 增加 了 List.of()、Set.of()、Map.of() 和 Map.ofEntries()等工厂方法来创建不可变集合 ,如下 所示。
List.of();
List.of("Hello", "World");
List.of(1, 2, 3);
Set.of();
Set.of("Hello", "World");
Set.of(1, 2, 3);
Map.of();
Map.of("Hello", 1, "World", 2);Stream 中增加了新的方法 ofNullable、dropWhile、takeWhile 和 iterate。在 如下代码 中,流中包含了从 1 到 5 的 元素。断言检查元素是否为奇数。第一个元素 1 被删除,结果流中包含 4 个元素。
@Test
public void testDropWhile() throws Exception {
final long count = Stream.of(1, 2, 3, 4, 5)
.dropWhile(i -> i % 2 != 0)
.count();
assertEquals(4, count);
}Collectors 中增加了新的方法 filtering 和 flatMapping。在 如下代码 中,对于输入的 String 流 ,先通过 flatMapping 把 String 映射成 Integer 流 ,再把所有的 Integer 收集到一个集合中。
@Test
public void testFlatMapping() throws Exception {
final Set<Integer> result = Stream.of("a", "ab", "abc")
.collect(Collectors.flatMapping(v -> v.chars().boxed(),
Collectors.toSet()));
assertEquals(3, result.size());
}Optional 类中新增了 ifPresentOrElse、or 和 stream 等方法。在 如下代码 中,Optiona l 流中包含 3 个 元素,其中只有 2 个有值。在使用 flatMap 之后,结果流中包含了 2 个值。
@Test
public void testStream() throws Exception {
final long count = Stream.of(
Optional.of(1),
Optional.empty(),
Optional.of(2)
).flatMap(Optional::stream)
.count();
assertEquals(2, count);
}JDK9 - 进程 API (Process Handle)
Java 9 增加了 ProcessHandle 接口,可以对原生进程进行管理,尤其适合于管理长时间运行的进程。在使用 ProcessBuilder 来启动一个进程之后,可以通过 Process.toHandle()方法来得到一个 ProcessHandl e 对象的实例。通过 ProcessHandle 可以获取到由 ProcessHandle.Info 表 示的进程的基本信息,如命令行参数、可执行文件路径和启动时间等。ProcessHandle 的 onExit()方法返回一个 CompletableFuture对象,可以在进程结束时执行自定义的动作。 如下代码中给出了进程 API 的使用示例。
final ProcessBuilder processBuilder = new ProcessBuilder("top")
.inheritIO();
final ProcessHandle processHandle = processBuilder.start().toHandle();
processHandle.onExit().whenCompleteAsync((handle, throwable) -> {
if (throwable == null) {
System.out.println(handle.pid());
} else {
throwable.printStackTrace();
}
});JDK9 - 变量句柄 (Var Handle)
