介绍
像线性数据结构在查找的时候,⼀般都是使⽤= 或者!= ,在折半查找或者其他范围查询的时候,可能会使⽤< 和> ,理想的时候,我们肯定希望不经过任何的⽐较,直接能定位到某个位置(存储位置),这种在数组中,可以通过索引取得元素。那么,如果我们将需要存储的数据和数组的索引对应起来,并且是⼀对⼀的关系,那不就可以很快定位到元素的位置了么?
只要通过函数f(k) 就能找到k 对应的位置,这个函数f(k) 就是hash 函数。它表示的是⼀种映射关系,但是对不同的值,可能会映射到同⼀个值(同⼀个hash 地址),也就是f(k1) = f(k2) ,这种现象我们称之为冲突或者碰撞。
hash 表定义如下:散列表(Hash table,也叫哈希表),是根据键(Key)⽽直接访问在内存储存位置的数据结构。也就是说,它通过计算⼀个关于键值的函数,将所需查询的数据映射到表中⼀个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做散列表。

⼀般常⽤的hash 函数有:
- 直接定址法:取出关键字或者关键字的某个线性函数的值为哈希函数,⽐如H(key) = key 或者H(key) = a * key + b
- 数字分析法:对于可能出现的数值全部了解,取关键字的若⼲数位组成哈希地址
- 平⽅取中法:取关键字平⽅后的中间⼏位作为哈希地址
- 折叠法:将关键字分割成为位数相同的⼏部分(最后⼀部分的位数可以不同),取这⼏部分的叠加和(舍去进位),作为哈希地址。
- 除留余数法:取关键字被某个不⼤于散列表表⻓m 的数p 除后所得的余数为散列地址。即h ash(k)=k mod p , p< =m 。不仅可以对关键字直接取模,也可在折叠法、平⽅取中法等运算之后取模。对p 的选择很重要,⼀般取素数或m ,若p 选择不好,容易产⽣冲突。
- 随机数法:取关键字的随机函数值作为它的哈希地址。
但是这些⽅法,都⽆法避免哈希冲突,只能有意识的减少。那处理hash 冲突,⼀般有哪些⽅法呢?
解决哈希冲突的三种方法
拉链法、开放地址法、再散列法
拉链法
HashMap,HashSet其实都是采用的拉链法来解决哈希冲突的,就是在每个位桶实现的时候,采用链表的数据结构来去存取发生哈希冲突的输入域的关键字(也就是被哈希函数映射到同一个位桶上的关键字)

但是如果hash 冲突⽐较严重,链表会⽐较⻓,查询的时候,需要遍历后⾯的链表,因此JDK 优化了⼀版,链表的⻓度超过阈值的时候,会变成红⿊树,红⿊树有⼀定的规则去平衡⼦树,避免退化成为链表,影响查询效率。

但是你肯定会想到,如果数组太⼩了,放了⽐较多数据了,怎么办?再放冲突的概率会越来越⾼,其实这个时候会触发⼀个扩容机制,将数组扩容成为 2 倍⼤⼩,重新hash 以前的数据,哈希到不同的数组中。
hash 表的优点是查找速度快,但是如果不断触发重新 hash , 响应速度也会变慢。同时,如果希望范围查询, hash 表不是好的选择。
拉链法的装载因子为n/m(n为输入域的关键字个数,m为位桶的数目)
开放地址法
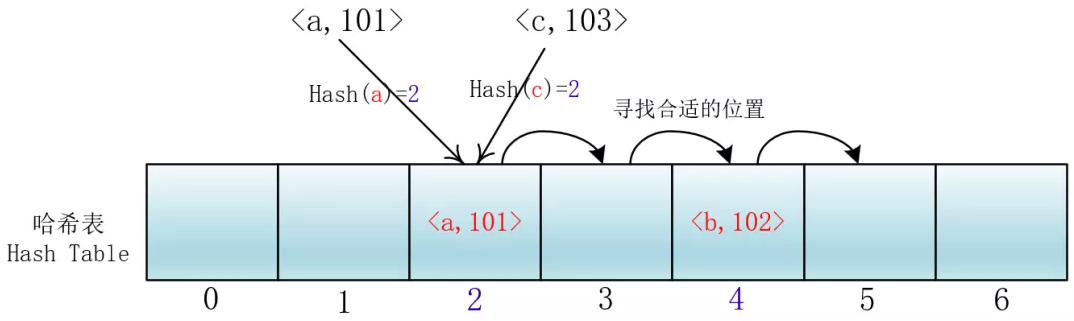
所谓开放地址法就是发生冲突时在散列表(也就是数组里)里去寻找合适的位置存取对应的元素,就是所有输入的元素全部存放在哈希表里。也就是说,位桶的实现是不需要任何的链表来实现的,换句话说,也就是这个哈希表的装载因子不会超过1。
它的实现是在插入一个元素的时候,先通过哈希函数进行判断,若是发生哈希冲突,就以当前地址为基准,根据再寻址的方法(探查序列),去寻找下一个地址,若发生冲突再去寻找,直至找到一个为空的地址为止。
探查序列的方法:
线性探查
平方探测
伪随机探测
线性探查
di =1,2,3,…,m-1;这种方法的特点是:冲突发生时,顺序查看表中下一单元,直到找出一个空单元或查遍全表。
(使用例子:ThreadLocal里面的ThreadLocalMap中的set方法)
private void set(ThreadLocal<?> key, Object value) {
// We don't use a fast path as with get() because it is at
// least as common to use set() to create new entries as
// it is to replace existing ones, in which case, a fast
// path would fail more often than not.
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
//线性探测的关键代码
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
if (k == key) {
e.value = value;
return;
}
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
tab[i] = new Entry(key, value);
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}但是这样会有一个问题,就是随着键值对的增多,会在哈希表里形成连续的键值对。当插入元素时,任意一个落入这个区间的元素都要一直探测到区间末尾,并且最终将自己加入到这个区间内。这样就会导致落在区间内的关键字Key要进行多次探测才能找到合适的位置,并且还会继续增大这个连续区间,使探测时间变得更长,这样的现象被称为“一次聚集(primary clustering)”。
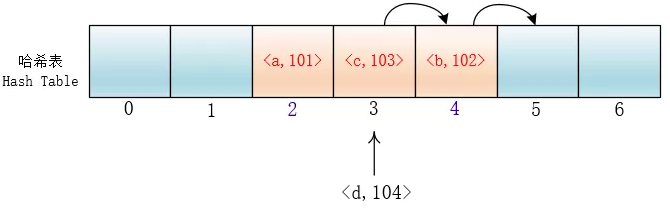