变量句柄是一个变量或一组变量的引用,包括静态域,非静态域,数组元素和堆外数据结构中的组成部分等。变量句柄的含义类似于已有的方法句柄。变量句柄由 Java 类 java.lang.invoke.VarHandle 来表示。可以使用类 java.lang.invoke.MethodHandles.Lookup 中的静态工厂方法来创建 VarHandle 对象。通过变量句柄,可以在变量上进行各种操作。这些操作称为访问模式。不同的访问模式尤其在内存排序上的不同语义。目前一共有 31 种 访问模式,而每种访问模式都 在 VarHandle 中 有对应的方法。这些方法可以对变量进行读取、写入、原子更新、数值原子更新和比特位原子操作等。VarHandle 还可以用来访问数组中的单个元素,以及把 byte[]数组 和 ByteBuffer 当成是不同原始类型的数组来访问。
在 如下代码 中,我们创建了访问 HandleTarget 类中的域 count 的变量句柄,并在其上进行读取操作。
public class HandleTarget {
public int count = 1;
}
public class VarHandleTest {
private HandleTarget handleTarget = new HandleTarget();
private VarHandle varHandle;
@Before
public void setUp() throws Exception {
this.handleTarget = new HandleTarget();
this.varHandle = MethodHandles
.lookup()
.findVarHandle(HandleTarget.class, "count", int.class);
}
@Test
public void testGet() throws Exception {
assertEquals(1, this.varHandle.get(this.handleTarget));
assertEquals(1, this.varHandle.getVolatile(this.handleTarget));
assertEquals(1, this.varHandle.getOpaque(this.handleTarget));
assertEquals(1, this.varHandle.getAcquire(this.handleTarget));
}
}JDK9 - I/O 流新特性
类 java.io.InputStream 中增加了新的方法来读取和复制 InputStream 中包含的数据。
readAllBytes:读取 InputStream 中的所有剩余字节。
readNBytes: 从 InputStream 中读取指定数量的字节到数组中。
transferTo:读取 InputStream 中的全部字节并写入到指定的 OutputStream 中 。
public class TestInputStream {
private InputStream inputStream;
private static final String CONTENT = "Hello World";
@Before
public void setUp() throws Exception {
this.inputStream =
TestInputStream.class.getResourceAsStream("/input.txt");
}
@Test
public void testReadAllBytes() throws Exception {
final String content = new String(this.inputStream.readAllBytes());
assertEquals(CONTENT, content);
}
@Test
public void testReadNBytes() throws Exception {
final byte[] data = new byte[5];
this.inputStream.readNBytes(data, 0, 5);
assertEquals("Hello", new String(data));
}
@Test
public void testTransferTo() throws Exception {
final ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
this.inputStream.transferTo(outputStream);
assertEquals(CONTENT, outputStream.toString());
}
}ObjectInputFilter 可以对 ObjectInputStream 中 包含的内容进行检查,来确保其中包含的数据是合法的。可以使用 ObjectInputStream 的方法 setObjectInputFilter 来设置。ObjectInputFilter 在 进行检查时,可以检查如对象图的最大深度、对象引用的最大数量、输入流中的最大字节数和数组的最大长度等限制,也可以对包含的类的名称进行限制。
JDK9 - 改进应用安全性能
Java 9 新增了 4 个 SHA-3 哈希算法,SHA3-224、SHA3-256、SHA3-384 和 SHA3-512。另外也增加了通过 java.security.SecureRandom 生成使用 DRBG 算法的强随机数。如下代码中给出了 SHA-3 哈希算法的使用示例。
import org.apache.commons.codec.binary.Hex;
public class SHA3 {
public static void main(final String[] args) throws NoSuchAlgorithmException {
final MessageDigest instance = MessageDigest.getInstance("SHA3-224");
final byte[] digest = instance.digest("".getBytes());
System.out.println(Hex.encodeHexString(digest));
}
}JDK10 - 根证书认证
自 Java 9 起在 keytool 中加入参数 -cacerts ,可以查看当前 JDK 管理的根证书。而 Java 9 中 cacerts 目录为空,这样就会给开发者带来很多不便。从 Java 10 开始,将会在 JDK 中提供一套默认的 CA 根证书。
作为 JDK 一部分的 cacerts 密钥库旨在包含一组能够用于在各种安全协议的证书链中建立信任的根证书。但是,JDK 源代码中的 cacerts 密钥库至目前为止一直是空的。因此,在 JDK 构建中,默认情况下,关键安全组件(如 TLS)是不起作用的。要解决此问题,用户必须使用一组根证书配置和 cacerts 密钥库下的 CA 根证书。
JDK11 - 标准 HTTP Client 升级
Java 11 对 Java 9 中引入并在 Java 10 中进行了更新的 Http Client API 进行了标准化,在前两个版本中进行孵化的同时,Http Client 几乎被完全重写,并且现在完全支持异步非阻塞。
新版 Java 中,Http Client 的包名由 jdk.incubator.http 改为 java.net.http,该 API 通过 CompleteableFutures 提供非阻塞请求和响应语义,可以联合使用以触发相应的动作,并且 RX Flo w 的概念也在 Java 11 中得到了实现。现在,在用户层请求发布者和响应发布者与底层套接字之间追踪数据流更容易了。这降低了复杂性,并最大程度上提高了 HTTP/1 和 HTTP/2 之间的重用的可能性。
Java 11 中的新 Http Client API,提供了对 HTTP/2 等业界前沿标准的支持,同时也向下兼容 HTTP/1.1,精简而又友好的 API 接口,与主流开源 API(如:Apache HttpClient、Jetty、OkHttp 等)类似甚至拥有更高的性能。与此同时它是 Java 在 Reactive-Stream 方面的第一个生产实践,其中广泛使用了 Java Flow API,终于让 Java 标准 HTTP 类库在扩展能力等方面,满足了现代互联网的需求,是一个难得的现代 Http/2 Client API 标准的实现,Java 工程师终于可以摆脱老旧的 HttpURLConnection 了。下面模拟 Http GET 请求并打印返回内容:
HttpClient client = HttpClient.newHttpClient();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("http://openjdk.java.net/"))