平方探测
在探测时不一个挨着一个地向后探测,可以跳跃着探测,这样就避免了一次聚集。
di=12,-12,22,-22,…,k2,-k2;这种方法的特点是:冲突发生时,在表的左右进行跳跃式探测,比较灵活。虽然平方探测法解决了线性探测法的一次聚集,但是它也有一个小问题,就是关键字key散列到同一位置后探测时的路径是一样的。这样对于许多落在同一位置的关键字而言,越是后面插入的元素,探测的时间就越长。
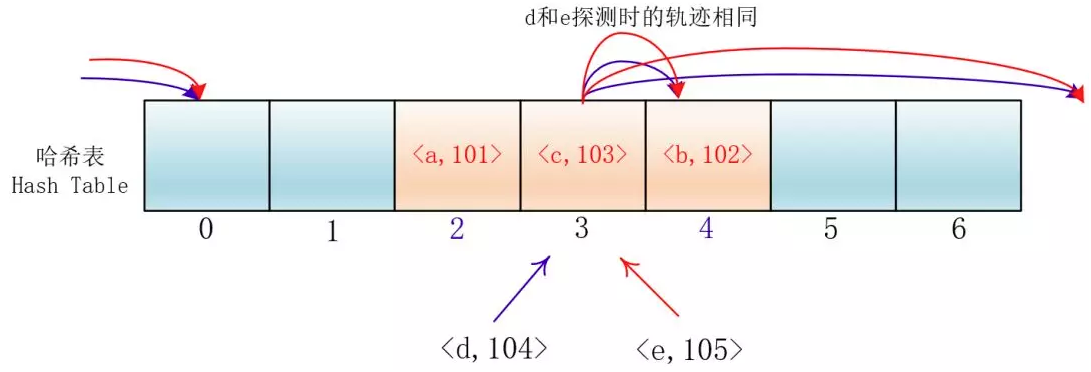
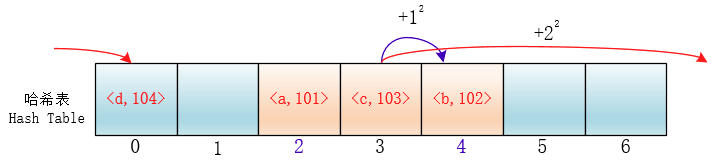
这种现象被称作“二次聚集(secondary clustering)”,其实这个在线性探测法里也有。
伪随机探测
di=伪随机数序列;具体实现时,应建立一个伪随机数发生器,(如i=(i+p) % m),生成一个位随机序列,并给定一个随机数做起点,每次去加上这个伪随机数++就可以了。
再散列法
再散列法其实很简单,就是再使用哈希函数去散列一个输入的时候,输出是同一个位置就再次散列,直至不发生冲突位置
缺点:每次冲突都要重新散列,计算时间增加。一般不用这种方式