.build();
client.sendAsync(request, BodyHandlers.ofString())
.thenApply(HttpResponse::body)
.thenAccept(System.out::println)
.join();JDK11 - 简化启动单个源代码文件的方法
Java 11 版本中最令人兴奋的功能之一是增强 Java 启动器,使之能够运行单一文件的 Java 源代码。此功能允许使用 Java 解释器直接执行 Java 源代码。源代码在内存中编译,然后由解释器执行。唯一的约束在于所有相关的类必须定义在同一个 Java 文件中。
此功能对于开始学习 Java 并希望尝试简单程序的人特别有用,并且能与 jshell 一起使用,将成为任何初学者学习语言的一个很好的工具集。不仅初学者会受益,专业人员还可以利用这些工具来探索新的语言更改或尝试未知的 API。
如今单文件程序在编写小实用程序时很常见,特别是脚本语言领域。从中开发者可以省去用 Java 编译程序等不必要工作,以及减少新手的入门障碍。在基于 Java 10 的程序实现中可以通过三种方式启动:
作为 * .class 文件
作为 * .jar 文件中的主类
作为模块中的主类
而在最新的 Java 11 中新增了一个启动方式,即可以在源代码中声明类,例如:如果名为 HelloWorld.java 的文件包含一个名为 hello.World 的类,那么该命令:
$ java HelloWorld.java也等同于:
$ javac HelloWorld.java
$ java -cp . hello.WorldJDK11 - 支持 TLS 1.3 协议
Java 11 中包含了传输层安全性(TLS)1.3 规范(RFC 8446)的实现,替换了之前版本中包含的 TLS,包括 TLS 1.2,同时还改进了其他 TLS 功能,例如 OCSP 装订扩展(RFC 6066,RFC 6961),以及会话散列和扩展主密钥扩展(RFC 7627),在安全性和性能方面也做了很多提升。
新版本中包含了 Java 安全套接字扩展(JSSE)提供 SSL,TLS 和 DTLS 协议的框架和 Java 实现。目前,JSSE API 和 JDK 实现支持 SSL 3.0,TLS 1.0,TLS 1.1,TLS 1.2,DTLS 1.0 和 DTLS 1.2。
同时 Java 11 版本中实现的 TLS 1.3,重新定义了以下新标准算法名称:
TLS 协议版本名称:TLSv1.3
SSLContext 算法名称:TLSv1.3
TLS 1.3 的 TLS 密码套件名称:TLS_AES_128_GCM_SHA256,TLS_AES_256_GCM_SHA384
用于 X509KeyManager 的 keyType:RSASSA-PSS
用于 X509TrustManager 的 authType:RSASSA-PSS
还为 TLS 1.3 添加了一个新的安全属性 jdk.tls.keyLimits。当处理了特定算法的指定数据量时,触发握手后,密钥和 IV 更新以导出新密钥。还添加了一个新的系统属性 jdk.tls.server.protocols,用于在 SunJSSE 提供程序的服务器端配置默认启用的协议套件。
之前版本中使用的 KRB5 密码套件实现已从 Java 11 中删除,因为该算法已不再安全。同时注意,TLS 1.3 与以前的版本不直接兼容。
升级到 TLS 1.3 之前,需要考虑如下几个兼容性问题:
TLS 1.3 使用半关闭策略,而 TLS 1.2 以及之前版本使用双工关闭策略,对于依赖于双工关闭策略的应用程序,升级到 TLS 1.3 时可能存在兼容性问题。
TLS 1.3 使用预定义的签名算法进行证书身份验证,但实际场景中应用程序可能会使用不被支持的签名算法。
TLS 1.3 再支持 DSA 签名算法,如果在服务器端配置为仅使用 DSA 证书,则无法升级到 TLS 1.3。
TLS 1.3 支持的加密套件与 TLS 1.2 和早期版本不同,若应用程序硬编码了加密算法单元,则在升级的过程中需要修改相应代码才能升级使用 TLS 1.3。
TLS 1.3 版本的 session 用行为及秘钥更新行为与 1.2 及之前的版本不同,若应用依赖于 TLS 协议的握手过程细节,则需要注意。
JVM优化
JDK9 - 统一 JVM 日志
Java 9 中 ,JVM 有了统一的日志记录系统,可以使用新的命令行选项-Xlog 来控制 JVM 上 所有组件的日志记录。该日志记录系统可以设置输出的日志消息的标签、级别、修饰符和输出目标等。Java 9 移除了在 Java 8 中 被废弃的垃圾回收器配置组合,同时 把 G1 设为默认的垃圾回收器实现。另外,CMS 垃圾回收器已经被声明为废弃。Java 9 也增加了很多可以通过 jcmd 调用的诊断命令。
JDK10 - 统一 GC 接口
在当前的 Java 结构中,组成垃圾回收器(GC)实现的组件分散在代码库的各个部分。尽管这些惯例对于使用 GC 计划的 JDK 开发者来说比较熟悉,但对新的开发人员来说,对于在哪里查找特定 GC 的源代码,或者实现一个新的垃圾收集器常常会感到困惑。更重要的是,随着 Java modules 的出现,我们希望在构建过程中排除不需要的 GC,但是当前 GC 接口的横向结构会给排除、定位问题带来困难。
为解决此问题,需要整合并清理 GC 接口,以便更容易地实现新的 GC,并更好地维护现有的 GC。Java 10 中,hotspot/gc 代码实现方面,引入一个干净的 GC 接口,改进不同 GC 源代码的隔离性,多个 GC 之间共享的实现细节代码应该存在于辅助类中。这种方式提供了足够的灵活性来实现全新 GC 接口,同时允许以混合搭配方式重复使用现有代码,并且能够保持代码更加干净、整洁,便于排查收集器问题。
JDK10 - 并行全垃圾回收器 G1
大家如果接触过 Java 性能调优工作,应该会知道,调优的最终目标是通过参数设置来达到快速、低延时的内存垃圾回收以提高应用吞吐量,尽可能的避免因内存回收不及时而触发的完整 GC(Full GC 会带来应用出现卡顿)。
G1 垃圾回收器是 Java 9 中 Hotspot 的默认垃圾回收器,是以一种低延时的垃圾回收器来设计的,旨在避免进行 Full GC,但是当并发收集无法快速回收内存时,会触发垃圾回收器回退进行 Full GC。之前 Java 版本中的 G1 垃圾回收器执行 GC 时采用的是基于单线程标记扫描压缩算法(mark-sweep-compact)。为了最大限度地减少 Full GC 造成的应用停顿的影响,Java 10 中将为 G1 引入多线程并行 GC,同时会使用与年轻代回收和混合回收相同的并行工作线程数量,从而减少了 Full GC 的发生,以带来更好的性能提升、更大的吞吐量。
Java 10 中将采用并行化 mark-sweep-compact 算法,并使用与年轻代回收和混合回收相同数量的线程。具体并行 GC 线程数量可以通过: -XX:ParallelGCThreads 参数来调节,但这也会影响用于年轻代和混合收集的工作线程数。
JDK11 - Epsilon:低开销垃圾回收器
Epsilon 垃圾回收器的目标是开发一个控制内存分配,但是不执行任何实际的垃圾回收工作。它提供一个完全消极的 GC 实现,分配有限的内存资源,最大限度的降低内存占用和内存吞吐延迟时间。
Java 版本中已经包含了一系列的高度可配置化的 GC 实现。各种不同的垃圾回收器可以面对各种情况。但是有些时候使用一种独特的实现,而不是将其堆积在其他 GC 实现上将会是事情变得更加简单。
下面是 no-op GC 的几个使用场景:
性能测试:什么都不执行的 GC 非常适合用于 GC 的差异性分析。no-op (无操作)GC 可以用于过滤掉 GC 诱发的性能损耗,比如 GC 线程的调度,GC 屏障的消耗,GC 周期的不合适触发,内存位置变化等。此外有些延迟者不是由于 GC 引起的,比如 scheduling hiccups, compiler transition hiccups,所以去除 GC 引发的延迟有助于统计这些延迟。
内存压力测试:在测试 Java 代码时,确定分配内存的阈值有助于设置内存压力常量值。这时 no-op 就很有用,它可以简单地接受一个分配的内存分配上限,当内存超限时就失败。例如:测试需要分配小于 1G 的内存,就使用-Xmx1g 参数来配置 no-op GC,然后当内存耗尽的时候就直接 crash。
VM 接口测试:以 VM 开发视角,有一个简单的 GC 实现,有助于理解 VM-GC 的最小接口实现。它也用于证明 VM-GC 接口的健全性。
极度短暂 job 任务:一个短声明周期的 job 任务可能会依赖快速退出来释放资源,这个时候接收 GC 周期来清理 heap 其实是在浪费时间,因为 heap 会在退出时清理。并且 GC 周期可能会占用一会时间,因为它依赖 heap 上的数据量。 延迟改进:对那些极端延迟敏感的应用,开发者十分清楚内存占用,或者是几乎没有垃圾回收的应用,此时耗时较长的 GC 周期将会是一件坏事。
吞吐改进:即便对那些无需内存分配的工作,选择一个 GC 意味着选择了一系列的 GC 屏障,所有的 OpenJDK GC 都是分代的,所以他们至少会有一个写屏障。避免这些屏障可以带来一点点的吞吐量提升。
Epsilon 垃圾回收器和其他 OpenJDK 的垃圾回收器一样,可以通过参数 -XX:+UseEpsilonGC 开启。
Epsilon 线性分配单个连续内存块。可复用现存 VM 代码中的 TLAB 部分的分配功能。非 TLAB 分配也是同一段代码,因为在此方案中,分配 TLAB 和分配大对象只有一点点的不同。Epsilon 用到的 barrier 是空的(或者说是无操作的)。因为该 GC
执行任何的 GC 周期,不用关系对象图,对象标记,对象复制等。引进一种新的 barrier-set 实现可能是该 GC 对 JVM 最大的变化。
JDK11 - 低开销的 Heap Profiling
Java 11 中提供一种低开销的 Java 堆分配采样方法,能够得到堆分配的 Java 对象信息,并且能够通过 JVMTI 访问堆信息。
引入这个低开销内存分析工具是为了达到如下目的:
足够低的开销,可以默认且一直开启
能通过定义好的程序接口访问
能够对所有堆分配区域进行采样
能给出正在和未被使用的 Java 对象信息
对用户来说,了解它们堆里的内存分布是非常重要的,特别是遇到生产环境中出现的高 CPU、高内存占用率的情况。目前有一些已经开源的工具,允许用户分析应用程序中的堆使用情况,比如:Java Flight Recorder、jmap、YourKit 以及 VisualVM tools.。但是这些工具都有一个明显的不足之处:无法得到对象的分配位置,headp dump 以及 heap histogram 中都没有包含对象分配的具体信息,但是这些信息对于调试内存问题至关重要,因为它能够告诉开发人员他们的代码中发生的高内存分配的确切位置,并根据实际源码来分析具体问题,这也是 Java 11 中引入这种低开销堆分配采样方法的原因。
JDK11 - 可伸缩低延迟垃圾收集器(ZGC)
ZGC 即 Z Garbage Collector(垃圾收集器或垃圾回收器),这应该是 Java 11 中最为瞩目的特性,没有之一。ZGC 是一个可伸缩的、低延迟的垃圾收集器,主要为了满足如下目标进行设计:
GC 停顿时间不超过 10ms
即能处理几百 MB 的小堆,也能处理几个 TB 的大堆
应用吞吐能力不会下降超过 15%(与 G1 回收算法相比)
方便在此基础上引入新的 GC 特性和利用 colord
针以及 Load barriers 优化奠定基础
当前只支持 Linux/x64 位平台 停顿时间在 10ms 以下,10ms 其实是一个很保守的数据,即便是 10ms 这个数据,也是 GC 调优几乎达不到的极值。根据 SPECjbb 2015 的基准测试,128G 的大堆下最大停顿时间才 1.68ms,远低于 10ms,和 G1 算法相比,改进非常明显。
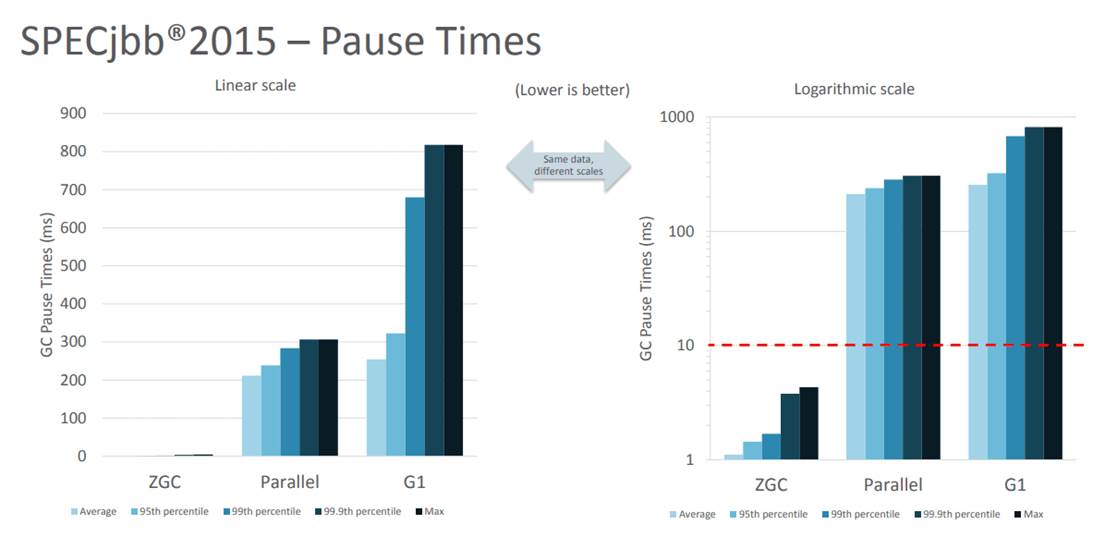
本图片引用自: The Z Garbage Collector – An Introduction
不过目前 ZGC 还处于实验阶段,目前只在 Linux/x64 上可用,如果有足够的需求,将来可能会增加对其他平台的支持。同时作为实验性功能的 ZGC 将不会出现在 JDK 构建中,除非在编译时使用 configure 参数: --with-jvm-features=zgc 显式启用。
在实验阶段,编译完成之后,已经迫不及待的想试试 ZGC,需要配置以下 JVM 参数,才能使用 ZGC,具体启动 ZGC 参数如下:
-XX:+ UnlockExperimentalVMOptions -XX:+ UseZGC -Xmx10g
其中参数: -Xmx 是 ZGC 收集器中最重要的调优选项,大大解决了程序员在 JVM 参数调优上的困扰。ZGC 是一个并发收集器,必须要设置一个最大堆的大小,应用需要多大的堆,主要有下面几个考量:
对象的分配速率,要保证在 GC 的时候,堆中有足够的内存分配新对象。
一般来说,给 ZGC 的内存越多越好,但是也不能浪费内存,所以要找到一个平衡
